 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSaliency Diversified Deep Ensemble for Robustness to Adversaries
Dec 07, 2021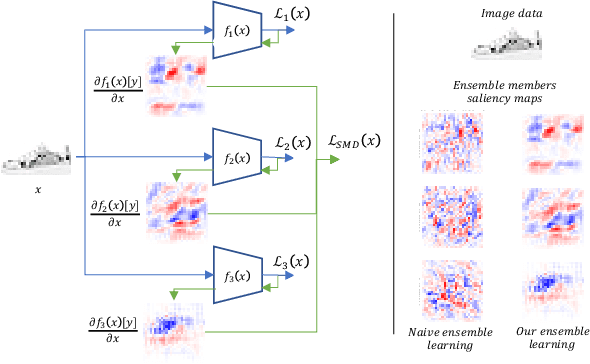

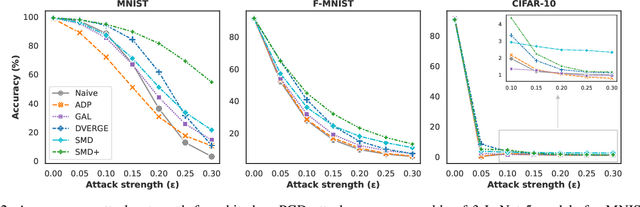

Deep learning models have shown incredible performance on numerous image recognition, classification, and reconstruction tasks. Although very appealing and valuable due to their predictive capabilities, one common threat remains challenging to resolve. A specifically trained attacker can introduce malicious input perturbations to fool the network, thus causing potentially harmful mispredictions. Moreover, these attacks can succeed when the adversary has full access to the target model (white-box) and even when such access is limited (black-box setting). The ensemble of models can protect against such attacks but might be brittle under shared vulnerabilities in its members (attack transferability). To that end, this work proposes a novel diversity-promoting learning approach for the deep ensembles. The idea is to promote saliency map diversity (SMD) on ensemble members to prevent the attacker from targeting all ensemble members at once by introducing an additional term in our learning objective. During training, this helps us minimize the alignment between model saliencies to reduce shared member vulnerabilities and, thus, increase ensemble robustness to adversaries. We empirically show a reduced transferability between ensemble members and improved performance compared to the state-of-the-art ensemble defense against medium and high strength white-box attacks. In addition, we demonstrate that our approach combined with existing methods outperforms state-of-the-art ensemble algorithms for defense under white-box and black-box attacks.
Self-Supervised Representation Learning on Neural Network Weights for Model Characteristic Prediction
Nov 03, 2021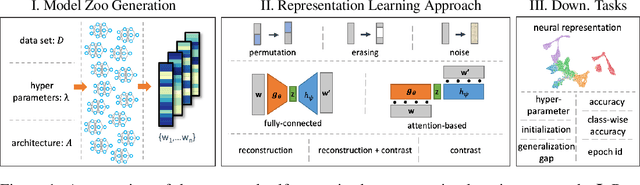
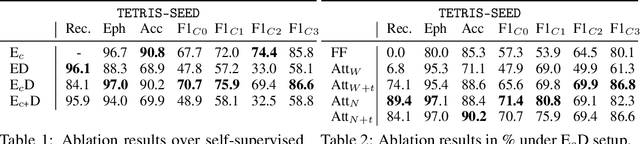
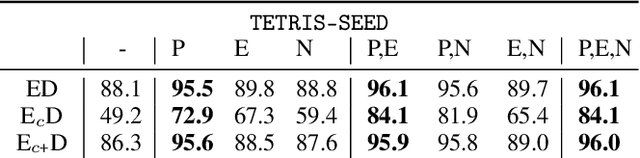
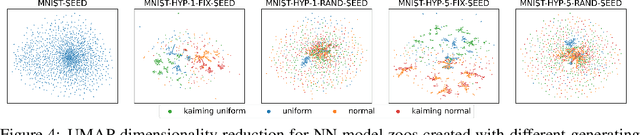
Self-Supervised Learning (SSL) has been shown to learn useful and information-preserving representations. Neural Networks (NNs) are widely applied, yet their weight space is still not fully understood. Therefore, we propose to use SSL to learn neural representations of the weights of populations of NNs. To that end, we introduce domain specific data augmentations and an adapted attention architecture. Our empirical evaluation demonstrates that self-supervised representation learning in this domain is able to recover diverse NN model characteristics. Further, we show that the proposed learned representations outperform prior work for predicting hyper-parameters, test accuracy, and generalization gap as well as transfer to out-of-distribution settings.
