 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLaVA-MORE: A Comparative Study of LLMs and Visual Backbones for Enhanced Visual Instruction Tuning
Mar 19, 2025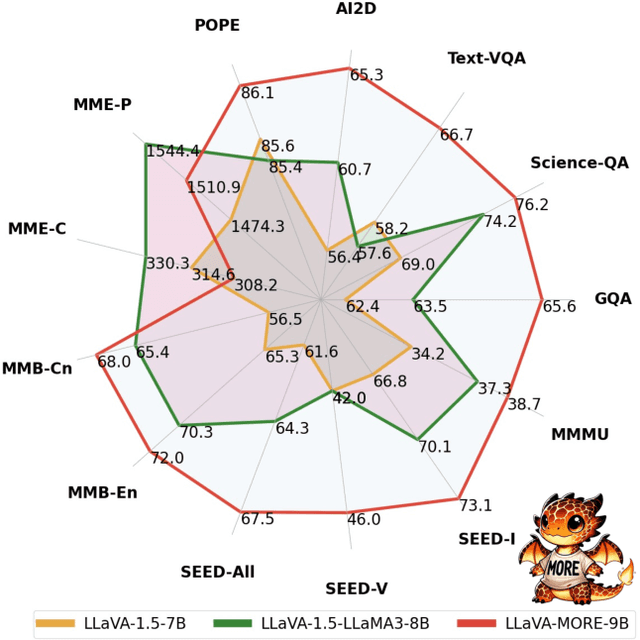
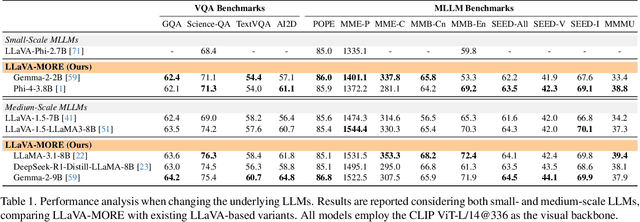
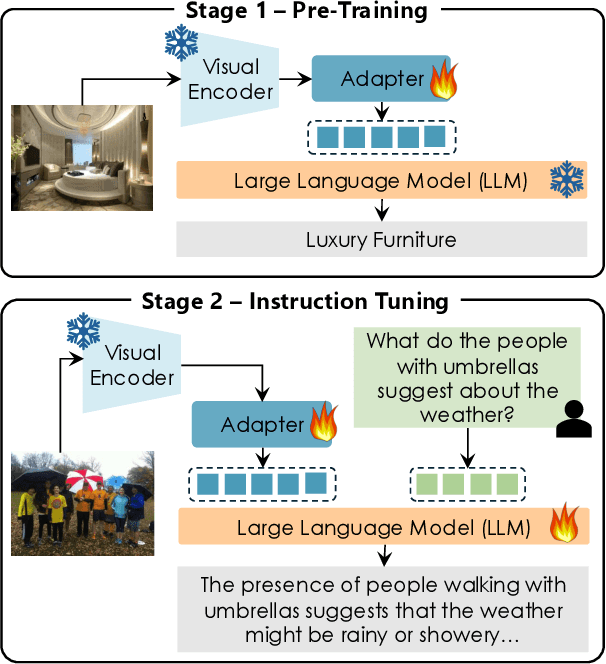
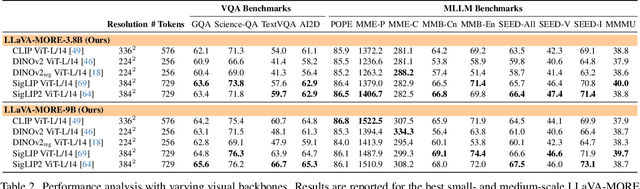
Recent progress in Multimodal Large Language Models (MLLMs) has highlighted the critical roles of both the visual backbone and the underlying language model. While prior work has primarily focused on scaling these components to billions of parameters, the trade-offs between model size, architecture, and performance remain underexplored. Additionally, inconsistencies in training data and evaluation protocols have hindered direct comparisons, making it difficult to derive optimal design choices. In this paper, we introduce LLaVA-MORE, a new family of MLLMs that integrates recent language models with diverse visual backbones. To ensure fair comparisons, we employ a unified training protocol applied consistently across all architectures. Our analysis systematically explores both small- and medium-scale LLMs -- including Phi-4, LLaMA-3.1, and Gemma-2 -- to evaluate multimodal reasoning, generation, and instruction following, while examining the relationship between model size and performance. Beyond evaluating the LLM impact on final results, we conduct a comprehensive study of various visual encoders, ranging from CLIP-based architectures to alternatives such as DINOv2, SigLIP, and SigLIP2. Additional experiments investigate the effects of increased image resolution and variations in pre-training datasets. Overall, our results provide insights into the design of more effective MLLMs, offering a reproducible evaluation framework that facilitates direct comparisons and can guide future model development. Our source code and trained models are publicly available at: https://github.com/aimagelab/LLaVA-MORE.
