 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEarly Risk Stratification of Dosing Errors in Clinical Trials Using Machine Learning
Feb 25, 2026Objective: The objective of this study is to develop a machine learning (ML)-based framework for early risk stratification of clinical trials (CTs) according to their likelihood of exhibiting a high rate of dosing errors, using information available prior to trial initiation. Materials and Methods: We constructed a dataset from ClinicalTrials.gov comprising 42,112 CTs. Structured, semi-structured trial data, and unstructured protocol-related free-text data were extracted. CTs were assigned binary labels indicating elevated dosing error rate, derived from adverse event reports, MedDRA terminology, and Wilson confidence intervals. We evaluated an XGBoost model trained on structured features, a ClinicalModernBERT model using textual data, and a simple late-fusion model combining both modalities. Post-hoc probability calibration was applied to enable interpretable, trial-level risk stratification. Results: The late-fusion model achieved the highest AUC-ROC (0.862). Beyond discrimination, calibrated outputs enabled robust stratification of CTs into predefined risk categories. The proportion of trials labeled as having an excessively high dosing error rate increased monotonically across higher predicted risk groups and aligned with the corresponding predicted probability ranges. Discussion: These findings indicate that dosing error risk can be anticipated at the trial level using pre-initiation information. Probability calibration was essential for translating model outputs into reliable and interpretable risk categories, while simple multimodal integration yielded performance gains without requiring complex architectures. Conclusion: This study introduces a reproducible and scalable ML framework for early, trial-level risk stratification of CTs at risk of high dosing error rates, supporting proactive, risk-based quality management in clinical research.
Privacy-Preserving Near Neighbor Search via Sparse Coding with Ambiguation
Feb 08, 2021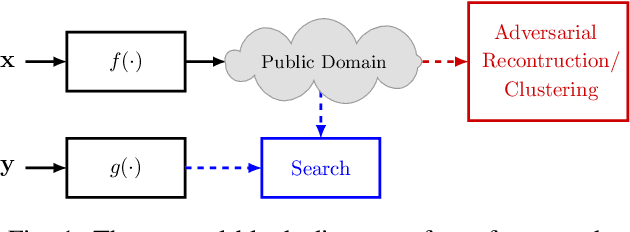
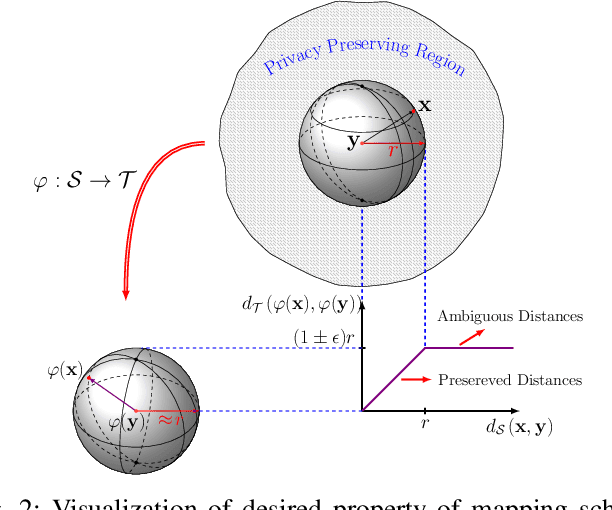
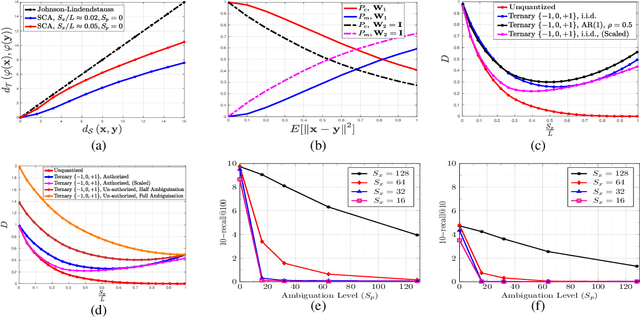

In this paper, we propose a framework for privacy-preserving approximate near neighbor search via stochastic sparsifying encoding. The core of the framework relies on sparse coding with ambiguation (SCA) mechanism that introduces the notion of inherent shared secrecy based on the support intersection of sparse codes. This approach is `fairness-aware', in the sense that any point in the neighborhood has an equiprobable chance to be chosen. Our approach can be applied to raw data, latent representation of autoencoders, and aggregated local descriptors. The proposed method is tested on both synthetic i.i.d data and real large-scale image databases.