Zero-shot Voice Conversion via Self-supervised Prosody Representation Learning
Oct 27, 2021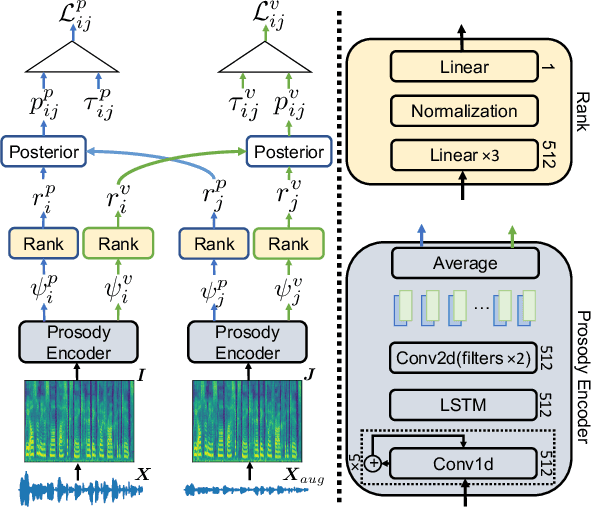
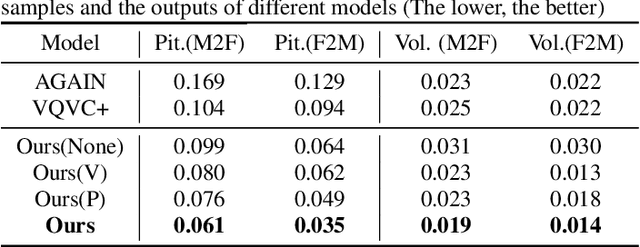
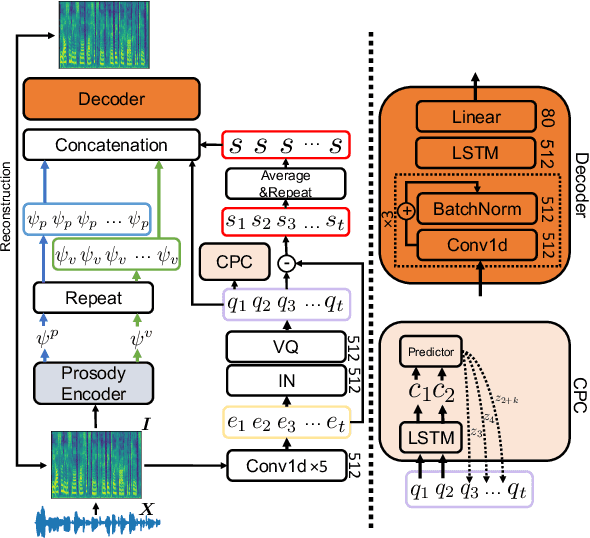
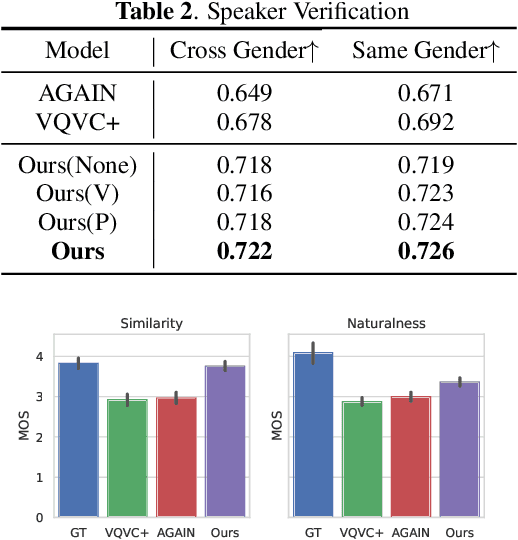
Voice Conversion (VC) for unseen speakers, also known as zero-shot VC, is an attractive topic due to its usefulness in real use-case scenarios. Recent work in this area made progress with disentanglement methods that separate utterance content and speaker characteristics. Although crucial, extracting disentangled prosody characteristics for unseen speakers remains an open issue. In this paper, we propose a novel self-supervised approach to effectively learn the prosody characteristics. Then, we use the learned prosodic representations to train our VC model for zero-shot conversion. Our evaluation demonstrates that we can efficiently extract disentangled prosody representation. Moreover, we show improved performance compared to the state-of-the-art zero-shot VC models.
