 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCV-MOS: A Cross-View Model for Motion Segmentation
Paper and Code
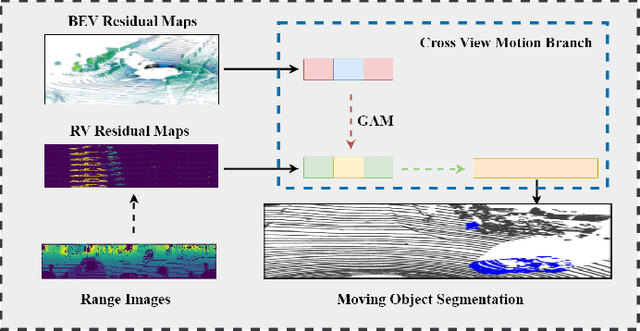
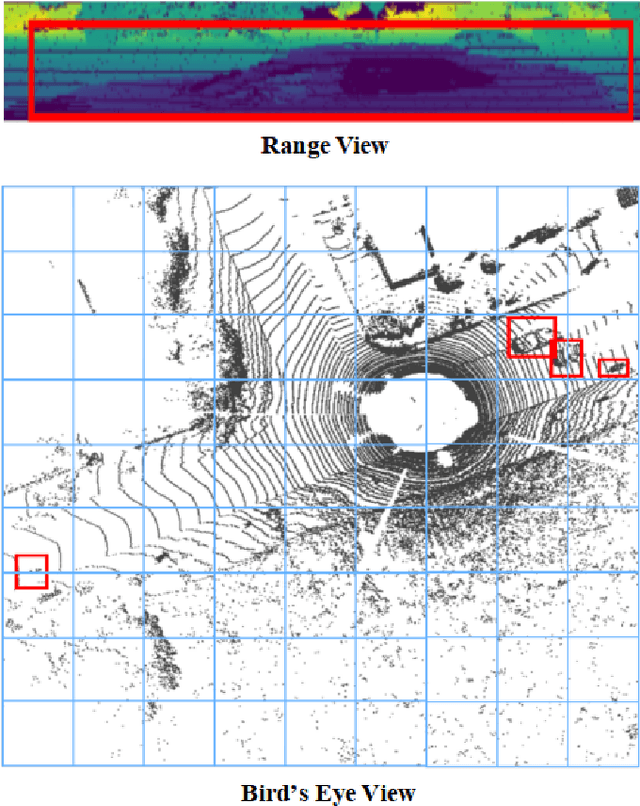
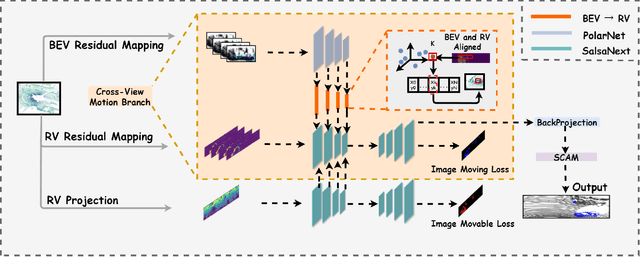
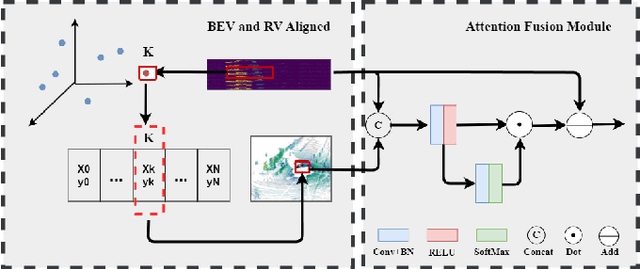
In autonomous driving, accurately distinguishing between static and moving objects is crucial for the autonomous driving system. When performing the motion object segmentation (MOS) task, effectively leveraging motion information from objects becomes a primary challenge in improving the recognition of moving objects. Previous methods either utilized range view (RV) or bird's eye view (BEV) residual maps to capture motion information. Unlike traditional approaches, we propose combining RV and BEV residual maps to exploit a greater potential of motion information jointly. Thus, we introduce CV-MOS, a cross-view model for moving object segmentation. Novelty, we decouple spatial-temporal information by capturing the motion from BEV and RV residual maps and generating semantic features from range images, which are used as moving object guidance for the motion branch. Our direct and unique solution maximizes the use of range images and RV and BEV residual maps, significantly enhancing the performance of LiDAR-based MOS task. Our method achieved leading IoU(\%) scores of 77.5\% and 79.2\% on the validation and test sets of the SemanticKitti dataset. In particular, CV-MOS demonstrates SOTA performance to date on various datasets. The CV-MOS implementation is available at https://github.com/SCNU-RISLAB/CV-MOS