 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePractical $0.385$-Approximation for Submodular Maximization Subject to a Cardinality Constraint
May 22, 2024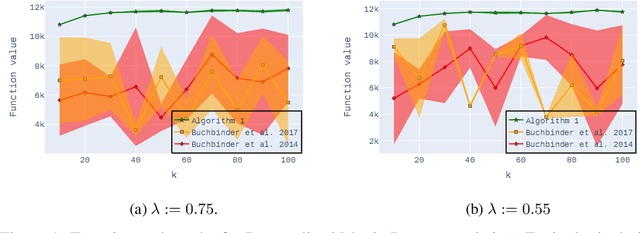
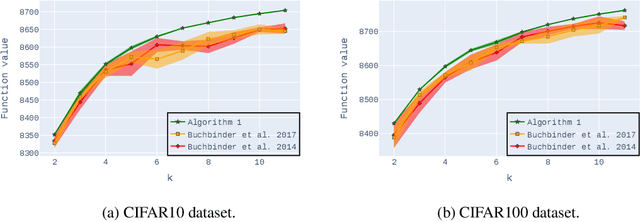
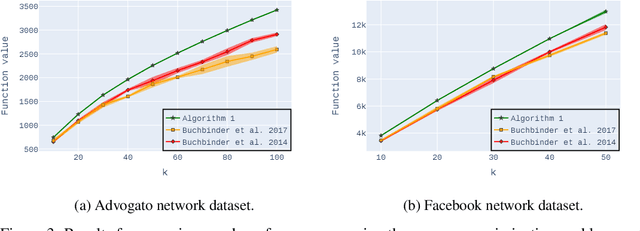
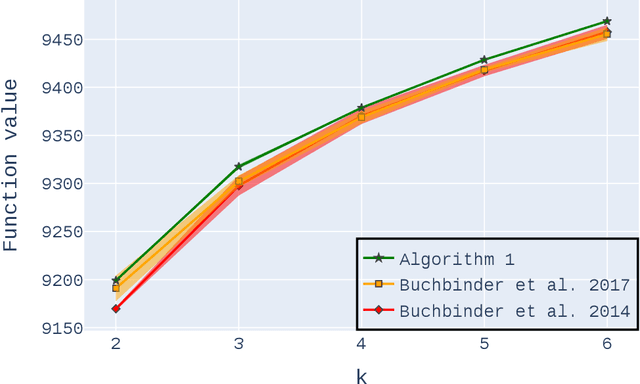
Non-monotone constrained submodular maximization plays a crucial role in various machine learning applications. However, existing algorithms often struggle with a trade-off between approximation guarantees and practical efficiency. The current state-of-the-art is a recent $0.401$-approximation algorithm, but its computational complexity makes it highly impractical. The best practical algorithms for the problem only guarantee $1/e$-approximation. In this work, we present a novel algorithm for submodular maximization subject to a cardinality constraint that combines a guarantee of $0.385$-approximation with a low and practical query complexity of $O(n+k^2)$. Furthermore, we evaluate the empirical performance of our algorithm in experiments based on various machine learning applications, including Movie Recommendation, Image Summarization, and more. These experiments demonstrate the efficacy of our approach.
Bridging the Gap Between General and Down-Closed Convex Sets in Submodular Maximization
Jan 17, 2024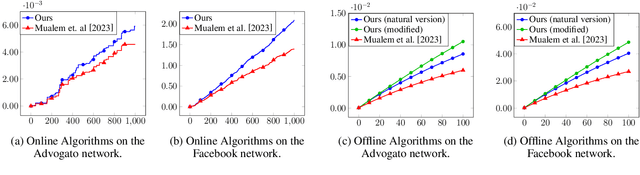
Optimization of DR-submodular functions has experienced a notable surge in significance in recent times, marking a pivotal development within the domain of non-convex optimization. Motivated by real-world scenarios, some recent works have delved into the maximization of non-monotone DR-submodular functions over general (not necessarily down-closed) convex set constraints. Up to this point, these works have all used the minimum $\ell_\infty$ norm of any feasible solution as a parameter. Unfortunately, a recent hardness result due to Mualem \& Feldman~\cite{mualem2023resolving} shows that this approach cannot yield a smooth interpolation between down-closed and non-down-closed constraints. In this work, we suggest novel offline and online algorithms that provably provide such an interpolation based on a natural decomposition of the convex body constraint into two distinct convex bodies: a down-closed convex body and a general convex body. We also empirically demonstrate the superiority of our proposed algorithms across three offline and two online applications.
