 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWith a Little Help from your own Past: Prototypical Memory Networks for Image Captioning
Aug 23, 2023Image captioning, like many tasks involving vision and language, currently relies on Transformer-based architectures for extracting the semantics in an image and translating it into linguistically coherent descriptions. Although successful, the attention operator only considers a weighted summation of projections of the current input sample, therefore ignoring the relevant semantic information which can come from the joint observation of other samples. In this paper, we devise a network which can perform attention over activations obtained while processing other training samples, through a prototypical memory model. Our memory models the distribution of past keys and values through the definition of prototype vectors which are both discriminative and compact. Experimentally, we assess the performance of the proposed model on the COCO dataset, in comparison with carefully designed baselines and state-of-the-art approaches, and by investigating the role of each of the proposed components. We demonstrate that our proposal can increase the performance of an encoder-decoder Transformer by 3.7 CIDEr points both when training in cross-entropy only and when fine-tuning with self-critical sequence training. Source code and trained models are available at: https://github.com/aimagelab/PMA-Net.
Positive-Augmented Constrastive Learning for Image and Video Captioning Evaluation
Mar 21, 2023The CLIP model has been recently proven to be very effective for a variety of cross-modal tasks, including the evaluation of captions generated from vision-and-language architectures. In this paper, we propose a new recipe for a contrastive-based evaluation metric for image captioning, namely Positive-Augmented Contrastive learning Score (PAC-S), that in a novel way unifies the learning of a contrastive visual-semantic space with the addition of generated images and text on curated data. Experiments spanning several datasets demonstrate that our new metric achieves the highest correlation with human judgments on both images and videos, outperforming existing reference-based metrics like CIDEr and SPICE and reference-free metrics like CLIP-Score. Finally, we test the system-level correlation of the proposed metric when considering popular image captioning approaches, and assess the impact of employing different cross-modal features. Our source code and trained models are publicly available at: https://github.com/aimagelab/pacscore.
CaMEL: Mean Teacher Learning for Image Captioning
Feb 21, 2022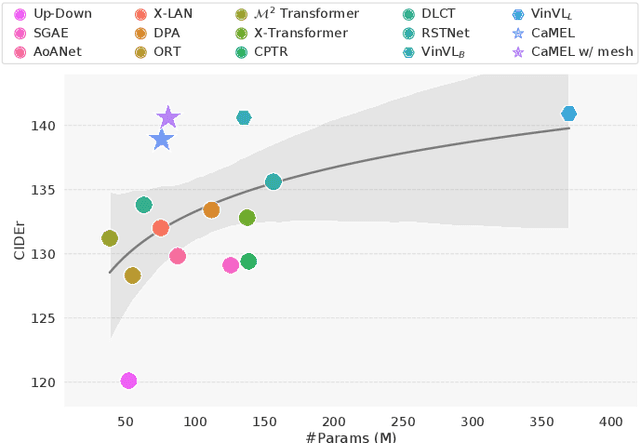
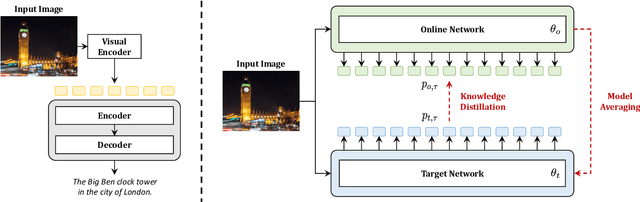

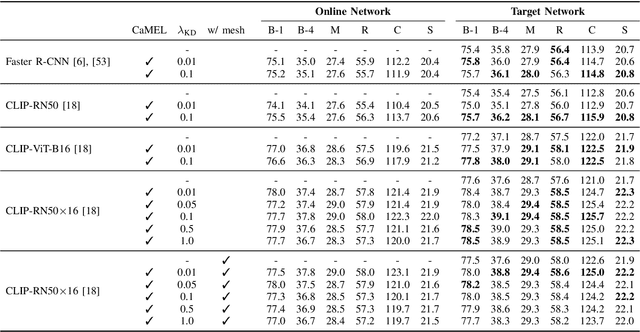
Describing images in natural language is a fundamental step towards the automatic modeling of connections between the visual and textual modalities. In this paper we present CaMEL, a novel Transformer-based architecture for image captioning. Our proposed approach leverages the interaction of two interconnected language models that learn from each other during the training phase. The interplay between the two language models follows a mean teacher learning paradigm with knowledge distillation. Experimentally, we assess the effectiveness of the proposed solution on the COCO dataset and in conjunction with different visual feature extractors. When comparing with existing proposals, we demonstrate that our model provides state-of-the-art caption quality with a significantly reduced number of parameters. According to the CIDEr metric, we obtain a new state of the art on COCO when training without using external data. The source code and trained models are publicly available at: https://github.com/aimagelab/camel.