Privacy-Preserving Image Sharing via Sparsifying Layers on Convolutional Groups
Feb 04, 2020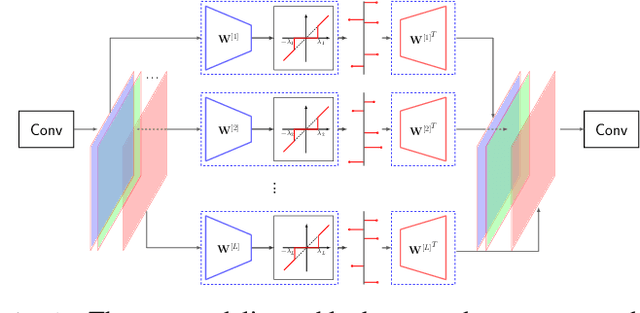



We propose a practical framework to address the problem of privacy-aware image sharing in large-scale setups. We argue that, while compactness is always desired at scale, this need is more severe when trying to furthermore protect the privacy-sensitive content. We therefore encode images, such that, from one hand, representations are stored in the public domain without paying the huge cost of privacy protection, but ambiguated and hence leaking no discernible content from the images, unless a combinatorially-expensive guessing mechanism is available for the attacker. From the other hand, authorized users are provided with very compact keys that can easily be kept secure. This can be used to disambiguate and reconstruct faithfully the corresponding access-granted images. We achieve this with a convolutional autoencoder of our design, where feature maps are passed independently through sparsifying transformations, providing multiple compact codes, each responsible for reconstructing different attributes of the image. The framework is tested on a large-scale database of images with public implementation available.
$ρ$-VAE: Autoregressive parametrization of the VAE encoder
Sep 13, 2019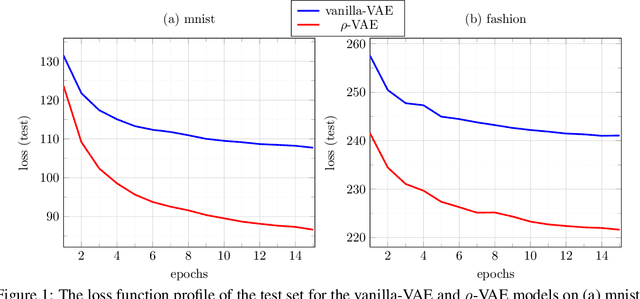

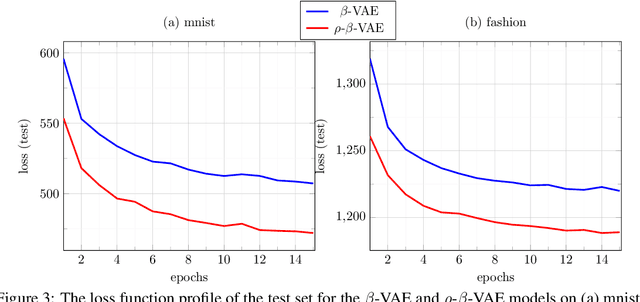
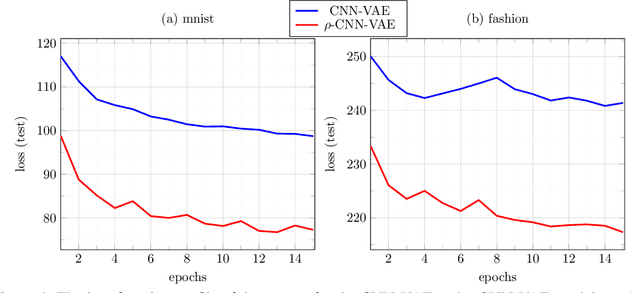
We make a minimal, but very effective alteration to the VAE model. This is about a drop-in replacement for the (sample-dependent) approximate posterior to change it from the standard white Gaussian with diagonal covariance to the first-order autoregressive Gaussian. We argue that this is a more reasonable choice to adopt for natural signals like images, as it does not force the existing correlation in the data to disappear in the posterior. Moreover, it allows more freedom for the approximate posterior to match the true posterior. This allows for the repararametrization trick, as well as the KL-divergence term to still have closed-form expressions, obviating the need for its sample-based estimation. Although providing more freedom to adapt to correlated distributions, our parametrization has even less number of parameters than the diagonal covariance, as it requires only two scalars, $\rho$ and $s$, to characterize correlation and scaling, respectively. As validated by the experiments, our proposition noticeably and consistently improves the quality of image generation in a plug-and-play manner, needing no further parameter tuning, and across all setups. The code to reproduce our experiments is available at \url{https://github.com/sssohrab/rho_VAE/}.