ORBSLAM3-Enhanced Autonomous Toy Drones: Pioneering Indoor Exploration
Dec 20, 2023Navigating toy drones through uncharted GPS-denied indoor spaces poses significant difficulties due to their reliance on GPS for location determination. In such circumstances, the necessity for achieving proper navigation is a primary concern. In response to this formidable challenge, we introduce a real-time autonomous indoor exploration system tailored for drones equipped with a monocular \emph{RGB} camera. Our system utilizes \emph{ORB-SLAM3}, a state-of-the-art vision feature-based SLAM, to handle both the localization of toy drones and the mapping of unmapped indoor terrains. Aside from the practicability of \emph{ORB-SLAM3}, the generated maps are represented as sparse point clouds, making them prone to the presence of outlier data. To address this challenge, we propose an outlier removal algorithm with provable guarantees. Furthermore, our system incorporates a novel exit detection algorithm, ensuring continuous exploration by the toy drone throughout the unfamiliar indoor environment. We also transform the sparse point to ensure proper path planning using existing path planners. To validate the efficacy and efficiency of our proposed system, we conducted offline and real-time experiments on the autonomous exploration of indoor spaces. The results from these endeavors demonstrate the effectiveness of our methods.
Dataset Distillation Meets Provable Subset Selection
Jul 16, 2023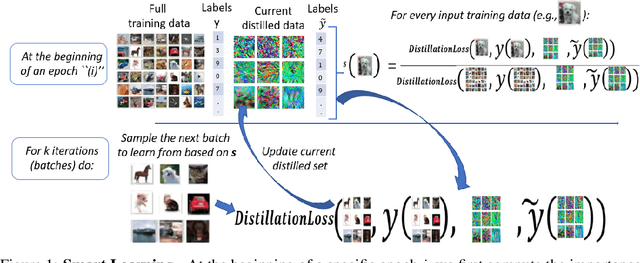
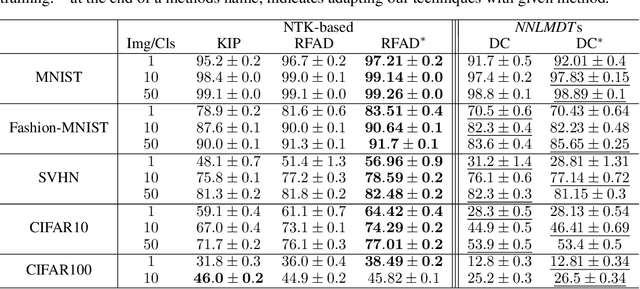
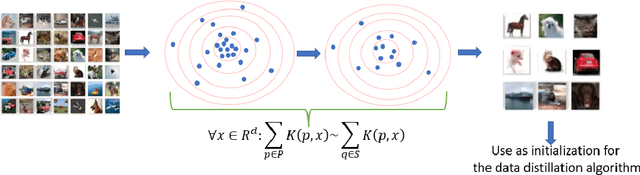
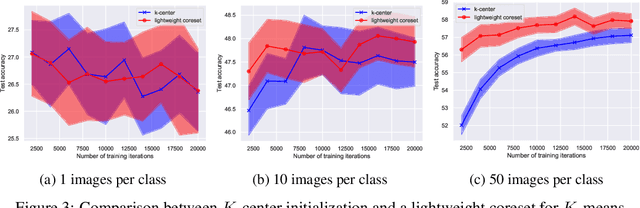
Deep learning has grown tremendously over recent years, yielding state-of-the-art results in various fields. However, training such models requires huge amounts of data, increasing the computational time and cost. To address this, dataset distillation was proposed to compress a large training dataset into a smaller synthetic one that retains its performance -- this is usually done by (1) uniformly initializing a synthetic set and (2) iteratively updating/learning this set according to a predefined loss by uniformly sampling instances from the full data. In this paper, we improve both phases of dataset distillation: (1) we present a provable, sampling-based approach for initializing the distilled set by identifying important and removing redundant points in the data, and (2) we further merge the idea of data subset selection with dataset distillation, by training the distilled set on ``important'' sampled points during the training procedure instead of randomly sampling the next batch. To do so, we define the notion of importance based on the relative contribution of instances with respect to two different loss functions, i.e., one for the initialization phase (a kernel fitting function for kernel ridge regression and $K$-means based loss function for any other distillation method), and the relative cross-entropy loss (or any other predefined loss) function for the training phase. Finally, we provide experimental results showing how our method can latch on to existing dataset distillation techniques and improve their performance.
