 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeeing Beyond Words: Self-Supervised Visual Learning for Multimodal Large Language Models
Dec 17, 2025Multimodal Large Language Models (MLLMs) have recently demonstrated impressive capabilities in connecting vision and language, yet their proficiency in fundamental visual reasoning tasks remains limited. This limitation can be attributed to the fact that MLLMs learn visual understanding primarily from textual descriptions, which constitute a subjective and inherently incomplete supervisory signal. Furthermore, the modest scale of multimodal instruction tuning compared to massive text-only pre-training leads MLLMs to overfit language priors while overlooking visual details. To address these issues, we introduce JARVIS, a JEPA-inspired framework for self-supervised visual enhancement in MLLMs. Specifically, we integrate the I-JEPA learning paradigm into the standard vision-language alignment pipeline of MLLMs training. Our approach leverages frozen vision foundation models as context and target encoders, while training the predictor, implemented as the early layers of an LLM, to learn structural and semantic regularities from images without relying exclusively on language supervision. Extensive experiments on standard MLLM benchmarks show that JARVIS consistently improves performance on vision-centric benchmarks across different LLM families, without degrading multimodal reasoning abilities. Our source code is publicly available at: https://github.com/aimagelab/JARVIS.
Recurrence Meets Transformers for Universal Multimodal Retrieval
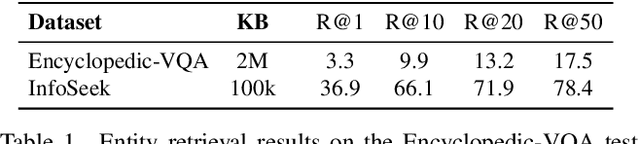
Sep 10, 2025With the rapid advancement of multimodal retrieval and its application in LLMs and multimodal LLMs, increasingly complex retrieval tasks have emerged. Existing methods predominantly rely on task-specific fine-tuning of vision-language models and are limited to single-modality queries or documents. In this paper, we propose ReT-2, a unified retrieval model that supports multimodal queries, composed of both images and text, and searches across multimodal document collections where text and images coexist. ReT-2 leverages multi-layer representations and a recurrent Transformer architecture with LSTM-inspired gating mechanisms to dynamically integrate information across layers and modalities, capturing fine-grained visual and textual details. We evaluate ReT-2 on the challenging M2KR and M-BEIR benchmarks across different retrieval configurations. Results demonstrate that ReT-2 consistently achieves state-of-the-art performance across diverse settings, while offering faster inference and reduced memory usage compared to prior approaches. When integrated into retrieval-augmented generation pipelines, ReT-2 also improves downstream performance on Encyclopedic-VQA and InfoSeek datasets. Our source code and trained models are publicly available at: https://github.com/aimagelab/ReT-2
LLaVA-MORE: A Comparative Study of LLMs and Visual Backbones for Enhanced Visual Instruction Tuning