Causal Graphical Models for Vision-Language Compositional Understanding
Dec 12, 2024



Recent work has empirically shown that Vision-Language Models (VLMs) struggle to fully understand the compositional properties of the human language, usually modeling an image caption as a "bag of words". As a result, they perform poorly on compositional tasks, which require a deeper understanding of the different entities of a sentence (subject, verb, etc.) jointly with their mutual relationships in order to be solved. In this paper, we model the dependency relations among textual and visual tokens using a Causal Graphical Model (CGM), built using a dependency parser, and we train a decoder conditioned by the VLM visual encoder. Differently from standard autoregressive or parallel predictions, our decoder's generative process is partially-ordered following the CGM structure. This structure encourages the decoder to learn only the main causal dependencies in a sentence discarding spurious correlations. Using extensive experiments on five compositional benchmarks, we show that our method significantly outperforms all the state-of-the-art compositional approaches by a large margin, and it also improves over methods trained using much larger datasets.
Personalizing Multimodal Large Language Models for Image Captioning: An Experimental Analysis
Dec 04, 2024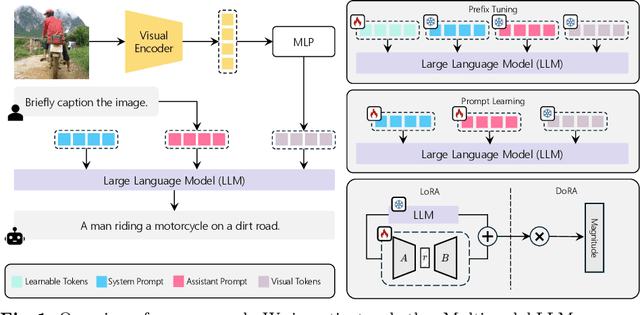
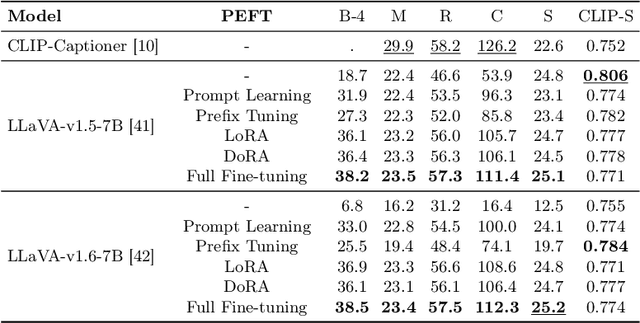
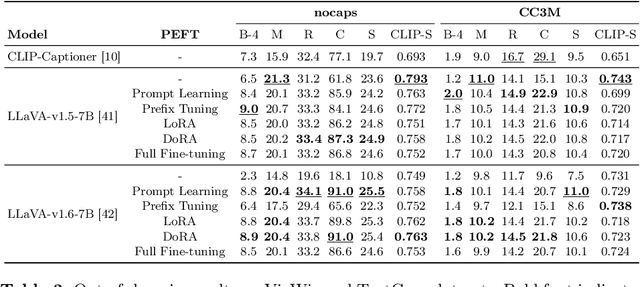
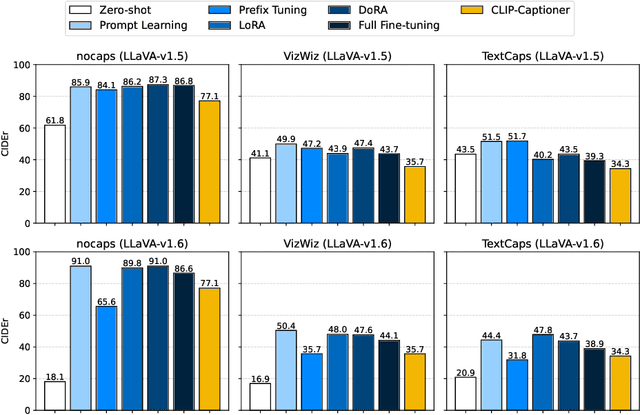
The task of image captioning demands an algorithm to generate natural language descriptions of visual inputs. Recent advancements have seen a convergence between image captioning research and the development of Large Language Models (LLMs) and Multimodal LLMs -- like GPT-4V and Gemini -- which extend the capabilities of text-only LLMs to multiple modalities. This paper investigates whether Multimodal LLMs can supplant traditional image captioning networks by evaluating their performance on various image description benchmarks. We explore both the zero-shot capabilities of these models and their adaptability to different semantic domains through fine-tuning methods, including prompt learning, prefix tuning, and low-rank adaptation. Our results demonstrate that while Multimodal LLMs achieve impressive zero-shot performance, fine-tuning for specific domains while maintaining their generalization capabilities intact remains challenging. We discuss the implications of these findings for future research in image captioning and the development of more adaptable Multimodal LLMs.