On the Size and Approximation Error of Distilled Sets
May 23, 2023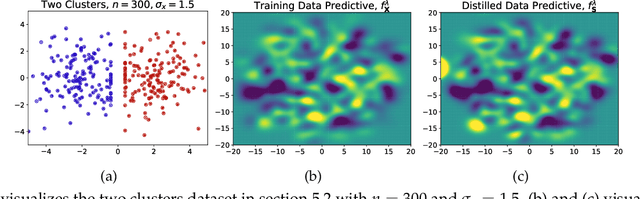
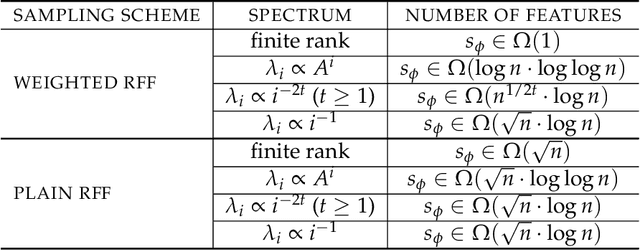
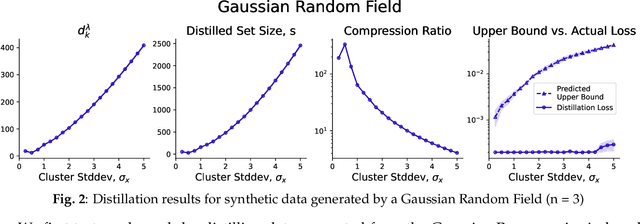
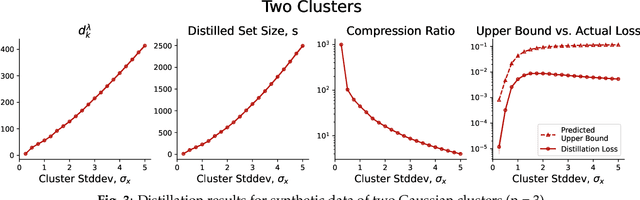
Dataset Distillation is the task of synthesizing small datasets from large ones while still retaining comparable predictive accuracy to the original uncompressed dataset. Despite significant empirical progress in recent years, there is little understanding of the theoretical limitations/guarantees of dataset distillation, specifically, what excess risk is achieved by distillation compared to the original dataset, and how large are distilled datasets? In this work, we take a theoretical view on kernel ridge regression (KRR) based methods of dataset distillation such as Kernel Inducing Points. By transforming ridge regression in random Fourier features (RFF) space, we provide the first proof of the existence of small (size) distilled datasets and their corresponding excess risk for shift-invariant kernels. We prove that a small set of instances exists in the original input space such that its solution in the RFF space coincides with the solution of the original data. We further show that a KRR solution can be generated using this distilled set of instances which gives an approximation towards the KRR solution optimized on the full input data. The size of this set is linear in the dimension of the RFF space of the input set or alternatively near linear in the number of effective degrees of freedom, which is a function of the kernel, number of datapoints, and the regularization parameter $\lambda$. The error bound of this distilled set is also a function of $\lambda$. We verify our bounds analytically and empirically.
