 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeALADIN: Distilling Fine-grained Alignment Scores for Efficient Image-Text Matching and Retrieval
Jul 29, 2022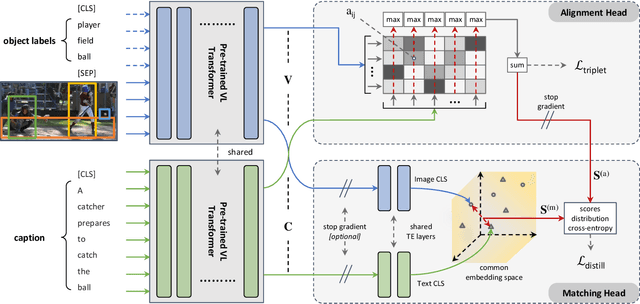
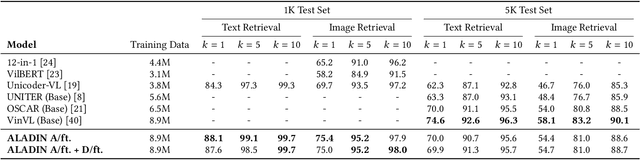
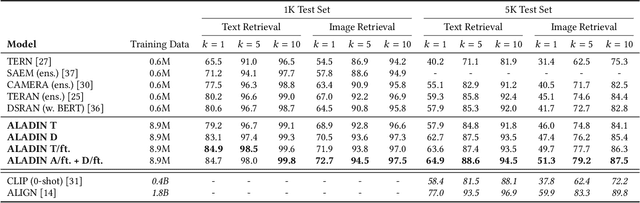
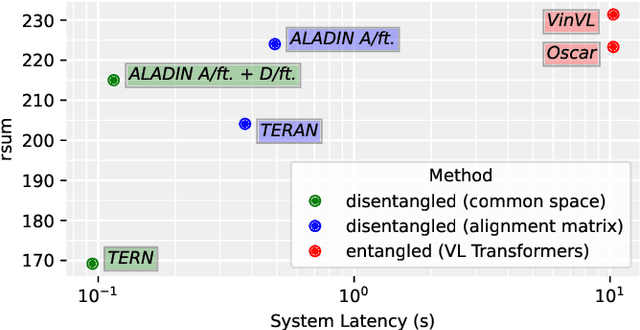
Image-text matching is gaining a leading role among tasks involving the joint understanding of vision and language. In literature, this task is often used as a pre-training objective to forge architectures able to jointly deal with images and texts. Nonetheless, it has a direct downstream application: cross-modal retrieval, which consists in finding images related to a given query text or vice-versa. Solving this task is of critical importance in cross-modal search engines. Many recent methods proposed effective solutions to the image-text matching problem, mostly using recent large vision-language (VL) Transformer networks. However, these models are often computationally expensive, especially at inference time. This prevents their adoption in large-scale cross-modal retrieval scenarios, where results should be provided to the user almost instantaneously. In this paper, we propose to fill in the gap between effectiveness and efficiency by proposing an ALign And DIstill Network (ALADIN). ALADIN first produces high-effective scores by aligning at fine-grained level images and texts. Then, it learns a shared embedding space - where an efficient kNN search can be performed - by distilling the relevance scores obtained from the fine-grained alignments. We obtained remarkable results on MS-COCO, showing that our method can compete with state-of-the-art VL Transformers while being almost 90 times faster. The code for reproducing our results is available at https://github.com/mesnico/ALADIN.