Mar 19, 2025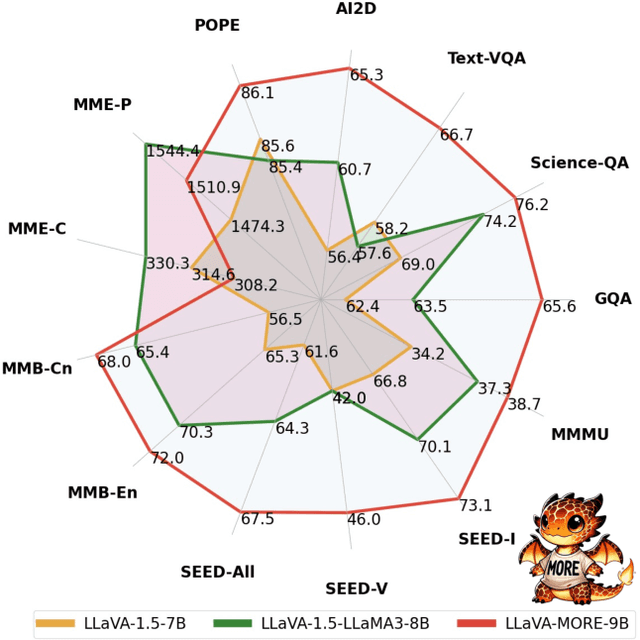
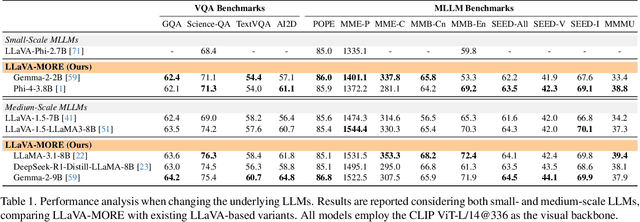
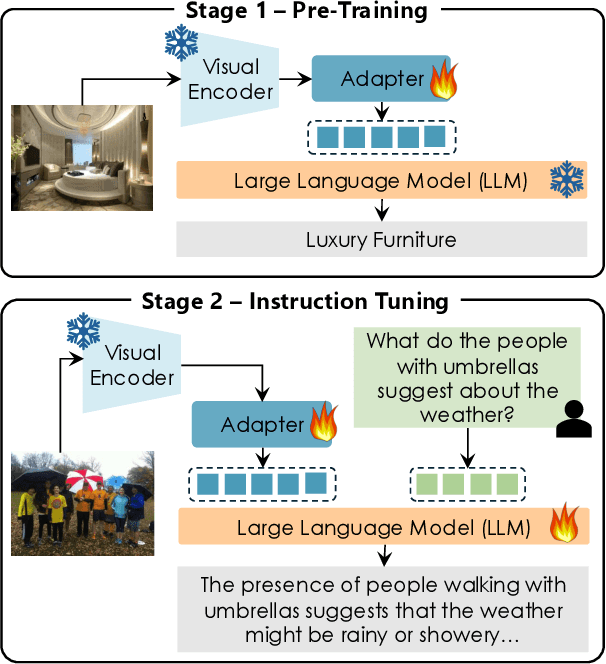
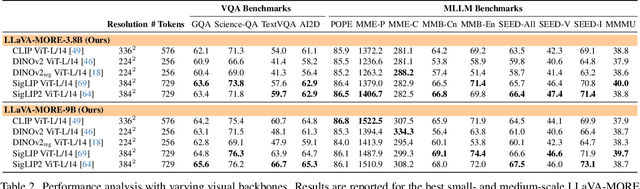
Recent progress in Multimodal Large Language Models (MLLMs) has highlighted the critical roles of both the visual backbone and the underlying language model. While prior work has primarily focused on scaling these components to billions of parameters, the trade-offs between model size, architecture, and performance remain underexplored. Additionally, inconsistencies in training data and evaluation protocols have hindered direct comparisons, making it difficult to derive optimal design choices. In this paper, we introduce LLaVA-MORE, a new family of MLLMs that integrates recent language models with diverse visual backbones. To ensure fair comparisons, we employ a unified training protocol applied consistently across all architectures. Our analysis systematically explores both small- and medium-scale LLMs -- including Phi-4, LLaMA-3.1, and Gemma-2 -- to evaluate multimodal reasoning, generation, and instruction following, while examining the relationship between model size and performance. Beyond evaluating the LLM impact on final results, we conduct a comprehensive study of various visual encoders, ranging from CLIP-based architectures to alternatives such as DINOv2, SigLIP, and SigLIP2. Additional experiments investigate the effects of increased image resolution and variations in pre-training datasets. Overall, our results provide insights into the design of more effective MLLMs, offering a reproducible evaluation framework that facilitates direct comparisons and can guide future model development. Our source code and trained models are publicly available at: https://github.com/aimagelab/LLaVA-MORE.
Recurrence-Enhanced Vision-and-Language Transformers for Robust Multimodal Document Retrieval
Mar 03, 2025Cross-modal retrieval is gaining increasing efficacy and interest from the research community, thanks to large-scale training, novel architectural and learning designs, and its application in LLMs and multimodal LLMs. In this paper, we move a step forward and design an approach that allows for multimodal queries, composed of both an image and a text, and can search within collections of multimodal documents, where images and text are interleaved. Our model, ReT, employs multi-level representations extracted from different layers of both visual and textual backbones, both at the query and document side. To allow for multi-level and cross-modal understanding and feature extraction, ReT employs a novel Transformer-based recurrent cell that integrates both textual and visual features at different layers, and leverages sigmoidal gates inspired by the classical design of LSTMs. Extensive experiments on M2KR and M-BEIR benchmarks show that ReT achieves state-of-the-art performance across diverse settings. Our source code and trained models are publicly available at https://github.com/aimagelab/ReT.
