 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnveiling and Bridging the Functional Perception Gap in MLLMs: Atomic Visual Alignment and Hierarchical Evaluation via PET-Bench
Jan 06, 2026While Multimodal Large Language Models (MLLMs) have demonstrated remarkable proficiency in tasks such as abnormality detection and report generation for anatomical modalities, their capability in functional imaging remains largely unexplored. In this work, we identify and quantify a fundamental functional perception gap: the inability of current vision encoders to decode functional tracer biodistribution independent of morphological priors. Identifying Positron Emission Tomography (PET) as the quintessential modality to investigate this disconnect, we introduce PET-Bench, the first large-scale functional imaging benchmark comprising 52,308 hierarchical QA pairs from 9,732 multi-site, multi-tracer PET studies. Extensive evaluation of 19 state-of-the-art MLLMs reveals a critical safety hazard termed the Chain-of-Thought (CoT) hallucination trap. We observe that standard CoT prompting, widely considered to enhance reasoning, paradoxically decouples linguistic generation from visual evidence in PET, producing clinically fluent but factually ungrounded diagnoses. To resolve this, we propose Atomic Visual Alignment (AVA), a simple fine-tuning strategy that enforces the mastery of low-level functional perception prior to high-level diagnostic reasoning. Our results demonstrate that AVA effectively bridges the perception gap, transforming CoT from a source of hallucination into a robust inference tool and improving diagnostic accuracy by up to 14.83%. Code and data are available at https://github.com/yezanting/PET-Bench.
Towards a general-purpose foundation model for fMRI analysis
Jun 11, 2025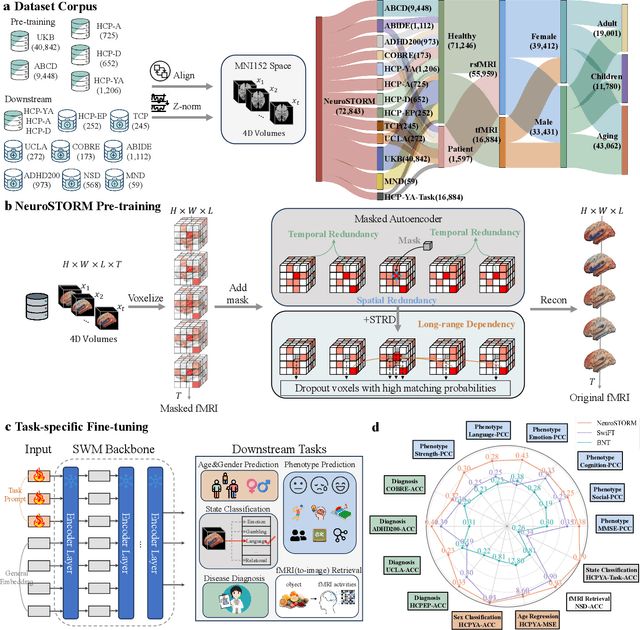

