 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTiny Inference-Time Scaling with Latent Verifiers
Mar 25, 2026Inference-time scaling has emerged as an effective way to improve generative models at test time by using a verifier to score and select candidate outputs. A common choice is to employ Multimodal Large Language Models (MLLMs) as verifiers, which can improve performance but introduce substantial inference-time cost. Indeed, diffusion pipelines operate in an autoencoder latent space to reduce computation, yet MLLM verifiers still require decoding candidates to pixel space and re-encoding them into the visual embedding space, leading to redundant and costly operations. In this work, we propose Verifier on Hidden States (VHS), a verifier that operates directly on intermediate hidden representations of Diffusion Transformer (DiT) single-step generators. VHS analyzes generator features without decoding to pixel space, thereby reducing the per-candidate verification cost while improving or matching the performance of MLLM-based competitors. We show that, under tiny inference budgets with only a small number of candidates per prompt, VHS enables more efficient inference-time scaling reducing joint generation-and-verification time by 63.3%, compute FLOPs by 51% and VRAM usage by 14.5% with respect to a standard MLLM verifier, achieving a +2.7% improvement on GenEval at the same inference-time budget.
What Changed? Detecting and Evaluating Instruction-Guided Image Edits with Multimodal Large Language Models
May 26, 2025Instruction-based image editing models offer increased personalization opportunities in generative tasks. However, properly evaluating their results is challenging, and most of the existing metrics lag in terms of alignment with human judgment and explainability. To tackle these issues, we introduce DICE (DIfference Coherence Estimator), a model designed to detect localized differences between the original and the edited image and to assess their relevance to the given modification request. DICE consists of two key components: a difference detector and a coherence estimator, both built on an autoregressive Multimodal Large Language Model (MLLM) and trained using a strategy that leverages self-supervision, distillation from inpainting networks, and full supervision. Through extensive experiments, we evaluate each stage of our pipeline, comparing different MLLMs within the proposed framework. We demonstrate that DICE effectively identifies coherent edits, effectively evaluating images generated by different editing models with a strong correlation with human judgment. We publicly release our source code, models, and data.
Personalizing Multimodal Large Language Models for Image Captioning: An Experimental Analysis
Dec 04, 2024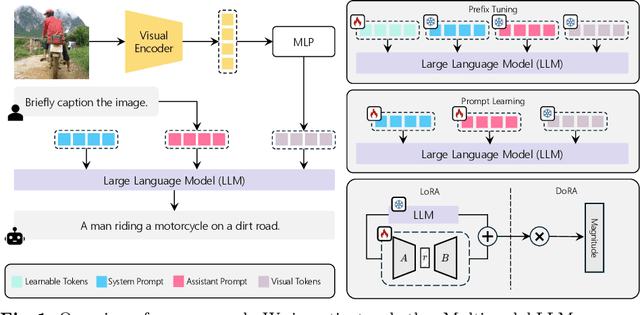
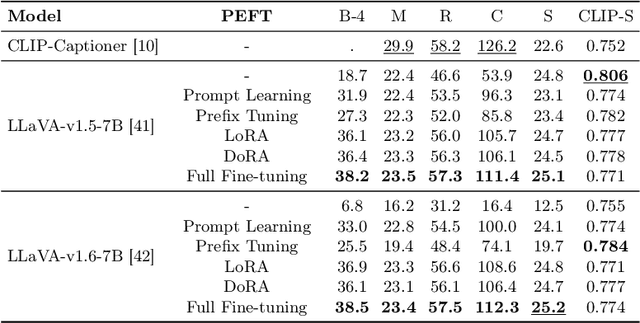
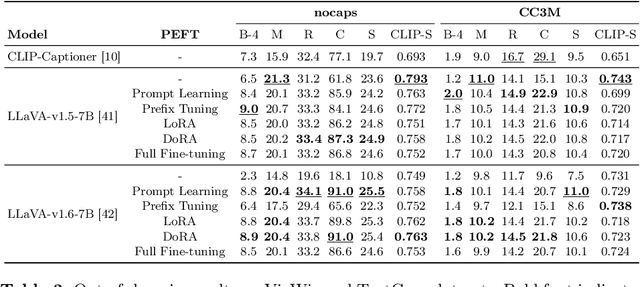
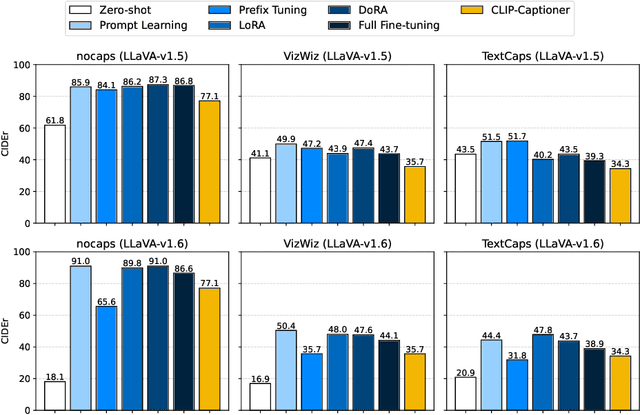
The task of image captioning demands an algorithm to generate natural language descriptions of visual inputs. Recent advancements have seen a convergence between image captioning research and the development of Large Language Models (LLMs) and Multimodal LLMs -- like GPT-4V and Gemini -- which extend the capabilities of text-only LLMs to multiple modalities. This paper investigates whether Multimodal LLMs can supplant traditional image captioning networks by evaluating their performance on various image description benchmarks. We explore both the zero-shot capabilities of these models and their adaptability to different semantic domains through fine-tuning methods, including prompt learning, prefix tuning, and low-rank adaptation. Our results demonstrate that while Multimodal LLMs achieve impressive zero-shot performance, fine-tuning for specific domains while maintaining their generalization capabilities intact remains challenging. We discuss the implications of these findings for future research in image captioning and the development of more adaptable Multimodal LLMs.