Learning to compress and search visual data in large-scale systems
Jan 24, 2019
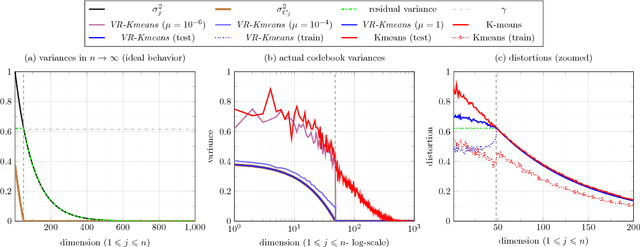

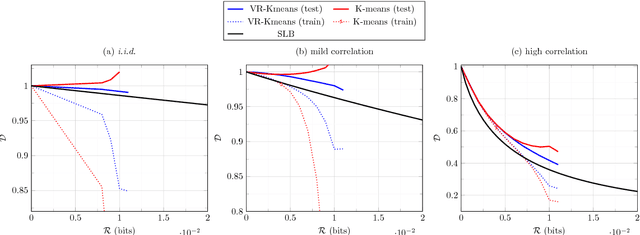
The problem of high-dimensional and large-scale representation of visual data is addressed from an unsupervised learning perspective. The emphasis is put on discrete representations, where the description length can be measured in bits and hence the model capacity can be controlled. The algorithmic infrastructure is developed based on the synthesis and analysis prior models whose rate-distortion properties, as well as capacity vs. sample complexity trade-offs are carefully optimized. These models are then extended to multi-layers, namely the RRQ and the ML-STC frameworks, where the latter is further evolved as a powerful deep neural network architecture with fast and sample-efficient training and discrete representations. For the developed algorithms, three important applications are developed. First, the problem of large-scale similarity search in retrieval systems is addressed, where a double-stage solution is proposed leading to faster query times and shorter database storage. Second, the problem of learned image compression is targeted, where the proposed models can capture more redundancies from the training images than the conventional compression codecs. Finally, the proposed algorithms are used to solve ill-posed inverse problems. In particular, the problems of image denoising and compressive sensing are addressed with promising results.
Network Learning with Local Propagation
May 20, 2018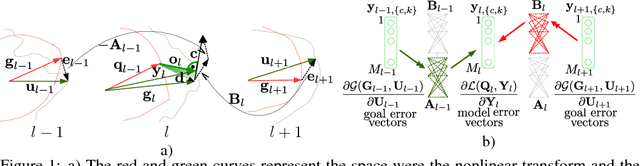
This paper presents a locally decoupled network parameter learning with local propagation. Three elements are taken into account: (i) sets of nonlinear transforms that describe the representations at all nodes, (ii) a local objective at each node related to the corresponding local representation goal, and (iii) a local propagation model that relates the nonlinear error vectors at each node with the goal error vectors from the directly connected nodes. The modeling concepts (i), (ii) and (iii) offer several advantages, including (a) a unified learning principle for any network that is represented as a graph, (b) understanding and interpretation of the local and the global learning dynamics, (c) decoupled and parallel parameter learning, (d) a possibility for learning in infinitely long, multi-path and multi-goal networks. Numerical experiments validate the potential of the learning principle. The preliminary results show advantages in comparison to the state-of-the-art methods, w.r.t. the learning time and the network size while having comparable recognition accuracy.