CaMEL: Mean Teacher Learning for Image Captioning
Feb 21, 2022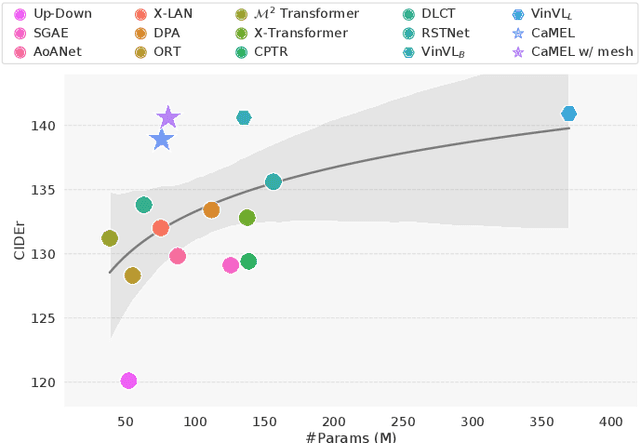
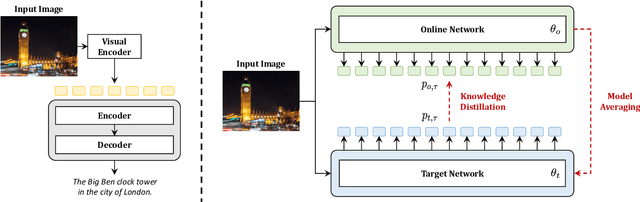

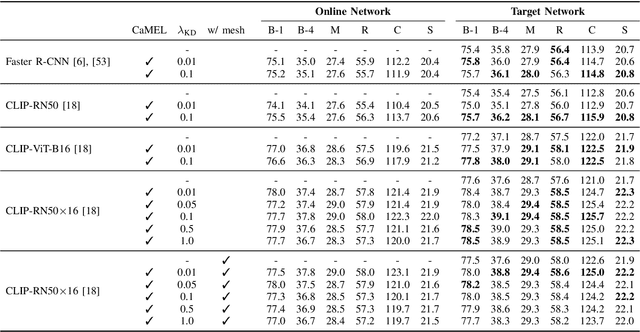
Describing images in natural language is a fundamental step towards the automatic modeling of connections between the visual and textual modalities. In this paper we present CaMEL, a novel Transformer-based architecture for image captioning. Our proposed approach leverages the interaction of two interconnected language models that learn from each other during the training phase. The interplay between the two language models follows a mean teacher learning paradigm with knowledge distillation. Experimentally, we assess the effectiveness of the proposed solution on the COCO dataset and in conjunction with different visual feature extractors. When comparing with existing proposals, we demonstrate that our model provides state-of-the-art caption quality with a significantly reduced number of parameters. According to the CIDEr metric, we obtain a new state of the art on COCO when training without using external data. The source code and trained models are publicly available at: https://github.com/aimagelab/camel.
From Show to Tell: A Survey on Image Captioning
Jul 30, 2021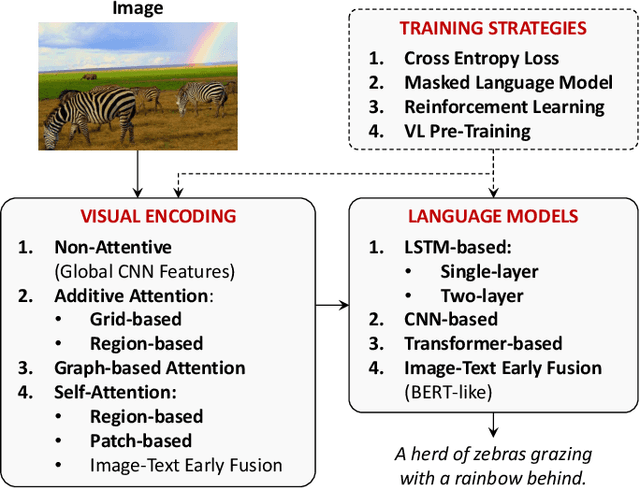
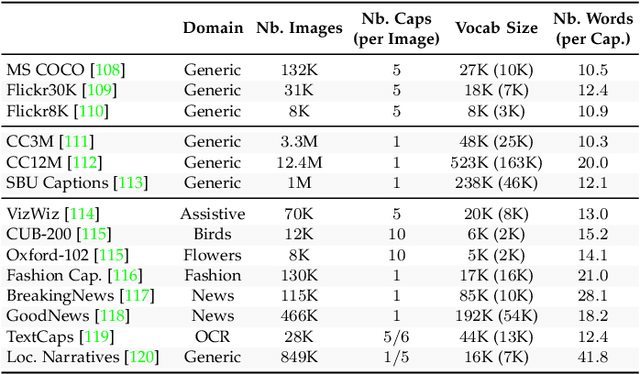
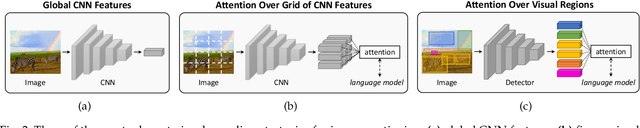
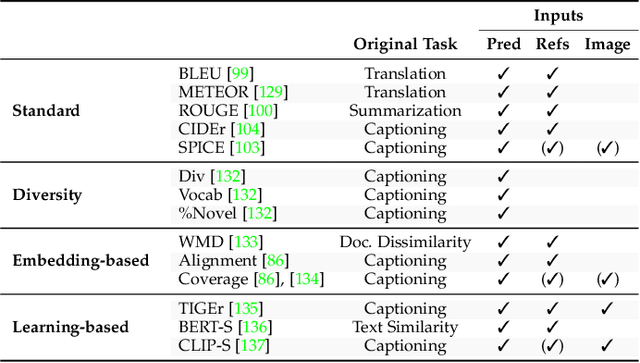
Connecting Vision and Language plays an essential role in Generative Intelligence. For this reason, large research efforts have been devoted to image captioning, i.e. describing images with syntactically and semantically meaningful sentences. Starting from 2015 the task has generally been addressed with pipelines composed of a visual encoder and a language model for text generation. During these years, both components have evolved considerably through the exploitation of object regions, attributes, the introduction of multi-modal connections, fully-attentive approaches, and BERT-like early-fusion strategies. However, regardless of the impressive results, research in image captioning has not reached a conclusive answer yet. This work aims at providing a comprehensive overview of image captioning approaches, from visual encoding and text generation to training strategies, datasets, and evaluation metrics. In this respect, we quantitatively compare many relevant state-of-the-art approaches to identify the most impactful technical innovations in architectures and training strategies. Moreover, many variants of the problem and its open challenges are discussed. The final goal of this work is to serve as a tool for understanding the existing literature and highlighting the future directions for a research area where Computer Vision and Natural Language Processing can find an optimal synergy.
