 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCohortGPT: An Enhanced GPT for Participant Recruitment in Clinical Study
Paper and Code


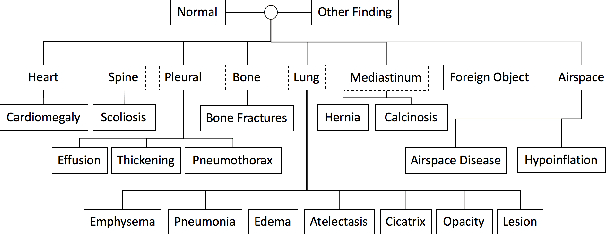

Participant recruitment based on unstructured medical texts such as clinical notes and radiology reports has been a challenging yet important task for the cohort establishment in clinical research. Recently, Large Language Models (LLMs) such as ChatGPT have achieved tremendous success in various downstream tasks thanks to their promising performance in language understanding, inference, and generation. It is then natural to test their feasibility in solving the cohort recruitment task, which involves the classification of a given paragraph of medical text into disease label(s). However, when applied to knowledge-intensive problem settings such as medical text classification, where the LLMs are expected to understand the decision made by human experts and accurately identify the implied disease labels, the LLMs show a mediocre performance. A possible explanation is that, by only using the medical text, the LLMs neglect to use the rich context of additional information that languages afford. To this end, we propose to use a knowledge graph as auxiliary information to guide the LLMs in making predictions. Moreover, to further boost the LLMs adapt to the problem setting, we apply a chain-of-thought (CoT) sample selection strategy enhanced by reinforcement learning, which selects a set of CoT samples given each individual medical report. Experimental results and various ablation studies show that our few-shot learning method achieves satisfactory performance compared with fine-tuning strategies and gains superb advantages when the available data is limited. The code and sample dataset of the proposed CohortGPT model is available at: https://anonymous.4open.science/r/CohortGPT-4872/