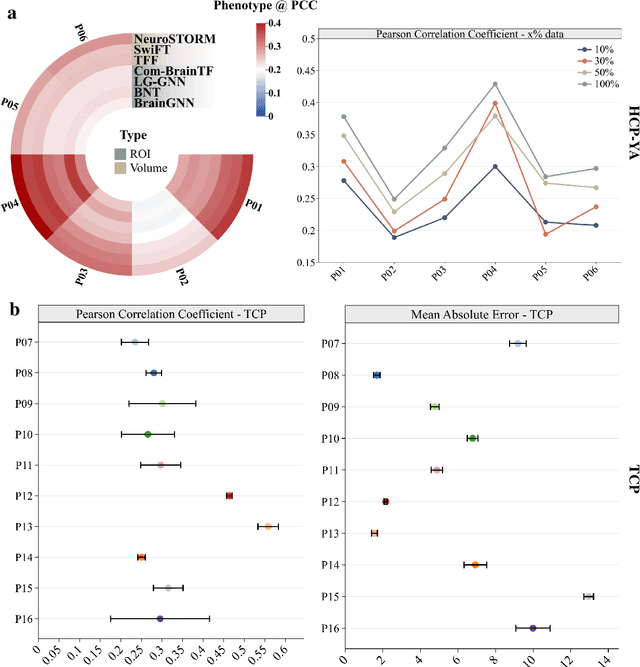
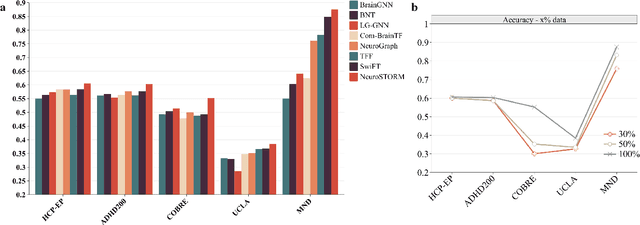
Functional Magnetic Resonance Imaging (fMRI) is essential for studying brain function and diagnosing neurological disorders, but current analysis methods face reproducibility and transferability issues due to complex pre-processing and task-specific models. We introduce NeuroSTORM (Neuroimaging Foundation Model with Spatial-Temporal Optimized Representation Modeling), a generalizable framework that directly learns from 4D fMRI volumes and enables efficient knowledge transfer across diverse applications. NeuroSTORM is pre-trained on 28.65 million fMRI frames (>9,000 hours) from over 50,000 subjects across multiple centers and ages 5 to 100. Using a Mamba backbone and a shifted scanning strategy, it efficiently processes full 4D volumes. We also propose a spatial-temporal optimized pre-training approach and task-specific prompt tuning to improve transferability. NeuroSTORM outperforms existing methods across five tasks: age/gender prediction, phenotype prediction, disease diagnosis, fMRI-to-image retrieval, and task-based fMRI classification. It demonstrates strong clinical utility on datasets from hospitals in the U.S., South Korea, and Australia, achieving top performance in disease diagnosis and cognitive phenotype prediction. NeuroSTORM provides a standardized, open-source foundation model to improve reproducibility and transferability in fMRI-based clinical research.
A Comprehensive Evaluation of Multi-Modal Large Language Models for Endoscopy Analysis
May 29, 2025



Endoscopic procedures are essential for diagnosing and treating internal diseases, and multi-modal large language models (MLLMs) are increasingly applied to assist in endoscopy analysis. However, current benchmarks are limited, as they typically cover specific endoscopic scenarios and a small set of clinical tasks, failing to capture the real-world diversity of endoscopic scenarios and the full range of skills needed in clinical workflows. To address these issues, we introduce EndoBench, the first comprehensive benchmark specifically designed to assess MLLMs across the full spectrum of endoscopic practice with multi-dimensional capacities. EndoBench encompasses 4 distinct endoscopic scenarios, 12 specialized clinical tasks with 12 secondary subtasks, and 5 levels of visual prompting granularities, resulting in 6,832 rigorously validated VQA pairs from 21 diverse datasets. Our multi-dimensional evaluation framework mirrors the clinical workflow--spanning anatomical recognition, lesion analysis, spatial localization, and surgical operations--to holistically gauge the perceptual and diagnostic abilities of MLLMs in realistic scenarios. We benchmark 23 state-of-the-art models, including general-purpose, medical-specialized, and proprietary MLLMs, and establish human clinician performance as a reference standard. Our extensive experiments reveal: (1) proprietary MLLMs outperform open-source and medical-specialized models overall, but still trail human experts; (2) medical-domain supervised fine-tuning substantially boosts task-specific accuracy; and (3) model performance remains sensitive to prompt format and clinical task complexity. EndoBench establishes a new standard for evaluating and advancing MLLMs in endoscopy, highlighting both progress and persistent gaps between current models and expert clinical reasoning. We publicly release our benchmark and code.
MAP: Evaluation and Multi-Agent Enhancement of Large Language Models for Inpatient Pathways
Mar 17, 2025Inpatient pathways demand complex clinical decision-making based on comprehensive patient information, posing critical challenges for clinicians. Despite advancements in large language models (LLMs) in medical applications, limited research focused on artificial intelligence (AI) inpatient pathways systems, due to the lack of large-scale inpatient datasets. Moreover, existing medical benchmarks typically concentrated on medical question-answering and examinations, ignoring the multifaceted nature of clinical decision-making in inpatient settings. To address these gaps, we first developed the Inpatient Pathway Decision Support (IPDS) benchmark from the MIMIC-IV database, encompassing 51,274 cases across nine triage departments and 17 major disease categories alongside 16 standardized treatment options. Then, we proposed the Multi-Agent Inpatient Pathways (MAP) framework to accomplish inpatient pathways with three clinical agents, including a triage agent managing the patient admission, a diagnosis agent serving as the primary decision maker at the department, and a treatment agent providing treatment plans. Additionally, our MAP framework includes a chief agent overseeing the inpatient pathways to guide and promote these three clinician agents. Extensive experiments showed our MAP improved the diagnosis accuracy by 25.10% compared to the state-of-the-art LLM HuatuoGPT2-13B. It is worth noting that our MAP demonstrated significant clinical compliance, outperforming three board-certified clinicians by 10%-12%, establishing a foundation for inpatient pathways systems.
Graph Augmentation Clustering Network
Nov 19, 2022
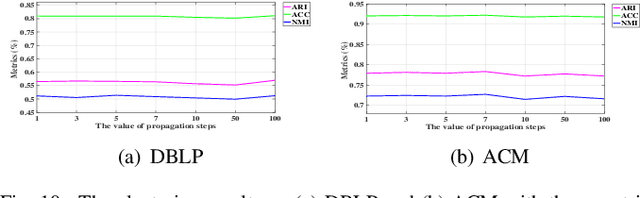


