 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHallucination Early Detection in Diffusion Models
Apr 22, 2026Text-to-Image generation has seen significant advancements in output realism with the advent of diffusion models. However, diffusion models encounter difficulties when tasked with generating multiple objects, frequently resulting in hallucinations where certain entities are omitted. While existing solutions typically focus on optimizing latent representations within diffusion models, the relevance of the initial generation seed is typically underestimated. While using various seeds in multiple iterations can improve results, this method also significantly increases time and energy costs. To address this challenge, we introduce HEaD+ (Hallucination Early Detection +), a novel approach designed to identify incorrect generations early in the diffusion process. The HEaD+ framework integrates cross-attention maps and textual information with a novel input, the Predicted Final Image. The objective is to assess whether to proceed with the current generation or restart it with a different seed, thereby exploring multiple-generation seeds while conserving time. HEaD+ is trained on the newly created InsideGen dataset of 45,000 generated images, each containing prompts with up to seven objects. Our findings demonstrate a 6-8% increase in the likelihood of achieving a complete generation (i.e., an image accurately representing all specified subjects) with four objects when applying HEaD+ alongside existing models. Additionally, HEaD+ reduces generation times by up to 32% when aiming for a complete image, enhancing the efficiency of generating complete and accurate object representations relative to leading models. Moreover, we propose an integrated localization module that predicts object centroid positions and verifies pairwise spatial relations (if requested by the users) at an intermediate timestep, gating generation together with object presence to further improve relation-consistent outcomes.
* 21 pages, 6 figures, 4 tables. Published in International Journal of Computer Vision (IJCV)
What Changed? Detecting and Evaluating Instruction-Guided Image Edits with Multimodal Large Language Models
May 26, 2025Instruction-based image editing models offer increased personalization opportunities in generative tasks. However, properly evaluating their results is challenging, and most of the existing metrics lag in terms of alignment with human judgment and explainability. To tackle these issues, we introduce DICE (DIfference Coherence Estimator), a model designed to detect localized differences between the original and the edited image and to assess their relevance to the given modification request. DICE consists of two key components: a difference detector and a coherence estimator, both built on an autoregressive Multimodal Large Language Model (MLLM) and trained using a strategy that leverages self-supervision, distillation from inpainting networks, and full supervision. Through extensive experiments, we evaluate each stage of our pipeline, comparing different MLLMs within the proposed framework. We demonstrate that DICE effectively identifies coherent edits, effectively evaluating images generated by different editing models with a strong correlation with human judgment. We publicly release our source code, models, and data.
Optimizing Resource Consumption in Diffusion Models through Hallucination Early Detection
Sep 16, 2024
Diffusion models have significantly advanced generative AI, but they encounter difficulties when generating complex combinations of multiple objects. As the final result heavily depends on the initial seed, accurately ensuring the desired output can require multiple iterations of the generation process. This repetition not only leads to a waste of time but also increases energy consumption, echoing the challenges of efficiency and accuracy in complex generative tasks. To tackle this issue, we introduce HEaD (Hallucination Early Detection), a new paradigm designed to swiftly detect incorrect generations at the beginning of the diffusion process. The HEaD pipeline combines cross-attention maps with a new indicator, the Predicted Final Image, to forecast the final outcome by leveraging the information available at early stages of the generation process. We demonstrate that using HEaD saves computational resources and accelerates the generation process to get a complete image, i.e. an image where all requested objects are accurately depicted. Our findings reveal that HEaD can save up to 12% of the generation time on a two objects scenario and underscore the importance of early detection mechanisms in generative models.
Let's ViCE! Mimicking Human Cognitive Behavior in Image Generation Evaluation
Jul 19, 2023
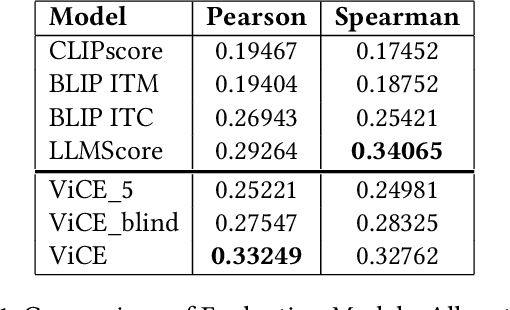
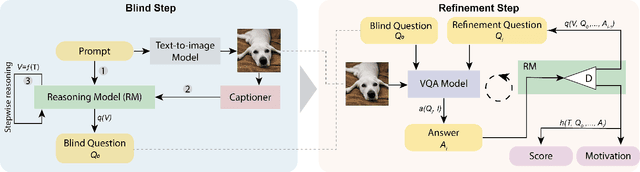
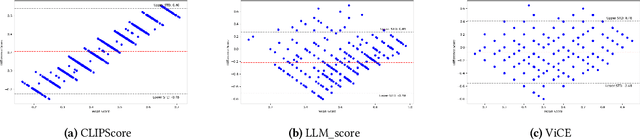
Research in Image Generation has recently made significant progress, particularly boosted by the introduction of Vision-Language models which are able to produce high-quality visual content based on textual inputs. Despite ongoing advancements in terms of generation quality and realism, no methodical frameworks have been defined yet to quantitatively measure the quality of the generated content and the adherence with the prompted requests: so far, only human-based evaluations have been adopted for quality satisfaction and for comparing different generative methods. We introduce a novel automated method for Visual Concept Evaluation (ViCE), i.e. to assess consistency between a generated/edited image and the corresponding prompt/instructions, with a process inspired by the human cognitive behaviour. ViCE combines the strengths of Large Language Models (LLMs) and Visual Question Answering (VQA) into a unified pipeline, aiming to replicate the human cognitive process in quality assessment. This method outlines visual concepts, formulates image-specific verification questions, utilizes the Q&A system to investigate the image, and scores the combined outcome. Although this brave new hypothesis of mimicking humans in the image evaluation process is in its preliminary assessment stage, results are promising and open the door to a new form of automatic evaluation which could have significant impact as the image generation or the image target editing tasks become more and more sophisticated.