Privacy-Preserving Near Neighbor Search via Sparse Coding with Ambiguation
Feb 08, 2021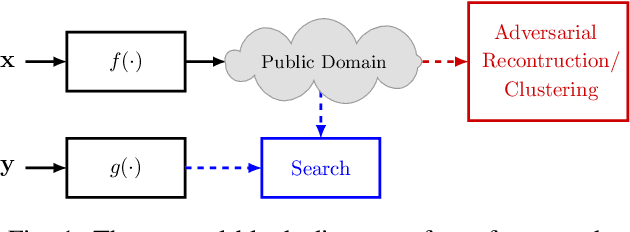
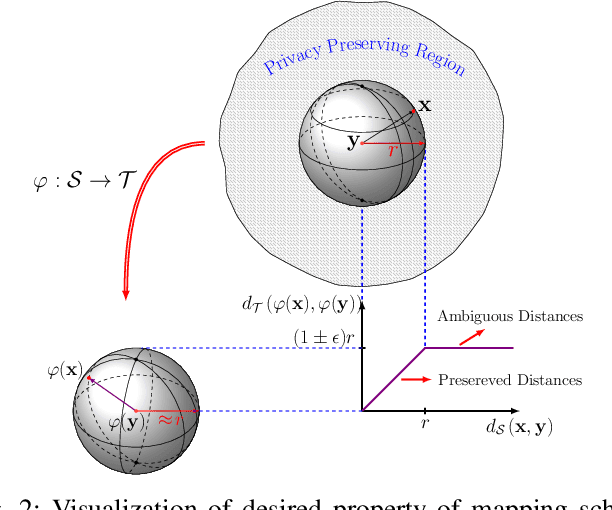
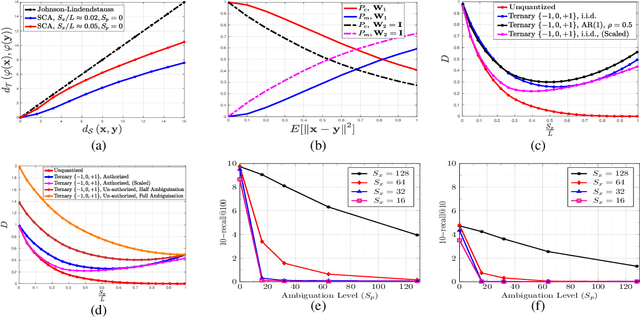

In this paper, we propose a framework for privacy-preserving approximate near neighbor search via stochastic sparsifying encoding. The core of the framework relies on sparse coding with ambiguation (SCA) mechanism that introduces the notion of inherent shared secrecy based on the support intersection of sparse codes. This approach is `fairness-aware', in the sense that any point in the neighborhood has an equiprobable chance to be chosen. Our approach can be applied to raw data, latent representation of autoencoders, and aggregated local descriptors. The proposed method is tested on both synthetic i.i.d data and real large-scale image databases.