Revisiting Image Captioning Training Paradigm via Direct CLIP-based Optimization
Aug 26, 2024



The conventional training approach for image captioning involves pre-training a network using teacher forcing and subsequent fine-tuning with Self-Critical Sequence Training to maximize hand-crafted captioning metrics. However, when attempting to optimize modern and higher-quality metrics like CLIP-Score and PAC-Score, this training method often encounters instability and fails to acquire the genuine descriptive capabilities needed to produce fluent and informative captions. In this paper, we propose a new training paradigm termed Direct CLIP-Based Optimization (DiCO). Our approach jointly learns and optimizes a reward model that is distilled from a learnable captioning evaluator with high human correlation. This is done by solving a weighted classification problem directly inside the captioner. At the same time, DiCO prevents divergence from the original model, ensuring that fluency is maintained. DiCO not only exhibits improved stability and enhanced quality in the generated captions but also aligns more closely with human preferences compared to existing methods, especially in modern metrics. Additionally, it maintains competitive performance in traditional metrics. Our source code and trained models are publicly available at https://github.com/aimagelab/DiCO.
Wiki-LLaVA: Hierarchical Retrieval-Augmented Generation for Multimodal LLMs
Apr 23, 2024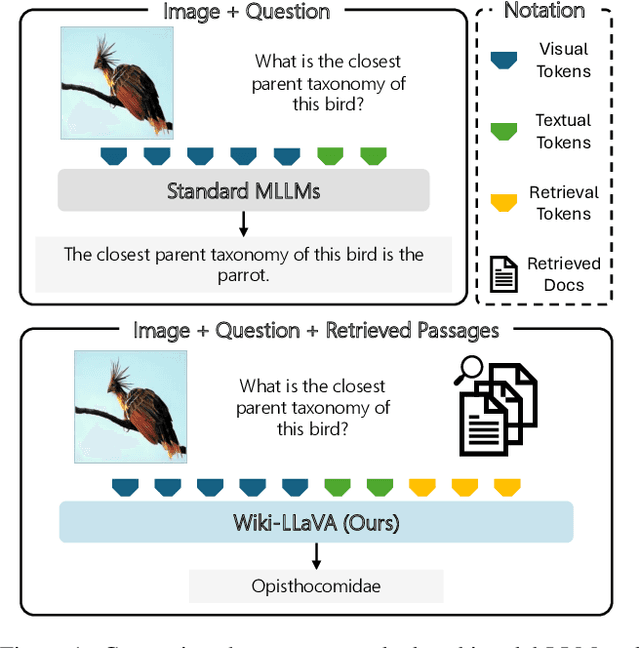


Multimodal LLMs are the natural evolution of LLMs, and enlarge their capabilities so as to work beyond the pure textual modality. As research is being carried out to design novel architectures and vision-and-language adapters, in this paper we concentrate on endowing such models with the capability of answering questions that require external knowledge. Our approach, termed Wiki-LLaVA, aims at integrating an external knowledge source of multimodal documents, which is accessed through a hierarchical retrieval pipeline. Relevant passages, using this approach, are retrieved from the external knowledge source and employed as additional context for the LLM, augmenting the effectiveness and precision of generated dialogues. We conduct extensive experiments on datasets tailored for visual question answering with external data and demonstrate the appropriateness of our approach.
The (R)Evolution of Multimodal Large Language Models: A Survey
Feb 19, 2024Connecting text and visual modalities plays an essential role in generative intelligence. For this reason, inspired by the success of large language models, significant research efforts are being devoted to the development of Multimodal Large Language Models (MLLMs). These models can seamlessly integrate visual and textual modalities, both as input and output, while providing a dialogue-based interface and instruction-following capabilities. In this paper, we provide a comprehensive review of recent visual-based MLLMs, analyzing their architectural choices, multimodal alignment strategies, and training techniques. We also conduct a detailed analysis of these models across a wide range of tasks, including visual grounding, image generation and editing, visual understanding, and domain-specific applications. Additionally, we compile and describe training datasets and evaluation benchmarks, conducting comparisons among existing models in terms of performance and computational requirements. Overall, this survey offers a comprehensive overview of the current state of the art, laying the groundwork for future MLLMs.