Learning to Select: A Fully Attentive Approach for Novel Object Captioning
Jun 02, 2021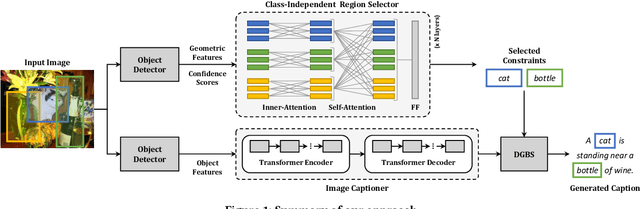
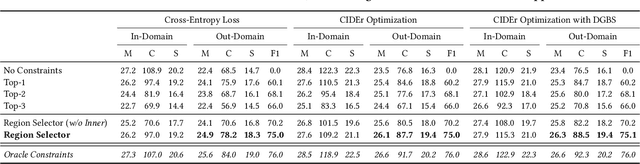
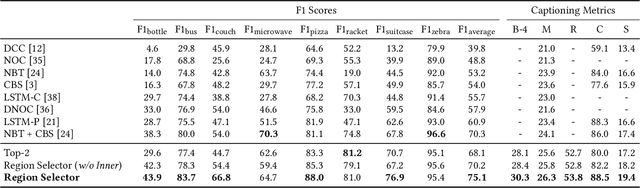
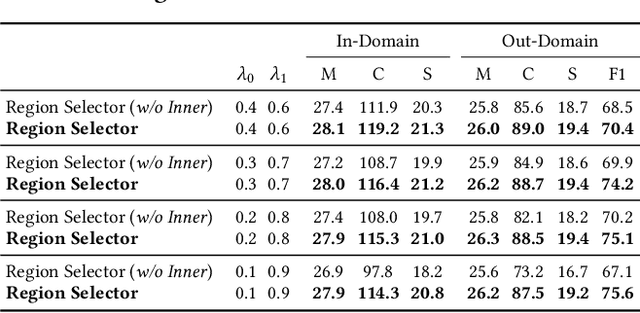
Image captioning models have lately shown impressive results when applied to standard datasets. Switching to real-life scenarios, however, constitutes a challenge due to the larger variety of visual concepts which are not covered in existing training sets. For this reason, novel object captioning (NOC) has recently emerged as a paradigm to test captioning models on objects which are unseen during the training phase. In this paper, we present a novel approach for NOC that learns to select the most relevant objects of an image, regardless of their adherence to the training set, and to constrain the generative process of a language model accordingly. Our architecture is fully-attentive and end-to-end trainable, also when incorporating constraints. We perform experiments on the held-out COCO dataset, where we demonstrate improvements over the state of the art, both in terms of adaptability to novel objects and caption quality.
