 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Support: Exploiting Structure Information in Support Sets for One-Shot Learning
Paper and Code
Aug 22, 2018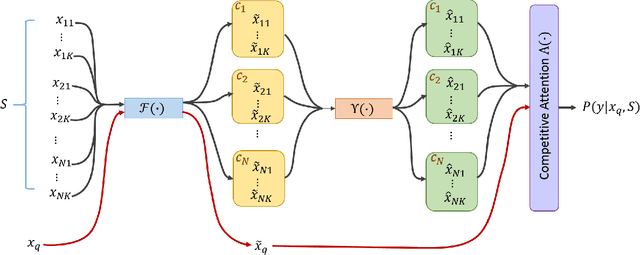
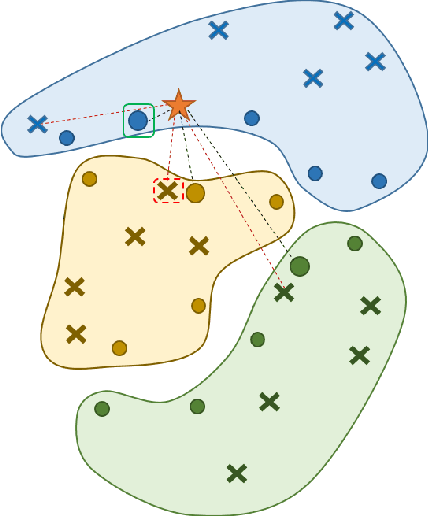
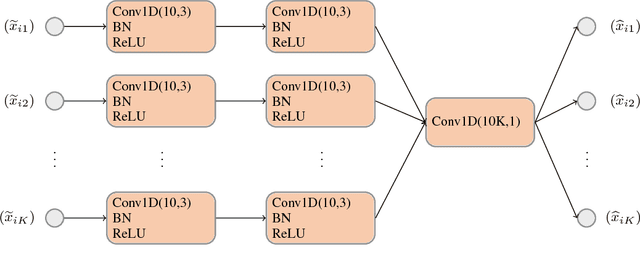
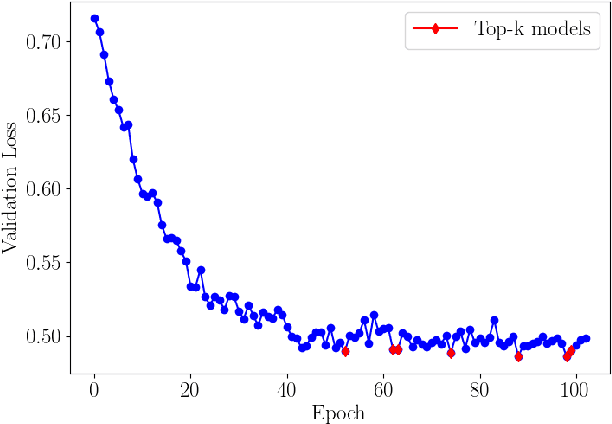
Deep Learning shows very good performance when trained on large labeled data sets. The problem of training a deep net on a few or one sample per class requires a different learning approach which can generalize to unseen classes using only a few representatives of these classes. This problem has previously been approached by meta-learning. Here we propose a novel meta-learner which shows state-of-the-art performance on common benchmarks for one/few shot classification. Our model features three novel components: First is a feed-forward embedding that takes random class support samples (after a customary CNN embedding) and transfers them to a better class representation in terms of a classification problem. Second is a novel attention mechanism, inspired by competitive learning, which causes class representatives to compete with each other to become a temporary class prototype with respect to the query point. This mechanism allows switching between representatives depending on the position of the query point. Once a prototype is chosen for each class, the predicated label is computed using a simple attention mechanism over prototypes of all considered classes. The third feature is the ability of our meta-learner to incorporate deeper CNN embedding, enabling larger capacity. Finally, to ease the training procedure and reduce overfitting, we averages the top $t$ models (evaluated on the validation) over the optimization trajectory. We show that this approach can be viewed as an approximation to an ensemble, which saves the factor of $t$ in training and test times and the factor of of $t$ in the storage of the final model.