Unsupervised Feature Learning for Event Data: Direct vs Inverse Problem Formulation
Sep 30, 2020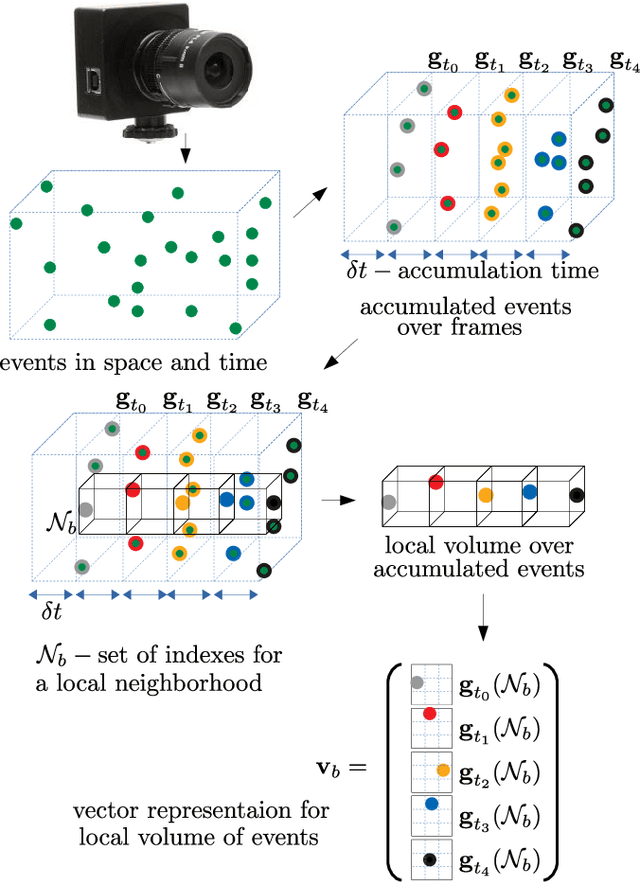
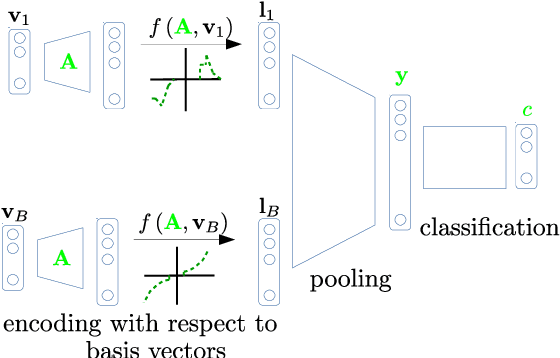
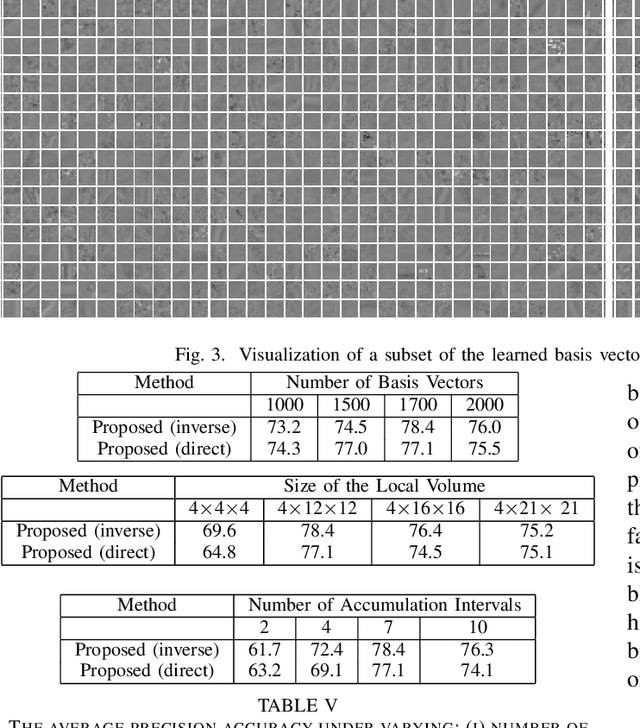
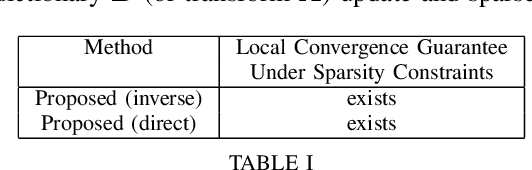
Event-based cameras record an asynchronous stream of per-pixel brightness changes. As such, they have numerous advantages over the standard frame-based cameras, including high temporal resolution, high dynamic range, and no motion blur. Due to the asynchronous nature, efficient learning of compact representation for event data is challenging. While it remains not explored the extent to which the spatial and temporal event "information" is useful for pattern recognition tasks. In this paper, we focus on single-layer architectures. We analyze the performance of two general problem formulations: the direct and the inverse, for unsupervised feature learning from local event data (local volumes of events described in space-time). We identify and show the main advantages of each approach. Theoretically, we analyze guarantees for an optimal solution, possibility for asynchronous, parallel parameter update, and the computational complexity. We present numerical experiments for object recognition. We evaluate the solution under the direct and the inverse problem and give a comparison with the state-of-the-art methods. Our empirical results highlight the advantages of both approaches for representation learning from event data. We show improvements of up to 9 % in the recognition accuracy compared to the state-of-the-art methods from the same class of methods.