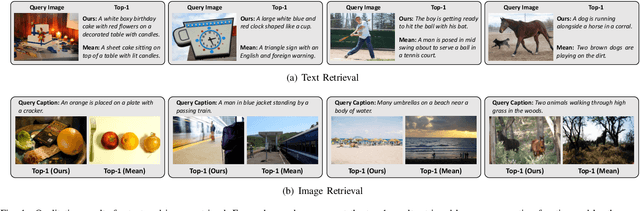
A Novel Attention-based Aggregation Function to Combine Vision and Language
Apr 27, 2020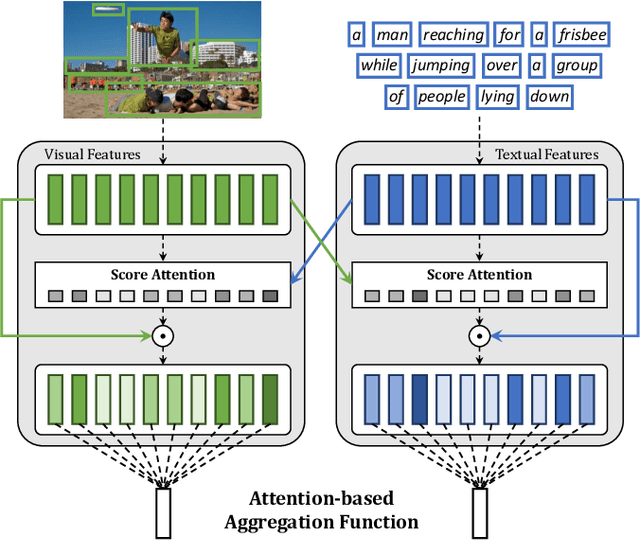
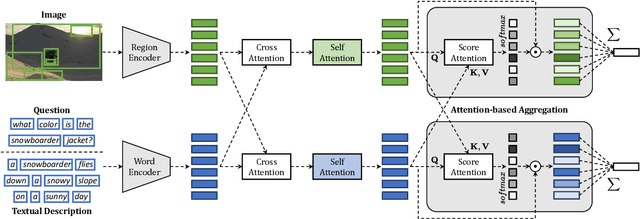

The joint understanding of vision and language has been recently gaining a lot of attention in both the Computer Vision and Natural Language Processing communities, with the emergence of tasks such as image captioning, image-text matching, and visual question answering. As both images and text can be encoded as sets or sequences of elements -- like regions and words -- proper reduction functions are needed to transform a set of encoded elements into a single response, like a classification or similarity score. In this paper, we propose a novel fully-attentive reduction method for vision and language. Specifically, our approach computes a set of scores for each element of each modality employing a novel variant of cross-attention, and performs a learnable and cross-modal reduction, which can be used for both classification and ranking. We test our approach on image-text matching and visual question answering, building fair comparisons with other reduction choices, on both COCO and VQA 2.0 datasets. Experimentally, we demonstrate that our approach leads to a performance increase on both tasks. Further, we conduct ablation studies to validate the role of each component of the approach.
M$^2$: Meshed-Memory Transformer for Image Captioning
Dec 17, 2019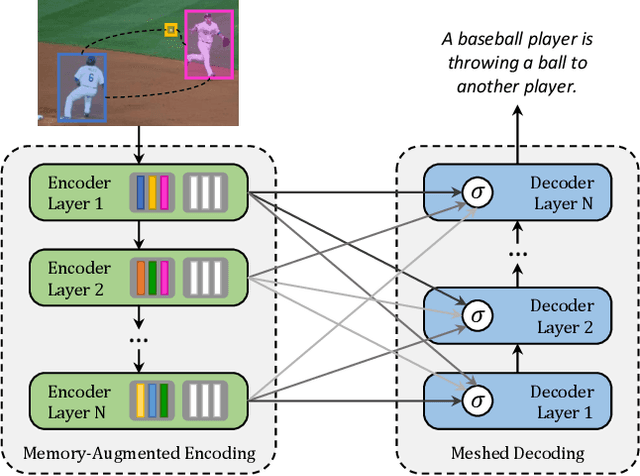
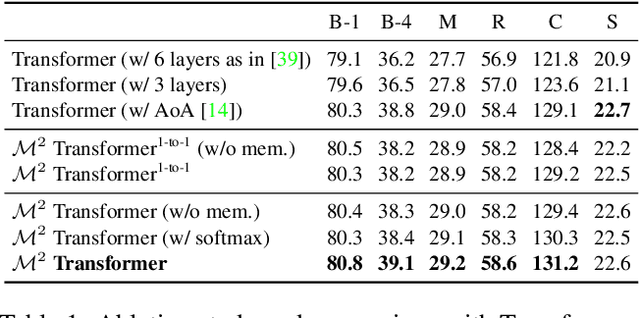
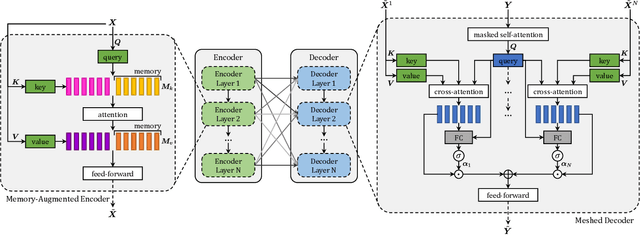
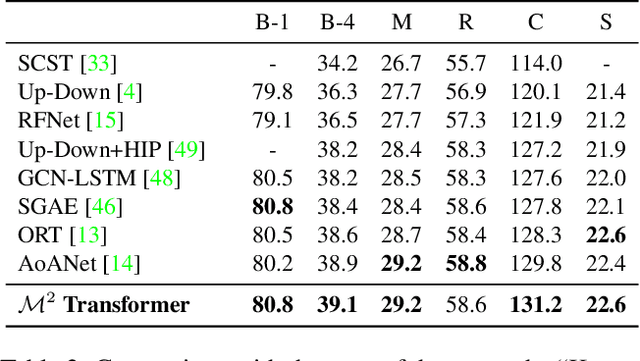
Transformer-based architectures represent the state of the art in sequence modeling tasks like machine translation and language understanding. Their applicability to multi-modal contexts like image captioning, however, is still largely under-explored. With the aim of filling this gap, we present M$^2$ - a Meshed Transformer with Memory for Image Captioning. The architecture improves both the image encoding and the language generation steps: it learns a multi-level representation of the relationships between image regions integrating learned a priori knowledge, and uses a mesh-like connectivity at