Existing graph clustering networks heavily rely on a predefined graph and may fail if the initial graph is of low quality. To tackle this issue, we propose a novel graph augmentation clustering network capable of adaptively enhancing the initial graph to achieve better clustering performance. Specifically, we first integrate the node attribute and topology structure information to learn the latent feature representation. Then, we explore the local geometric structure information on the embedding space to construct an adjacency graph and subsequently develop an adaptive graph augmentation architecture to fuse that graph with the initial one dynamically. Finally, we minimize the Jeffreys divergence between multiple derived distributions to conduct network training in an unsupervised fashion. Extensive experiments on six commonly used benchmark datasets demonstrate that the proposed method consistently outperforms several state-of-the-art approaches. In particular, our method improves the ARI by more than 9.39\% over the best baseline on DBLP. The source codes and data have been submitted to the appendix.
Deep Attention-guided Graph Clustering with Dual Self-supervision
Nov 10, 2021



Existing deep embedding clustering works only consider the deepest layer to learn a feature embedding and thus fail to well utilize the available discriminative information from cluster assignments, resulting performance limitation. To this end, we propose a novel method, namely deep attention-guided graph clustering with dual self-supervision (DAGC). Specifically, DAGC first utilizes a heterogeneity-wise fusion module to adaptively integrate the features of an auto-encoder and a graph convolutional network in each layer and then uses a scale-wise fusion module to dynamically concatenate the multi-scale features in different layers. Such modules are capable of learning a discriminative feature embedding via an attention-based mechanism. In addition, we design a distribution-wise fusion module that leverages cluster assignments to acquire clustering results directly. To better explore the discriminative information from the cluster assignments, we develop a dual self-supervision solution consisting of a soft self-supervision strategy with a triplet Kullback-Leibler divergence loss and a hard self-supervision strategy with a pseudo supervision loss. Extensive experiments validate that our method consistently outperforms state-of-the-art methods on six benchmark datasets. Especially, our method improves the ARI by more than 18.14% over the best baseline.
Adaptive Attribute and Structure Subspace Clustering Network
Sep 28, 2021
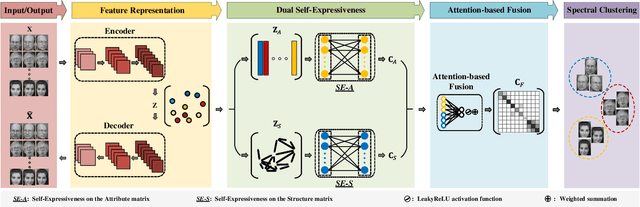
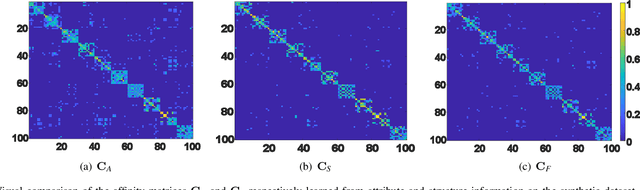
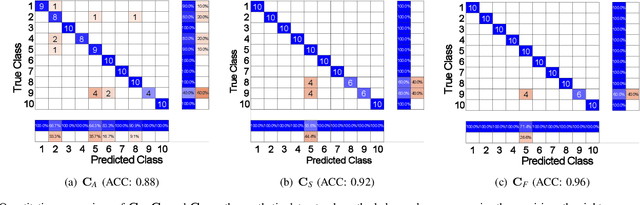
Deep self-expressiveness-based subspace clustering methods have demonstrated effectiveness. However, existing works only consider the attribute information to conduct the self-expressiveness, which may limit the clustering performance. In this paper, we propose a novel adaptive attribute and structure subspace clustering network (AASSC-Net) to simultaneously consider the attribute and structure information in an adaptive graph fusion manner. Specifically, we first exploit an auto-encoder to represent input data samples with latent features for the construction of an attribute matrix. We also construct a mixed signed and symmetric structure matrix to capture the local geometric structure underlying data samples. Then, we perform self-expressiveness on the constructed attribute and structure matrices to learn their affinity graphs separately. Finally, we design a novel attention-based fusion module to adaptively leverage these two affinity graphs to construct a more discriminative affinity graph. Extensive experimental results on commonly used benchmark datasets demonstrate that our AASSC-Net significantly outperforms state-of-the-art methods. In addition, we conduct comprehensive ablation studies to discuss the effectiveness of the designed modules. The code will be publicly available at https://github.com/ZhihaoPENG-CityU.
Attention-driven Graph Clustering Network
Aug 12, 2021

