 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePositive-Augmented Contrastive Learning for Vision-and-Language Evaluation and Training
Paper and Code
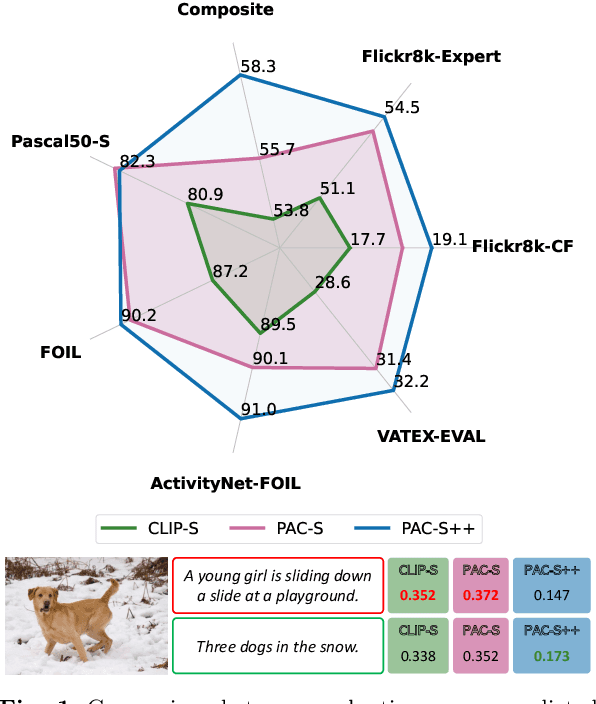
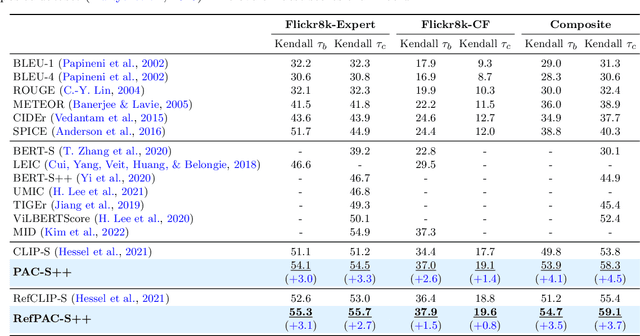
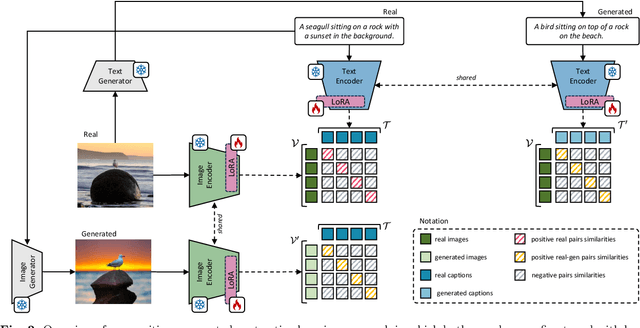
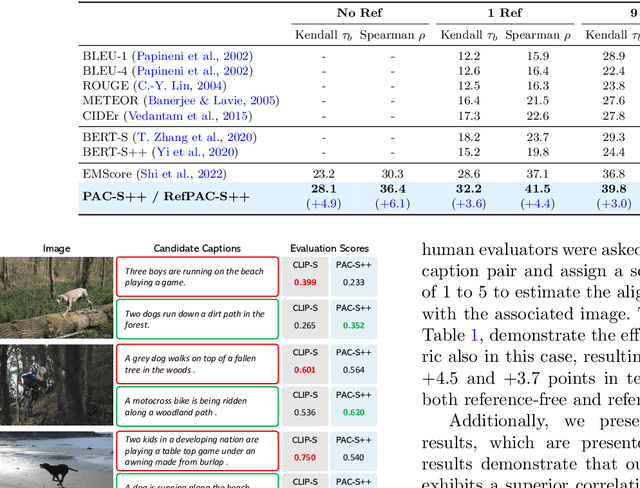
Despite significant advancements in caption generation, existing evaluation metrics often fail to capture the full quality or fine-grained details of captions. This is mainly due to their reliance on non-specific human-written references or noisy pre-training data. Still, finding an effective metric is crucial not only for captions evaluation but also for the generation phase. Metrics can indeed play a key role in the fine-tuning stage of captioning models, ultimately enhancing the quality of the generated captions. In this paper, we propose PAC-S++, a learnable metric that leverages the CLIP model, pre-trained on both web-collected and cleaned data and regularized through additional pairs of generated visual and textual positive samples. Exploiting this stronger and curated pre-training, we also apply PAC-S++ as a reward in the Self-Critical Sequence Training (SCST) stage typically employed to fine-tune captioning models. Extensive experiments on different image and video datasets highlight the effectiveness of PAC-S++ compared to popular metrics for the task, including its sensitivity to object hallucinations. Furthermore, we show that integrating PAC-S++ into the fine-tuning stage of a captioning model results in semantically richer captions with fewer repetitions and grammatical errors. Evaluations on out-of-domain benchmarks further demonstrate the efficacy of our fine-tuning approach in enhancing model capabilities. Source code and trained models are publicly available at: https://github.com/aimagelab/pacscore.