decoding stage to exploit low- and high-level features. Experimentally, we investigate the performance of the M$^2$ Transformer and different fully-attentive models in comparison with recurrent ones. When tested on COCO, our proposal achieves a new state of the art in single-model and ensemble configurations on the "Karpathy" test split and on the online test server. We also assess its performances when describing objects unseen in the training set. Trained models and code for reproducing the experiments are publicly available at: https://github.com/aimagelab/meshed-memory-transformer.
A Deep Learning based approach to VM behavior identification in cloud systems
Mar 05, 2019
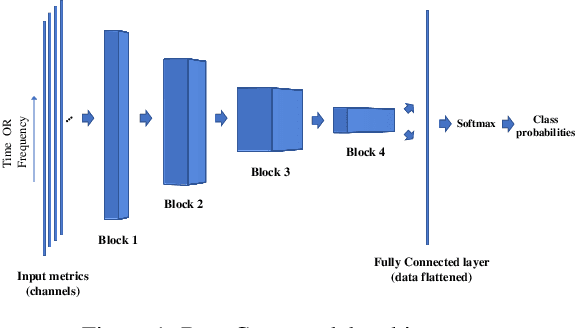

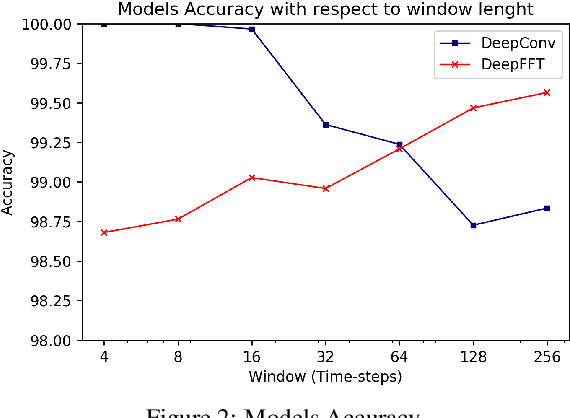
Cloud computing data centers are growing in size and complexity to the point where monitoring and management of the infrastructure become a challenge due to scalability issues. A possible approach to cope with the size of such data centers is to identify VMs exhibiting a similar behavior. Existing literature demonstrated that clustering together VMs that show a similar behavior may improve the scalability of both monitoring andmanagement of a data center. However, available techniques suffer from a trade-off between accuracy and time to achieve this result. Throughout this paper we propose a different approach where, instead of an unsupervised clustering, we rely on classifiers based on deep learning techniques to assigna newly deployed VMs to a cluster of already-known VMs. The two proposed classifiers, namely DeepConv and DeepFFT use a convolution neural network and (in the latter model) exploits Fast Fourier Transformation to classify the VMs. Our proposal is validated using a set of traces describing the behavior of VMs from a realcloud data center. The experiments compare our proposal with state-of-the-art solutions available in literature, demonstrating that our proposal achieve better performance. Furthermore, we show that our solution issignificantly faster than the alternatives as it can produce a perfect classification even with just a few samples of data, making our proposal viable also toclassify on-demand VMs that are characterized by a short life span.