A multi-layer network based on Sparse Ternary Codes for universal vector compression
Oct 31, 2017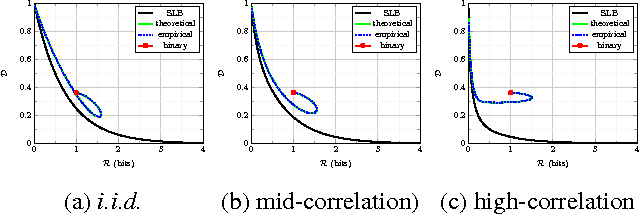
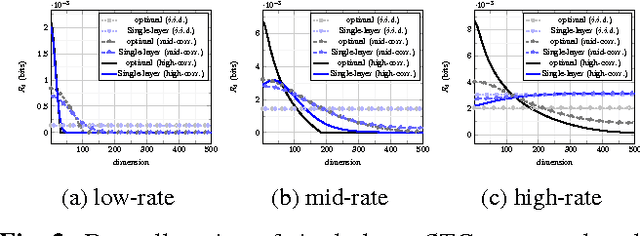
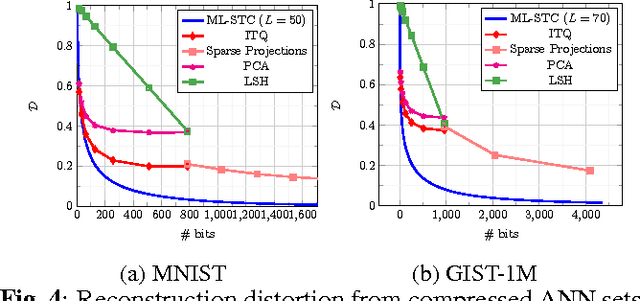
We present the multi-layer extension of the Sparse Ternary Codes (STC) for fast similarity search where we focus on the reconstruction of the database vectors from the ternary codes. To consider the trade-offs between the compactness of the STC and the quality of the reconstructed vectors, we study the rate-distortion behavior of these codes under different setups. We show that a single-layer code cannot achieve satisfactory results at high rates. Therefore, we extend the concept of STC to multiple layers and design the ML-STC, a codebook-free system that successively refines the reconstruction of the residuals of previous layers. While the ML-STC keeps the sparse ternary structure of the single-layer STC and hence is suitable for fast similarity search in large-scale databases, we show its superior rate-distortion performance on both model-based synthetic data and public large-scale databases, as compared to several binary hashing methods.
A multi-layer image representation using Regularized Residual Quantization: application to compression and denoising
Jul 07, 2017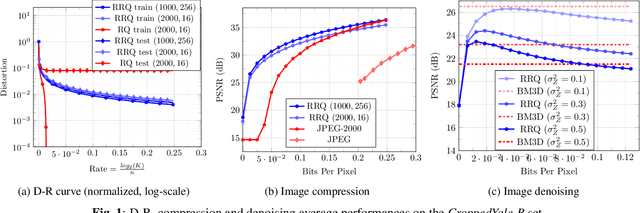

A learning-based framework for representation of domain-specific images is proposed where joint compression and denoising can be done using a VQ-based multi-layer network. While it learns to compress the images from a training set, the compression performance is very well generalized on images from a test set. Moreover, when fed with noisy versions of the test set, since it has priors from clean images, the network also efficiently denoises the test images during the reconstruction. The proposed framework is a regularized version of the Residual Quantization (RQ) where at each stage, the quantization error from the previous stage is further quantized. Instead of codebook learning from the k-means which over-trains for high-dimensional vectors, we show that only generating the codewords from a random, but properly regularized distribution suffices to compress the images globally and without the need to resort to patch-based division of images. The experiments are done on the \textit{CroppedYale-B} set of facial images and the method is compared with the JPEG-2000 codec for compression and BM3D for denoising, showing promising results.
