 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXRMDN: A Recurrent Mixture Density Networks-based Architecture for Short-Term Probabilistic Demand Forecasting in Mobility-on-Demand Systems with High Volatility
Oct 15, 2023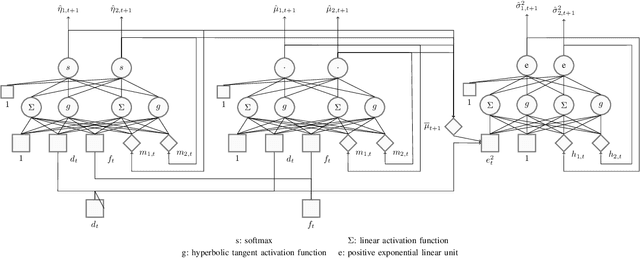
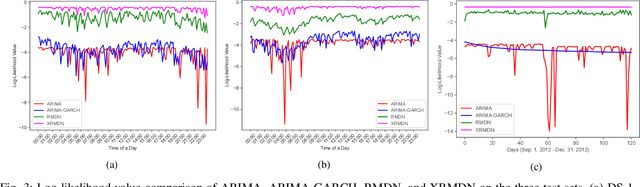
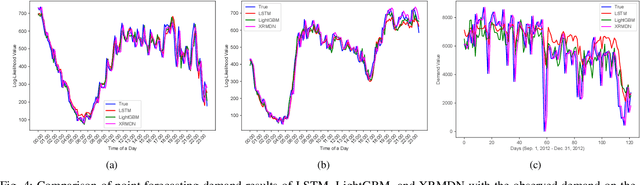
In real Mobility-on-Demand (MoD) systems, demand is subject to high and dynamic volatility, which is difficult to predict by conventional time-series forecasting approaches. Most existing forecasting approaches yield the point value as the prediction result, which ignores the uncertainty that exists in the forecasting result. This will lead to the forecasting result severely deviating from the true demand value due to the high volatility existing in demand. To fill the gap, we propose an extended recurrent mixture density network (XRMDN), which extends the weight and mean neural networks to recurrent neural networks. The recurrent neurons for mean and variance can capture the trend of the historical data-series data, which enables a better forecasting result in dynamic and high volatility. We conduct comprehensive experiments on one taxi trip record and one bike-sharing real MoD data set to validate the performance of XRMDN. Specifically, we compare our model to three types of benchmark models, including statistical, machine learning, and deep learning models on three evaluation metrics. The validation results show that XRMDN outperforms the three groups of benchmark models in terms of the evaluation metrics. Most importantly, XRMDN substantially improves the forecasting accuracy with the demands in strong volatility. Last but not least, this probabilistic demand forecasting model contributes not only to the demand prediction in MoD systems but also to other optimization application problems, especially optimization under uncertainty, in MoD applications.
Linear pretraining in recurrent mixture density networks
Feb 27, 2023We present a method for pretraining a recurrent mixture density network (RMDN). We also propose a slight modification to the architecture of the RMDN-GARCH proposed by Nikolaev et al. [2012]. The pretraining method helps the RMDN avoid bad local minima during training and improves its robustness to the persistent NaN problem, as defined by Guillaumes [2017], which is often encountered with mixture density networks. Such problem consists in frequently obtaining "Not a number" (NaN) values during training. The pretraining method proposed resolves these issues by training the linear nodes in the hidden layer of the RMDN before starting including non-linear node updates. Such an approach improves the performance of the RMDN and ensures it surpasses that of the GARCH model, which is the RMDN's linear counterpart.