 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRAMP: Retrieval-Augmented MOS Prediction via Confidence-based Dynamic Weighting
Paper and Code
Aug 31, 2023
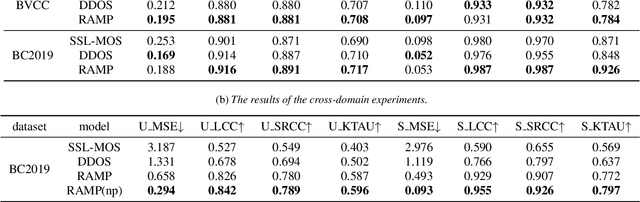
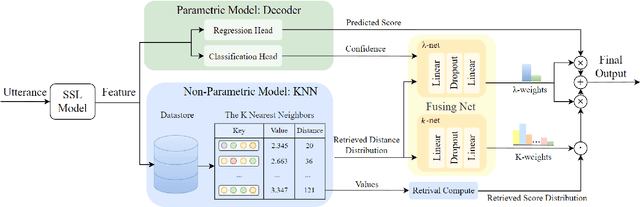

Automatic Mean Opinion Score (MOS) prediction is crucial to evaluate the perceptual quality of the synthetic speech. While recent approaches using pre-trained self-supervised learning (SSL) models have shown promising results, they only partly address the data scarcity issue for the feature extractor. This leaves the data scarcity issue for the decoder unresolved and leading to suboptimal performance. To address this challenge, we propose a retrieval-augmented MOS prediction method, dubbed {\bf RAMP}, to enhance the decoder's ability against the data scarcity issue. A fusing network is also proposed to dynamically adjust the retrieval scope for each instance and the fusion weights based on the predictive confidence. Experimental results show that our proposed method outperforms the existing methods in multiple scenarios.