Augmenting Multimodal LLMs with Self-Reflective Tokens for Knowledge-based Visual Question Answering
Nov 25, 2024



Multimodal LLMs (MLLMs) are the natural extension of large language models to handle multimodal inputs, combining text and image data. They have recently garnered attention due to their capability to address complex tasks involving both modalities. However, their effectiveness is limited to the knowledge acquired during training, which restricts their practical utility. In this work, we introduce a novel method to enhance the adaptability of MLLMs by integrating external knowledge sources. Our proposed model, Reflective LLaVA (ReflectiVA), utilizes reflective tokens to dynamically determine the need for external knowledge and predict the relevance of information retrieved from an external database. Tokens are trained following a two-stage two-model training recipe. This ultimately enables the MLLM to manage external knowledge while preserving fluency and performance on tasks where external knowledge is not needed. Through our experiments, we demonstrate the efficacy of ReflectiVA for knowledge-based visual question answering, highlighting its superior performance compared to existing methods. Source code and trained models are publicly available at https://github.com/aimagelab/ReflectiVA.
Positive-Augmented Contrastive Learning for Vision-and-Language Evaluation and Training
Oct 09, 2024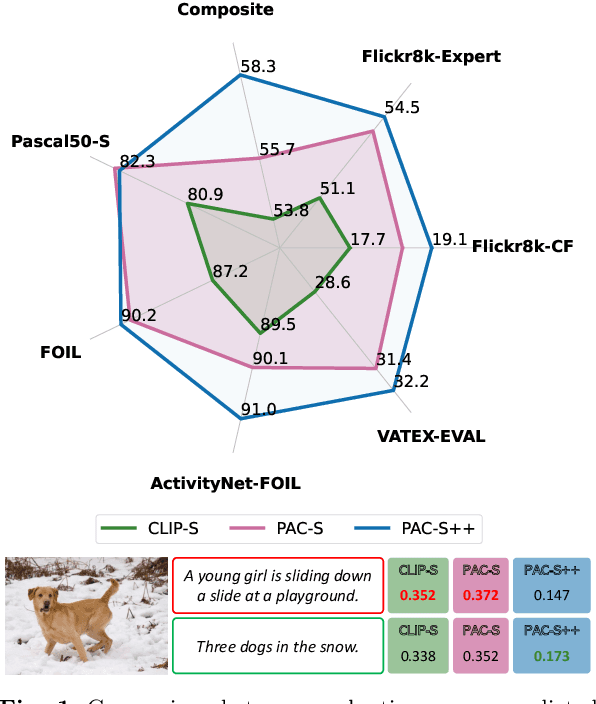
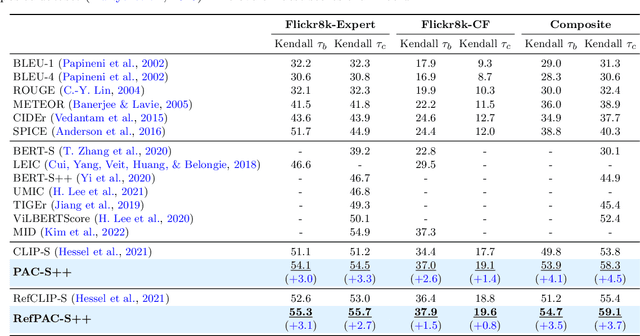
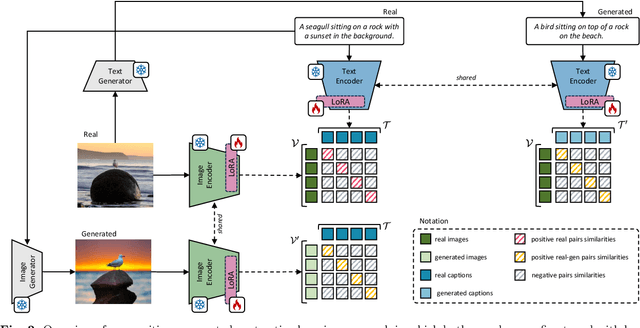
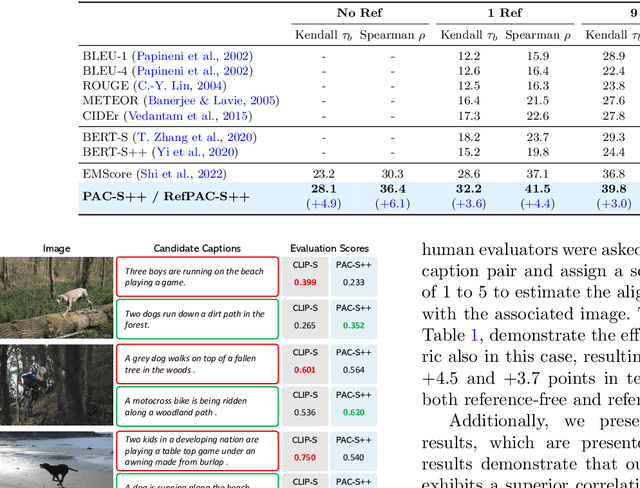
Despite significant advancements in caption generation, existing evaluation metrics often fail to capture the full quality or fine-grained details of captions. This is mainly due to their reliance on non-specific human-written references or noisy pre-training data. Still, finding an effective metric is crucial not only for captions evaluation but also for the generation phase. Metrics can indeed play a key role in the fine-tuning stage of captioning models, ultimately enhancing the quality of the generated captions. In this paper, we propose PAC-S++, a learnable metric that leverages the CLIP model, pre-trained on both web-collected and cleaned data and regularized through additional pairs of generated visual and textual