 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKimi K2.5: Visual Agentic Intelligence
Feb 02, 2026We introduce Kimi K2.5, an open-source multimodal agentic model designed to advance general agentic intelligence. K2.5 emphasizes the joint optimization of text and vision so that two modalities enhance each other. This includes a series of techniques such as joint text-vision pre-training, zero-vision SFT, and joint text-vision reinforcement learning. Building on this multimodal foundation, K2.5 introduces Agent Swarm, a self-directed parallel agent orchestration framework that dynamically decomposes complex tasks into heterogeneous sub-problems and executes them concurrently. Extensive evaluations show that Kimi K2.5 achieves state-of-the-art results across various domains including coding, vision, reasoning, and agentic tasks. Agent Swarm also reduces latency by up to $4.5\times$ over single-agent baselines. We release the post-trained Kimi K2.5 model checkpoint to facilitate future research and real-world applications of agentic intelligence.
TriSpec: Ternary Speculative Decoding via Lightweight Proxy Verification
Jan 30, 2026Inference efficiency in Large Language Models (LLMs) is fundamentally limited by their serial, autoregressive generation, especially as reasoning becomes a key capability and response sequences grow longer. Speculative decoding (SD) offers a powerful solution, providing significant speed-ups through its lightweight drafting and parallel verification mechanism. While existing work has nearly saturated improvements in draft effectiveness and efficiency, this paper advances SD from a new yet critical perspective: the verification cost. We propose TriSpec, a novel ternary SD framework that, at its core, introduces a lightweight proxy to significantly reduce computational cost by approving easily verifiable draft sequences and engaging the full target model only when encountering uncertain tokens. TriSpec can be integrated with state-of-the-art SD methods like EAGLE-3 to further reduce verification costs, achieving greater acceleration. Extensive experiments on the Qwen3 and DeepSeek-R1-Distill-Qwen/LLaMA families show that TriSpec achieves up to 35\% speedup over standard SD, with up to 50\% fewer target model invocations while maintaining comparable accuracy.
O-Researcher: An Open Ended Deep Research Model via Multi-Agent Distillation and Agentic RL
Jan 07, 2026The performance gap between closed-source and open-source large language models (LLMs) is largely attributed to disparities in access to high-quality training data. To bridge this gap, we introduce a novel framework for the automated synthesis of sophisticated, research-grade instructional data. Our approach centers on a multi-agent workflow where collaborative AI agents simulate complex tool-integrated reasoning to generate diverse and high-fidelity data end-to-end. Leveraging this synthesized data, we develop a two-stage training strategy that integrates supervised fine-tuning with a novel reinforcement learning method, designed to maximize model alignment and capability. Extensive experiments demonstrate that our framework empowers open-source models across multiple scales, enabling them to achieve new state-of-the-art performance on the major deep research benchmark. This work provides a scalable and effective pathway for advancing open-source LLMs without relying on proprietary data or models.
Comparison Research of Millimeter-Wave/Infrared Co-aperture Reflector Antenna Systems Based on a Specialized Film
Apr 27, 2025This paper presents a novel co-aperture reflector antenna operating in millimeter-wave (MMW) and infrared (IR) for cloud detection radar. The proposed design combines a back-fed dual-reflector antenna, an IR optical reflection system, and a specialize thin film with IR-reflective/MMW-transmissive properties. Simulations demonstrate a gain exceeding 50 dBi within 94 GHz plush or minus 500 MHz bandwidth, with 0.46{\deg} beamwidth in both azimuth (E-plane) and elevation (H-plane) and sidelobe levels below -25 dB. This co-aperture architecture addresses the limitations of standalone MMW and IR radars, enabling high-resolution cloud microphysical parameter retrieval while minimizing system footprint. The design lays a foundation for airborne/spaceborne multi-mode detection systems.
Qwen2.5-1M Technical Report
Jan 26, 2025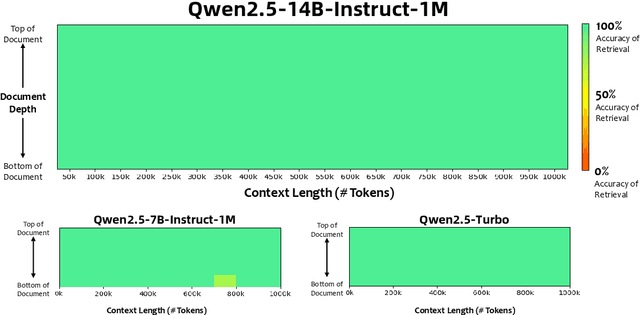