Online Weight-adaptive Nonlinear Model Predictive Control
Aug 06, 2020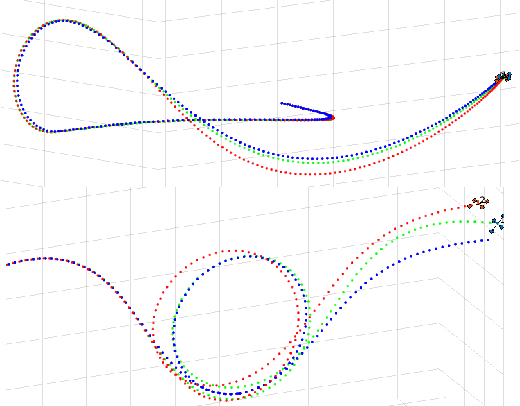


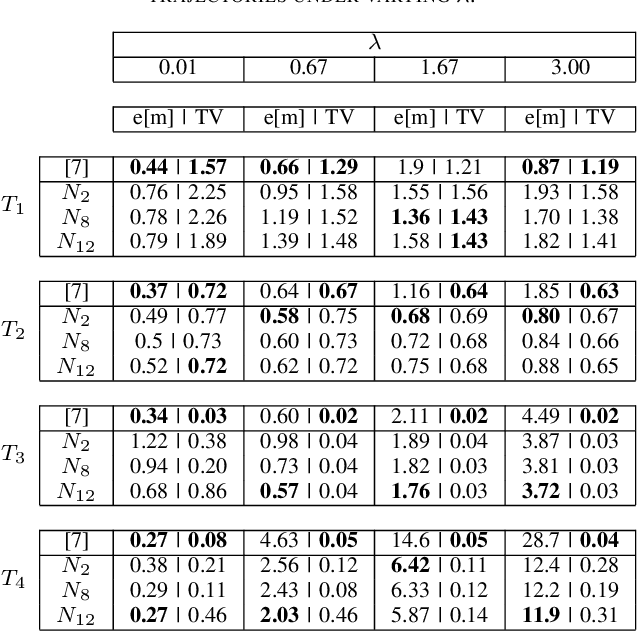
Nonlinear Model Predictive Control (NMPC) is a powerful and widely used technique for nonlinear dynamic process control under constraints. In NMPC, the state and control weights of the corresponding state and control costs are commonly selected based on human-expert knowledge, which usually reflects the acceptable stability in practice. Although broadly used, this approach might not be optimal for the execution of a trajectory with the lowest positional error and sufficiently "smooth" changes in the predicted controls. Furthermore, NMPC with an online weight update strategy for fast, agile, and precise unmanned aerial vehicle navigation, has not been studied extensively. To this end, we propose a novel control problem formulation that allows online updates of the state and control weights. As a solution, we present an algorithm that consists of two alternating stages: (i) state and command variable prediction and (ii) weights update. We present a numerical evaluation with a comparison and analysis of different trade-offs for the problem of quadrotor navigation. Our computer simulation results show improvements of up to 70% in the accuracy of the executed trajectory compared to the standard solution of NMPC with fixed weights.