AutoCoreset: An Automatic Practical Coreset Construction Framework
May 19, 2023



A coreset is a tiny weighted subset of an input set, that closely resembles the loss function, with respect to a certain set of queries. Coresets became prevalent in machine learning as they have shown to be advantageous for many applications. While coreset research is an active research area, unfortunately, coresets are constructed in a problem-dependent manner, where for each problem, a new coreset construction algorithm is usually suggested, a process that may take time or may be hard for new researchers in the field. Even the generic frameworks require additional (problem-dependent) computations or proofs to be done by the user. Besides, many problems do not have (provable) small coresets, limiting their applicability. To this end, we suggest an automatic practical framework for constructing coresets, which requires (only) the input data and the desired cost function from the user, without the need for any other task-related computation to be done by the user. To do so, we reduce the problem of approximating a loss function to an instance of vector summation approximation, where the vectors we aim to sum are loss vectors of a specific subset of the queries, such that we aim to approximate the image of the function on this subset. We show that while this set is limited, the coreset is quite general. An extensive experimental study on various machine learning applications is also conducted. Finally, we provide a ``plug and play" style implementation, proposing a user-friendly system that can be easily used to apply coresets for many problems. Full open source code can be found at \href{https://github.com/alaamaalouf/AutoCoreset}{\text{https://github.com/alaamaalouf/AutoCoreset}}. We believe that these contributions enable future research and easier use and applications of coresets.
Provable Data Subset Selection For Efficient Neural Network Training
Mar 09, 2023
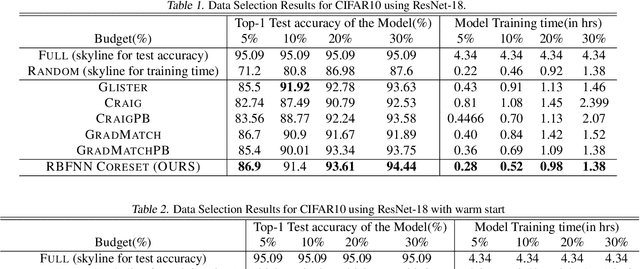
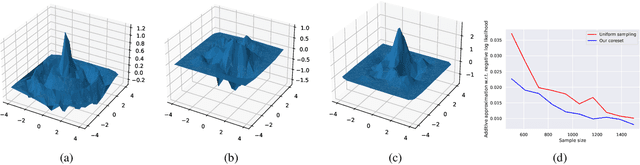
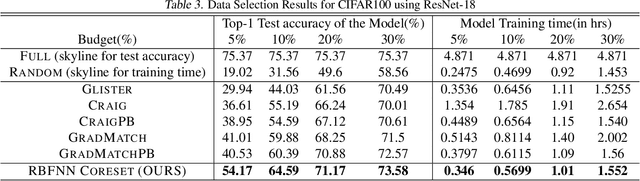
Radial basis function neural networks (\emph{RBFNN}) are {well-known} for their capability to approximate any continuous function on a closed bounded set with arbitrary precision given enough hidden neurons. In this paper, we introduce the first algorithm to construct coresets for \emph{RBFNNs}, i.e., small weighted subsets that approximate the loss of the input data on any radial basis function network and thus approximate any function defined by an \emph{RBFNN} on the larger input data. In particular, we construct coresets for radial basis and Laplacian loss functions. We then use our coresets to obtain a provable data subset selection algorithm for training deep neural networks. Since our coresets approximate every function, they also approximate the gradient of each weight in a neural network, which is a particular function on the input. We then perform empirical evaluations on function approximation and dataset subset selection on popular network architectures and data sets, demonstrating the efficacy and accuracy of our coreset construction.