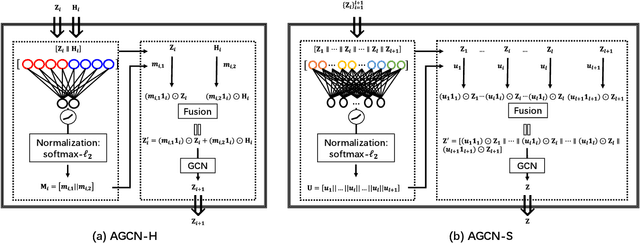

The combination of the traditional convolutional network (i.e., an auto-encoder) and the graph convolutional network has attracted much attention in clustering, in which the auto-encoder extracts the node attribute feature and the graph convolutional network captures the topological graph feature. However, the existing works (i) lack a flexible combination mechanism to adaptively fuse those two kinds of features for learning the discriminative representation and (ii) overlook the multi-scale information embedded at different layers for subsequent cluster assignment, leading to inferior clustering results. To this end, we propose a novel deep clustering method named Attention-driven Graph Clustering Network (AGCN). Specifically, AGCN exploits a heterogeneity-wise fusion module to dynamically fuse the node attribute feature and the topological graph feature. Moreover, AGCN develops a scale-wise fusion module to adaptively aggregate the multi-scale features embedded at different layers. Based on a unified optimization framework, AGCN can jointly perform feature learning and cluster assignment in an unsupervised fashion. Compared with the existing deep clustering methods, our method is more flexible and effective since it comprehensively considers the numerous and discriminative information embedded in the network and directly produces the clustering results. Extensive quantitative and qualitative results on commonly used benchmark datasets validate that our AGCN consistently outperforms state-of-the-art methods.
Maximum Entropy Subspace Clustering Network
Dec 06, 2020



Deep subspace clustering network (DSC-Net) and its numerous variants have achieved impressive performance for subspace clustering, in which an auto-encoder non-linearly maps input data into a latent space, and a fully connected layer named self-expressiveness module is introduced between the encoder and the decoder to learn an affinity matrix. However, the adopted regularization on the affinity matrix (e.g., sparse, Tikhonov, or low-rank) is still insufficient to drive the learning of an ideal affinity matrix, thus limiting their performance. In addition, in DSC-Net, the self-expressiveness module and the auto-encoder module are tightly coupled, making the training of the DSC-Net non-trivial. To this end, in this paper, we propose a novel deep learning-based clustering method named Maximum Entropy Subspace Clustering Network (MESC-Net). Specifically, MESC-Net maximizes the learned affinity matrix's entropy to encourage it to exhibit an ideal affinity matrix structure. We theoretically prove that the affinity matrix driven by MESC-Net obeys the block-diagonal property, and experimentally show that its elements corresponding to the same subspace are uniformly and densely distributed, which gives better clustering performance. Moreover, we explicitly decouple the auto-encoder module and the self-expressiveness module. Extensive quantitative and qualitative results on commonly used benchmark datasets validate MESC-Net significantly outperforms state-of-the-art methods.