 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Novel Attention-based Aggregation Function to Combine Vision and Language
Paper and Code
Apr 27, 2020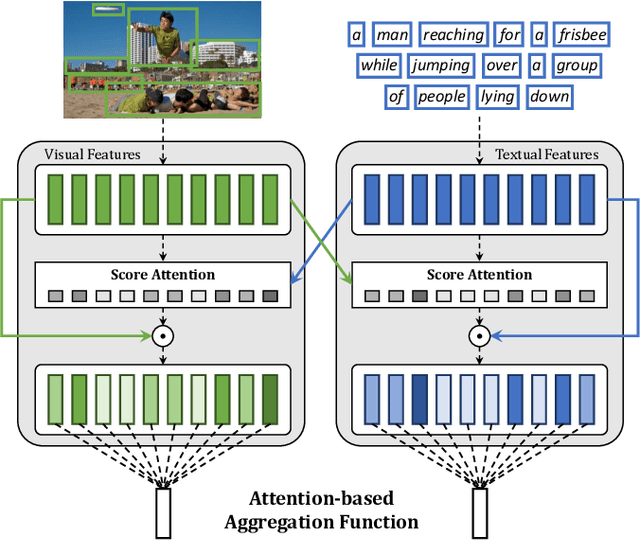
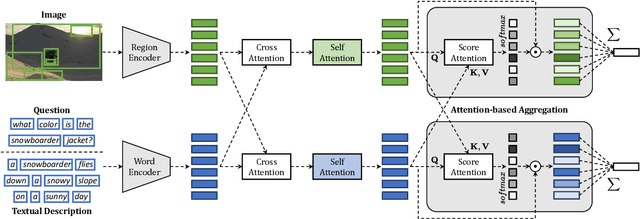

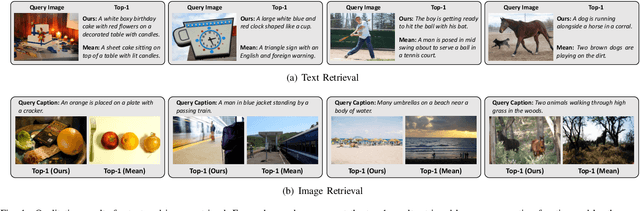
The joint understanding of vision and language has been recently gaining a lot of attention in both the Computer Vision and Natural Language Processing communities, with the emergence of tasks such as image captioning, image-text matching, and visual question answering. As both images and text can be encoded as sets or sequences of elements -- like regions and words -- proper reduction functions are needed to transform a set of encoded elements into a single response, like a classification or similarity score. In this paper, we propose a novel fully-attentive reduction method for vision and language. Specifically, our approach computes a set of scores for each element of each modality employing a novel variant of cross-attention, and performs a learnable and cross-modal reduction, which can be used for both classification and ranking. We test our approach on image-text matching and visual question answering, building fair comparisons with other reduction choices, on both COCO and VQA 2.0 datasets. Experimentally, we demonstrate that our approach leads to a performance increase on both tasks. Further, we conduct ablation studies to validate the role of each component of the approach.