positive samples. Exploiting this stronger and curated pre-training, we also apply PAC-S++ as a reward in the Self-Critical Sequence Training (SCST) stage typically employed to fine-tune captioning models. Extensive experiments on different image and video datasets highlight the effectiveness of PAC-S++ compared to popular metrics for the task, including its sensitivity to object hallucinations. Furthermore, we show that integrating PAC-S++ into the fine-tuning stage of a captioning model results in semantically richer captions with fewer repetitions and grammatical errors. Evaluations on out-of-domain benchmarks further demonstrate the efficacy of our fine-tuning approach in enhancing model capabilities. Source code and trained models are publicly available at: https://github.com/aimagelab/pacscore.
Fluent and Accurate Image Captioning with a Self-Trained Reward Model
Aug 29, 2024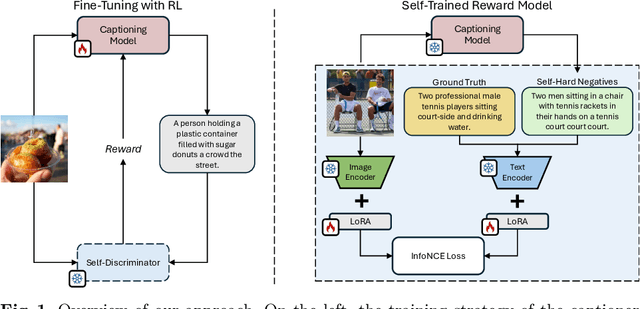


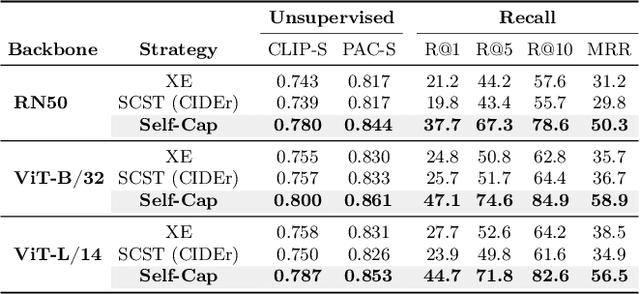
Fine-tuning image captioning models with hand-crafted rewards like the CIDEr metric has been a classical strategy for promoting caption quality at the sequence level. This approach, however, is known to limit descriptiveness and semantic richness and tends to drive the model towards the style of ground-truth sentences, thus losing detail and specificity. On the contrary, recent attempts to employ image-text models like CLIP as reward have led to grammatically incorrect and repetitive captions. In this paper, we propose Self-Cap, a captioning approach that relies on a learnable reward model based on self-generated negatives that can discriminate captions based on their consistency with the image. Specifically, our discriminator is a fine-tuned contrastive image-text model trained to promote caption correctness while avoiding the aberrations that typically happen when training with a CLIP-based reward. To this end, our discriminator directly incorporates negative samples from a frozen captioner, which significantly improves the quality and richness of the generated captions but also reduces the fine-tuning time in comparison to using the CIDEr score as the sole metric for optimization. Experimental results demonstrate the effectiveness of our training strategy on both standard and zero-shot image captioning datasets.