An Efficient Drifters Deployment Strategy to Evaluate Water Current Velocity Fields
Jan 10, 2023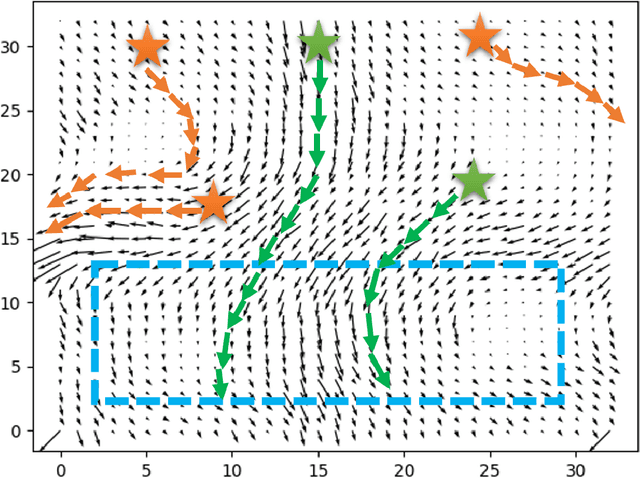



Water current prediction is essential for understanding ecosystems, and to shed light on the role of the ocean in the global climate context. Solutions vary from physical modeling, and long-term observations, to short-term measurements. In this paper, we consider a common approach for water current prediction that uses Lagrangian floaters for water current prediction by interpolating the trajectory of the elements to reflect the velocity field. Here, an important aspect that has not been addressed before is where to initially deploy the drifting elements such that the acquired velocity field would efficiently represent the water current. To that end, we use a clustering approach that relies on a physical model of the velocity field. Our method segments the modeled map and determines the deployment locations as those that will lead the floaters to 'visit' the center of the different segments. This way, we validate that the area covered by the floaters will capture the in-homogeneously in the velocity field. Exploration over a dataset of velocity field maps that span over a year demonstrates the applicability of our approach, and shows a considerable improvement over the common approach of uniformly randomly choosing the initial deployment sites. Finally, our implementation code can be found in [1].
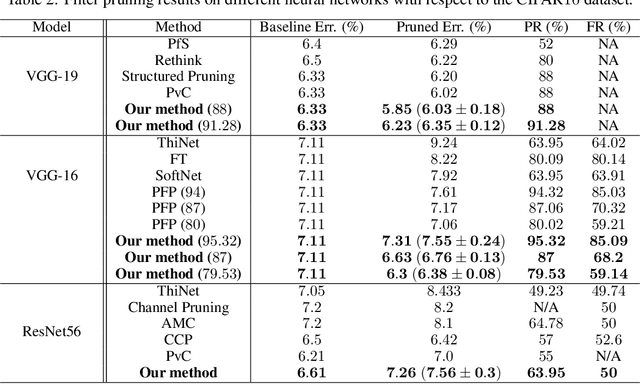
Pruning Neural Networks via Coresets and Convex Geometry: Towards No Assumptions
Sep 18, 2022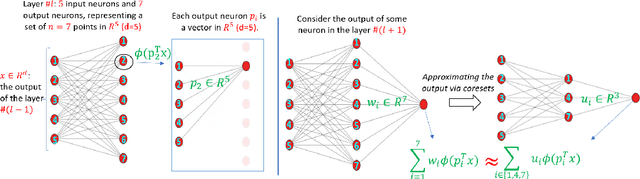
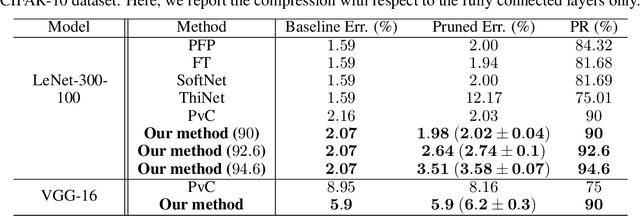
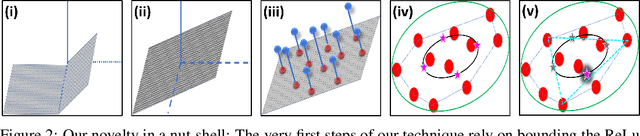
Pruning is one of the predominant approaches for compressing deep neural networks (DNNs). Lately, coresets (provable data summarizations) were leveraged for pruning DNNs, adding the advantage of theoretical guarantees on the trade-off between the compression rate and the approximation error. However, coresets in this domain were either data-dependent or generated under restrictive assumptions on both the model's weights and inputs. In real-world scenarios, such assumptions are rarely satisfied, limiting the applicability of coresets. To this end, we suggest a novel and robust framework for computing such coresets under mild assumptions on the model's weights and without any assumption on the training data. The idea is to compute the importance of each neuron in each layer with respect to the output of the following layer. This is achieved by a combination of L\"{o}wner ellipsoid and Caratheodory theorem. Our method is simultaneously data-independent, applicable to various networks and datasets (due to the simplified assumptions), and theoretically supported. Experimental results show that our method outperforms existing coreset based neural pruning approaches across a wide range of networks and datasets. For example, our method achieved a $62\%$ compression rate on ResNet50 on ImageNet with $1.09\%$ drop in accuracy.