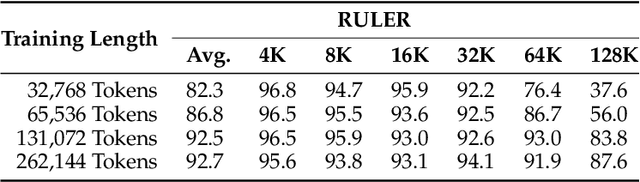
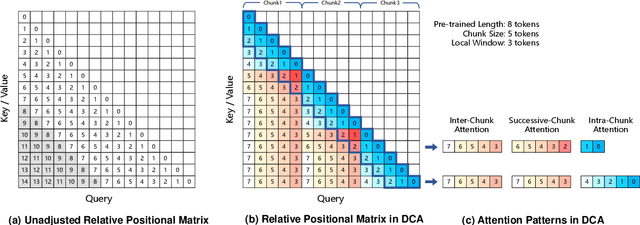
We introduce Qwen2.5-1M, a series of models that extend the context length to 1 million tokens. Compared to the previous 128K version, the Qwen2.5-1M series have significantly enhanced long-context capabilities through long-context pre-training and post-training. Key techniques such as long data synthesis, progressive pre-training, and multi-stage supervised fine-tuning are employed to effectively enhance long-context performance while reducing training costs. To promote the use of long-context models among a broader user base, we present and open-source our inference framework. This framework includes a length extrapolation method that can expand the model context lengths by at least four times, or even more, without additional training. To reduce inference costs, we implement a sparse attention method along with chunked prefill optimization for deployment scenarios and a sparsity refinement method to improve precision. Additionally, we detail our optimizations in the inference engine, including kernel optimization, pipeline parallelism, and scheduling optimization, which significantly enhance overall inference performance. By leveraging our inference framework, the Qwen2.5-1M models achieve a remarkable 3x to 7x prefill speedup in scenarios with 1 million tokens of context. This framework provides an efficient and powerful solution for developing applications that require long-context processing using open-source models. The Qwen2.5-1M series currently includes the open-source models Qwen2.5-7B-Instruct-1M and Qwen2.5-14B-Instruct-1M, as well as the API-accessed model Qwen2.5-Turbo. Evaluations show that Qwen2.5-1M models have been greatly improved in long-context tasks without compromising performance in short-context scenarios. Specifically, the Qwen2.5-14B-Instruct-1M model significantly outperforms GPT-4o-mini in long-context tasks and supports contexts eight times longer.
Amphista: Accelerate LLM Inference with Bi-directional Multiple Drafting Heads in a Non-autoregressive Style
Jun 19, 2024



Large Language Models (LLMs) inherently use autoregressive decoding, which lacks parallelism in inference and results in significantly slow inference speeds, especially when hardware parallel accelerators and memory bandwidth are not fully utilized. In this work, we propose Amphista, a speculative decoding algorithm that adheres to a non-autoregressive decoding paradigm. Owing to the increased parallelism, our method demonstrates higher efficiency in inference compared to autoregressive methods. Specifically, Amphista models an Auto-embedding Block capable of parallel inference, incorporating bi-directional attention to enable interaction between different drafting heads. Additionally, Amphista implements Staged Adaptation Layers to facilitate the transition of semantic information from the base model's autoregressive inference to the drafting heads' non-autoregressive speculation, thereby achieving paradigm transformation and feature fusion. We conduct a series of experiments on a suite of Vicuna models using MT-Bench and Spec-Bench. For the Vicuna 33B model, Amphista achieves up to 2.75$\times$ and 1.40$\times$ wall-clock acceleration compared to vanilla autoregressive decoding and Medusa, respectively, while preserving lossless generation quality.
When Parameter-efficient Tuning Meets General-purpose Vision-language Models
Dec 16, 2023



Instruction tuning has shown promising potential for developing general-purpose AI capabilities by using large-scale pre-trained models and boosts growing research to integrate multimodal information for creative applications. However, existing works still face two main limitations: the high training costs and heavy computing resource dependence of full model fine-tuning, and the lack of semantic information in instructions, which hinders multimodal alignment. Addressing these challenges, this paper proposes a novel approach to utilize Parameter-Efficient Tuning for generAl-purpose vision-Language models, namely PETAL. PETAL revolutionizes the training process by requiring only 0.5% of the total parameters, achieved through a unique mode approximation technique, which significantly reduces the training costs and reliance on heavy computing resources. Furthermore, PETAL enhances the semantic depth of instructions in two innovative ways: 1) by introducing adaptive instruction mixture-of-experts(MOEs), and 2) by fortifying the score-based linkage between parameter-efficient tuning and mutual information. Our extensive experiments across five multimodal downstream benchmarks reveal that PETAL not only outperforms current state-of-the-art methods in most scenarios but also surpasses full fine-tuning models in effectiveness. Additionally, our approach demonstrates remarkable advantages in few-shot settings, backed by comprehensive visualization analyses. Our source code is available at: https://github. com/melonking32/PETAL.
Mode Approximation Makes Good Multimodal Prompts
May 23, 2023Driven by the progress of large-scale pre-training, parameter-efficient transfer learning has gained immense popularity across different subfields of Artificial Intelligence. The core is to adapt the model to downstream tasks with only a small set of parameters. Recently, researchers have leveraged such proven techniques in multimodal tasks and achieve promising results. However, two critical issues remain unresolved: how to further reduce the complexity with lightweight design and how to boost alignment between modalities under extremely low parameters. In this paper, we propose A graceful prompt framework for cross-modal transfer (Aurora) to overcome these challenges. Considering the redundancy in existing architectures, we first utilize the mode approximation to generate 0.1M trainable parameters to implement the multimodal prompt tuning, which explores the low intrinsic dimension with only 0.04% parameters of the pre-trained model. Then, for better modality alignment, we propose the Informative Context Enhancement and Gated Query Transformation module under extremely few parameters scenes. A thorough evaluation on six cross-modal benchmarks shows that it not only outperforms the state-of-the-art but even outperforms the full fine-tuning approach. Our code is available at: https://github.com/WillDreamer/Aurora.