Network Parameter Learning Using Nonlinear Transforms, Local Representation Goals and Local Propagation Constraints
Jan 31, 2019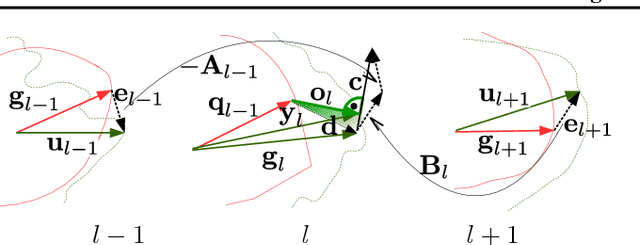
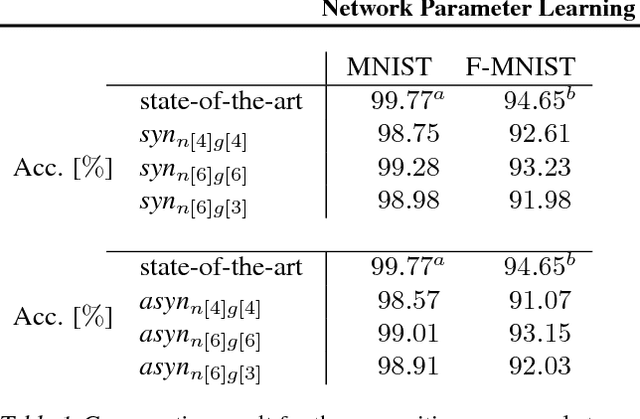

In this paper, we introduce a novel concept for learning of the parameters in a neural network. Our idea is grounded on modeling a learning problem that addresses a trade-off between (i) satisfying local objectives at each node and (ii) achieving desired data propagation through the network under (iii) local propagation constraints. We consider two types of nonlinear transforms which describe the network representations. One of the nonlinear transforms serves as activation function. The other one enables a locally adjusted, deviation corrective components to be included in the update of the network weights in order to enable attaining target specific representations at the last network node. Our learning principle not only provides insight into the understanding and the interpretation of the learning dynamics, but it offers theoretical guarantees over decoupled and parallel parameter estimation strategy that enables learning in synchronous and asynchronous mode. Numerical experiments validate the potential of our approach on image recognition task. The preliminary results show advantages in comparison to the state-of-the-art methods, w.r.t. the learning time and the network size while having competitive recognition accuracy.
Clustering with Jointly Learned Nonlinear Transforms Over Discriminating Min-Max Similarity/Dissimilarity Assignment
Jan 30, 2019
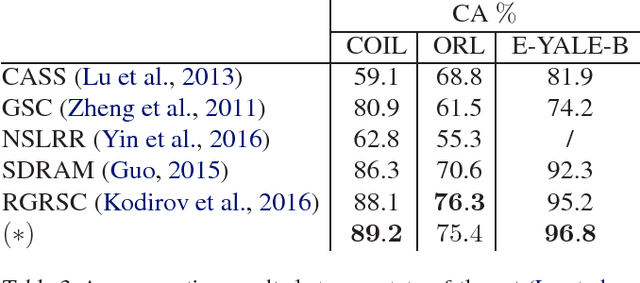
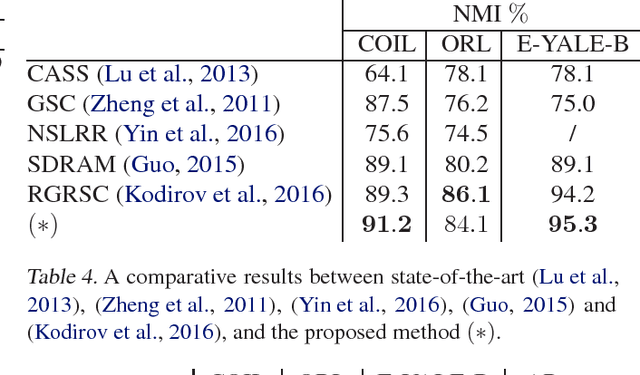
This paper presents a novel clustering concept that is based on jointly learned nonlinear transforms (NTs) with priors on the information loss and the discrimination. We introduce a clustering principle that is based on evaluation of a parametric min-max measure for the discriminative prior. The decomposition of the prior measure allows to break down the assignment into two steps. In the first step, we apply NTs to a data point in order to produce candidate NT representations. In the second step, we preform the actual assignment by evaluating the parametric measure over the candidate NT representations. Numerical experiments on image clustering task validate the potential of the proposed approach. The evaluation shows advantages in comparison to the state-of-the-art clustering methods.