Regularized Residual Quantization: a multi-layer sparse dictionary learning approach
May 01, 2017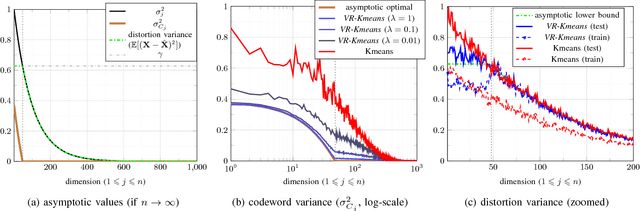



The Residual Quantization (RQ) framework is revisited where the quantization distortion is being successively reduced in multi-layers. Inspired by the reverse-water-filling paradigm in rate-distortion theory, an efficient regularization on the variances of the codewords is introduced which allows to extend the RQ for very large numbers of layers and also for high dimensional data, without getting over-trained. The proposed Regularized Residual Quantization (RRQ) results in multi-layer dictionaries which are additionally sparse, thanks to the soft-thresholding nature of the regularization when applied to variance-decaying data which can arise from de-correlating transformations applied to correlated data. Furthermore, we also propose a general-purpose pre-processing for natural images which makes them suitable for such quantization. The RRQ framework is first tested on synthetic variance-decaying data to show its efficiency in quantization of high-dimensional data. Next, we use the RRQ in super-resolution of a database of facial images where it is shown that low-resolution facial images from the test set quantized with codebooks trained on high-resolution images from the training set show relevant high-frequency content when reconstructed with those codebooks.
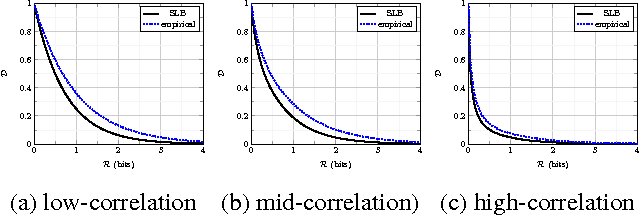
Sparse Ternary Codes for similarity search have higher coding gain than dense binary codes
Apr 25, 2017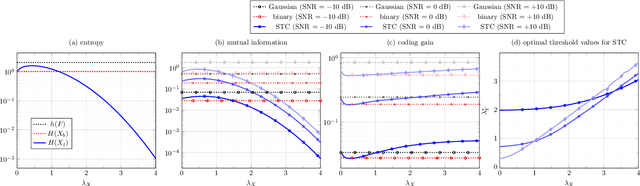
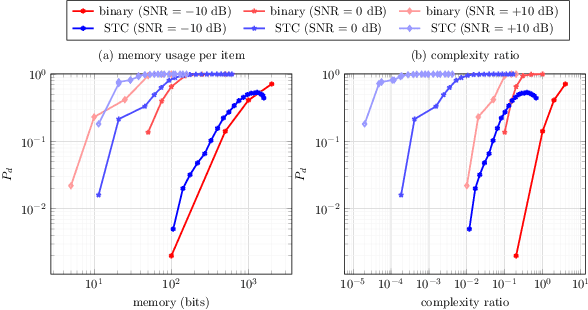
This paper addresses the problem of Approximate Nearest Neighbor (ANN) search in pattern recognition where feature vectors in a database are encoded as compact codes in order to speed-up the similarity search in large-scale databases. Considering the ANN problem from an information-theoretic perspective, we interpret it as an encoding, which maps the original feature vectors to a less entropic sparse representation while requiring them to be as informative as possible. We then define the coding gain for ANN search using information-theoretic measures. We next show that the classical approach to this problem, which consists of binarization of the projected vectors is sub-optimal. Instead, a properly designed ternary encoding achieves higher coding gains and lower complexity.