New Coresets for Projective Clustering and Applications
Mar 08, 2022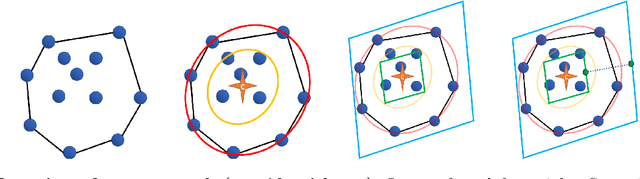
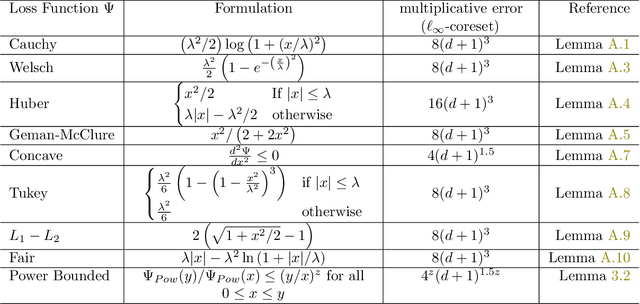
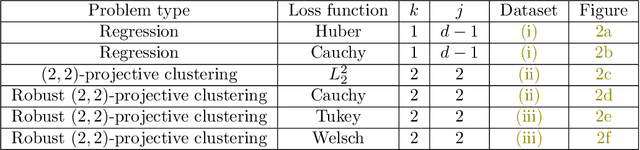
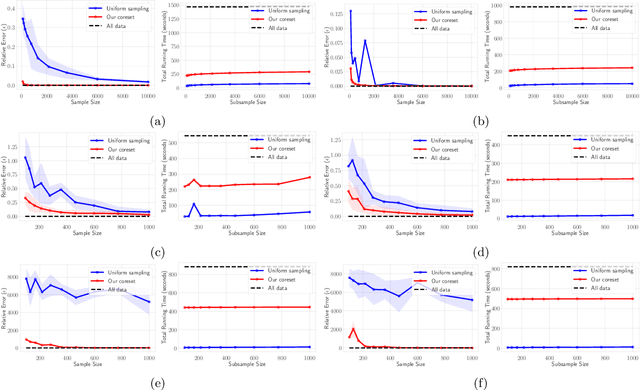
$(j,k)$-projective clustering is the natural generalization of the family of $k$-clustering and $j$-subspace clustering problems. Given a set of points $P$ in $\mathbb{R}^d$, the goal is to find $k$ flats of dimension $j$, i.e., affine subspaces, that best fit $P$ under a given distance measure. In this paper, we propose the first algorithm that returns an $L_\infty$ coreset of size polynomial in $d$. Moreover, we give the first strong coreset construction for general $M$-estimator regression. Specifically, we show that our construction provides efficient coreset constructions for Cauchy, Welsch, Huber, Geman-McClure, Tukey, $L_1-L_2$, and Fair regression, as well as general concave and power-bounded loss functions. Finally, we provide experimental results based on real-world datasets, showing the efficacy of our approach.