Network Learning with Local Propagation
May 20, 2018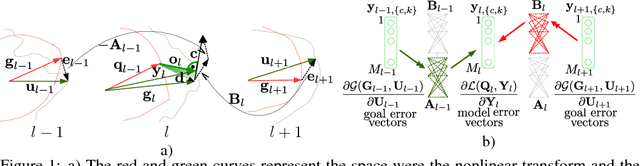
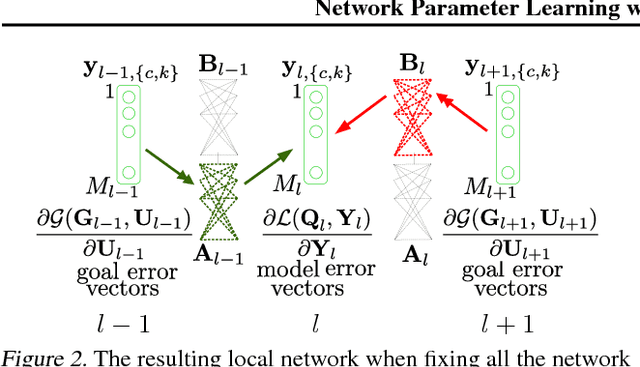
This paper presents a locally decoupled network parameter learning with local propagation. Three elements are taken into account: (i) sets of nonlinear transforms that describe the representations at all nodes, (ii) a local objective at each node related to the corresponding local representation goal, and (iii) a local propagation model that relates the nonlinear error vectors at each node with the goal error vectors from the directly connected nodes. The modeling concepts (i), (ii) and (iii) offer several advantages, including (a) a unified learning principle for any network that is represented as a graph, (b) understanding and interpretation of the local and the global learning dynamics, (c) decoupled and parallel parameter learning, (d) a possibility for learning in infinitely long, multi-path and multi-goal networks. Numerical experiments validate the potential of the learning principle. The preliminary results show advantages in comparison to the state-of-the-art methods, w.r.t. the learning time and the network size while having comparable recognition accuracy.
A multi-layer network based on Sparse Ternary Codes for universal vector compression
Oct 31, 2017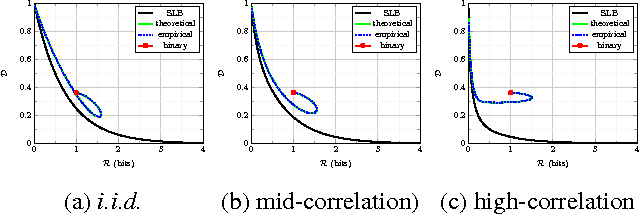
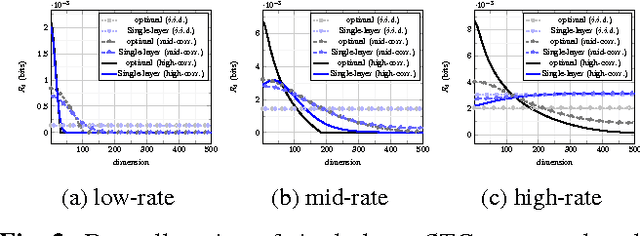
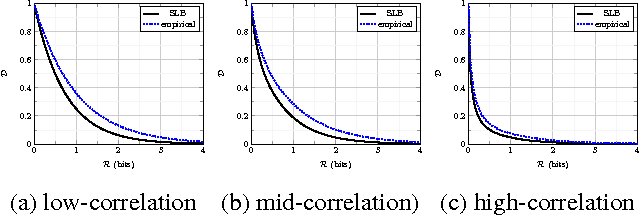
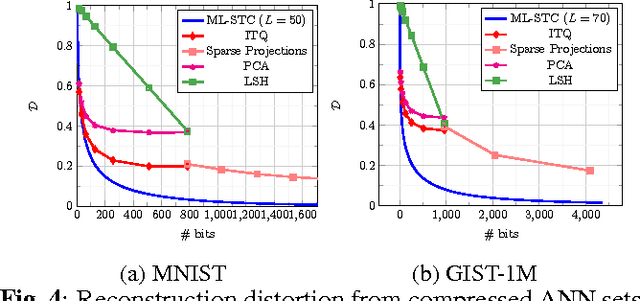
We present the multi-layer extension of the Sparse Ternary Codes (STC) for fast similarity search where we focus on the reconstruction of the database vectors from the ternary codes. To consider the trade-offs between the compactness of the STC and the quality of the reconstructed vectors, we study the rate-distortion behavior of these codes under different setups. We show that a single-layer code cannot achieve satisfactory results at high rates. Therefore, we extend the concept of STC to multiple layers and design the ML-STC, a codebook-free system that successively refines the reconstruction of the residuals of previous layers. While the ML-STC keeps the sparse ternary structure of the single-layer STC and hence is suitable for fast similarity search in large-scale databases, we show its superior rate-distortion performance on both model-based synthetic data and public large-scale databases, as compared to several binary hashing methods.