 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData-Independent Structured Pruning of Neural Networks via Coresets
Paper and Code
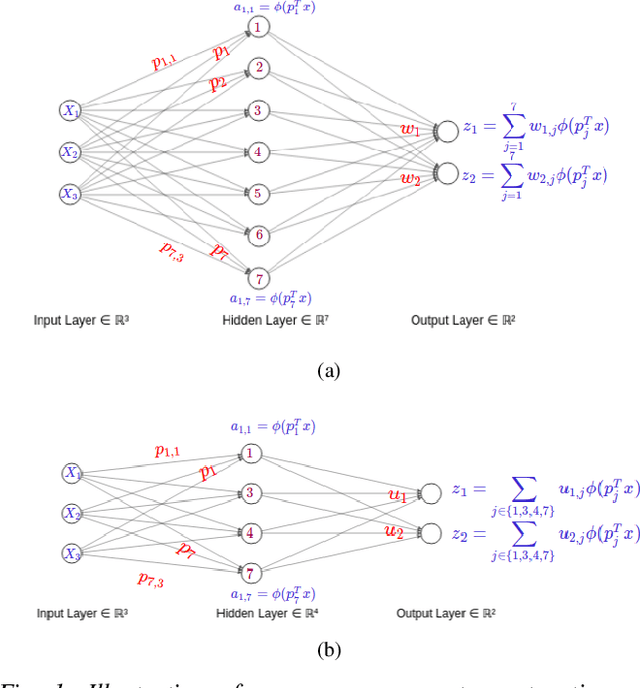
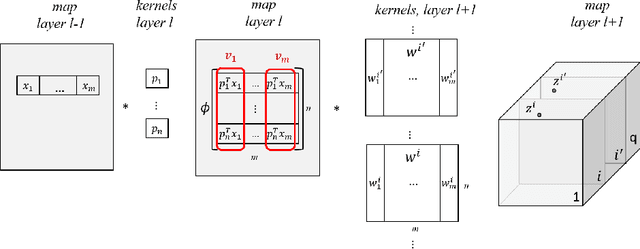
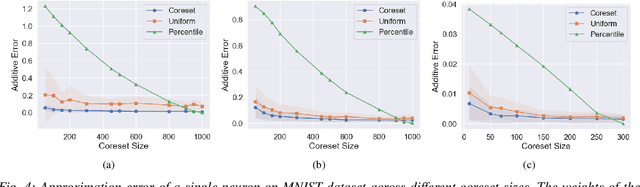
Model compression is crucial for deployment of neural networks on devices with limited computational and memory resources. Many different methods show comparable accuracy of the compressed model and similar compression rates. However, the majority of the compression methods are based on heuristics and offer no worst-case guarantees on the trade-off between the compression rate and the approximation error for an arbitrarily new sample. We propose the first efficient structured pruning algorithm with a provable trade-off between its compression rate and the approximation error for any future test sample. Our method is based on the coreset framework and it approximates the output of a layer of neurons/filters by a coreset of neurons/filters in the previous layer and discards the rest. We apply this framework in a layer-by-layer fashion from the bottom to the top. Unlike previous works, our coreset is data independent, meaning that it provably guarantees the accuracy of the function for any input $x\in \mathbb{R}^d$, including an adversarial one.