Revisiting Image Captioning Training Paradigm via Direct CLIP-based Optimization
Aug 26, 2024



The conventional training approach for image captioning involves pre-training a network using teacher forcing and subsequent fine-tuning with Self-Critical Sequence Training to maximize hand-crafted captioning metrics. However, when attempting to optimize modern and higher-quality metrics like CLIP-Score and PAC-Score, this training method often encounters instability and fails to acquire the genuine descriptive capabilities needed to produce fluent and informative captions. In this paper, we propose a new training paradigm termed Direct CLIP-Based Optimization (DiCO). Our approach jointly learns and optimizes a reward model that is distilled from a learnable captioning evaluator with high human correlation. This is done by solving a weighted classification problem directly inside the captioner. At the same time, DiCO prevents divergence from the original model, ensuring that fluency is maintained. DiCO not only exhibits improved stability and enhanced quality in the generated captions but also aligns more closely with human preferences compared to existing methods, especially in modern metrics. Additionally, it maintains competitive performance in traditional metrics. Our source code and trained models are publicly available at https://github.com/aimagelab/DiCO.
Wiki-LLaVA: Hierarchical Retrieval-Augmented Generation for Multimodal LLMs
Apr 23, 2024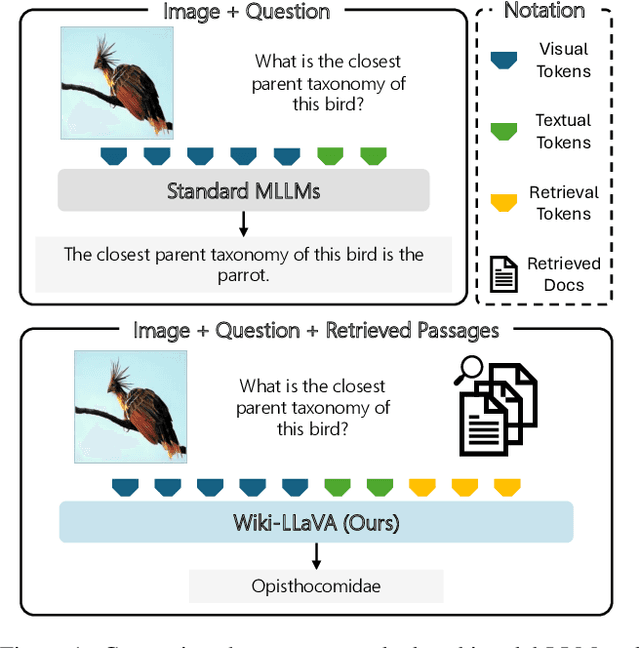
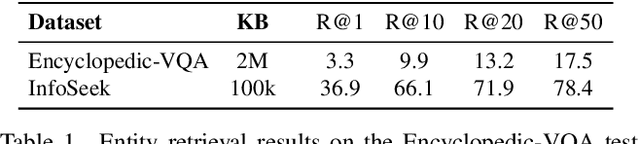


Multimodal LLMs are the natural evolution of LLMs, and enlarge their capabilities so as to work beyond the pure textual modality. As research is being carried out to design novel architectures and vision-and-language adapters, in this paper we concentrate on endowing such models with the capability of answering questions that require external knowledge. Our approach, termed Wiki-LLaVA, aims at integrating an external knowledge source of multimodal documents, which is accessed through a hierarchical retrieval pipeline. Relevant passages, using this approach, are retrieved from the external knowledge source and employed as additional context for the LLM, augmenting the effectiveness and precision of generated dialogues. We conduct extensive experiments on datasets tailored for visual question answering with external data and demonstrate the appropriateness of our approach.
The (R)Evolution of Multimodal Large Language Models: A Survey
Feb 19, 2024Connecting text and visual modalities plays an essential role in generative intelligence. For this reason, inspired by the success of large language models, significant research efforts are being devoted to the development of Multimodal Large Language Models (MLLMs). These models can seamlessly integrate visual and textual modalities, both as input and output, while providing a dialogue-based interface and instruction-following capabilities. In this paper, we provide a comprehensive review of recent visual-based MLLMs, analyzing their architectural choices, multimodal alignment strategies, and training techniques. We also conduct a detailed analysis of these models across a wide range of tasks, including visual grounding, image generation and editing, visual understanding, and domain-specific applications. Additionally, we compile and describe training datasets and evaluation benchmarks, conducting comparisons among existing models in terms of performance and computational requirements. Overall, this survey offers a comprehensive overview of the current state of the art, laying the groundwork for future MLLMs.