 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-scale temporal-frequency attention for music source separation
Paper and Code
Sep 02, 2022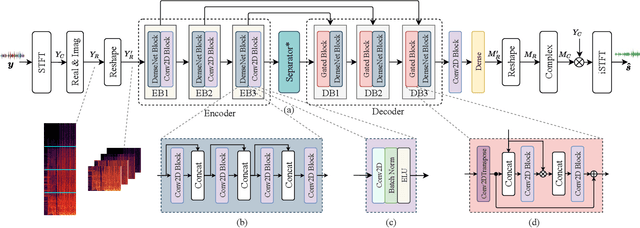
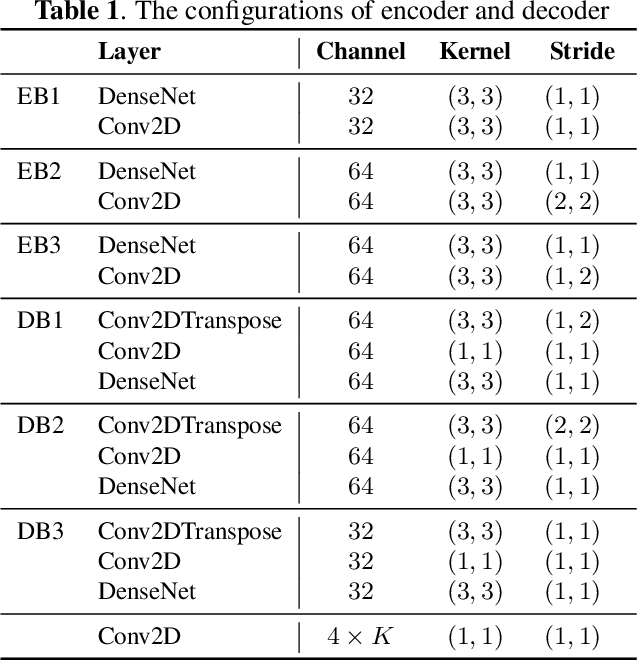
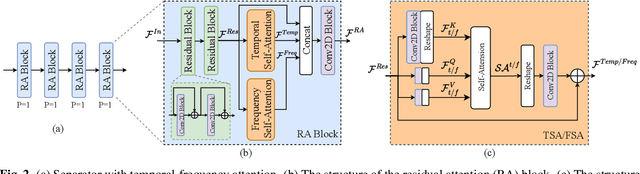
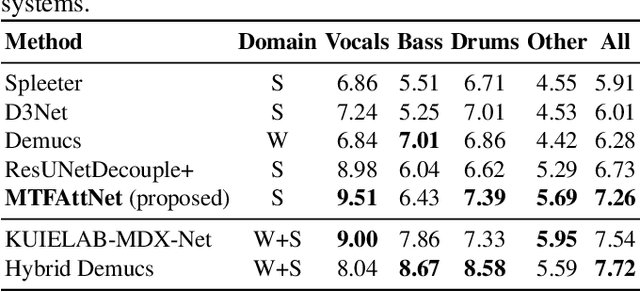
In recent years, deep neural networks (DNNs) based approaches have achieved the start-of-the-art performance for music source separation (MSS). Although previous methods have addressed the large receptive field modeling using various methods, the temporal and frequency correlations of the music spectrogram with repeated patterns have not been explicitly explored for the MSS task. In this paper, a temporal-frequency attention module is proposed to model the spectrogram correlations along both temporal and frequency dimensions. Moreover, a multi-scale attention is proposed to effectively capture the correlations for music signal. The experimental results on MUSDB18 dataset show that the proposed method outperforms the existing state-of-the-art systems with 9.51 dB signal-to-distortion ratio (SDR) on separating the vocal stems, which is the primary practical application of MSS.