 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Feature Learning for Event Data: Direct vs Inverse Problem Formulation
Paper and Code
Sep 30, 2020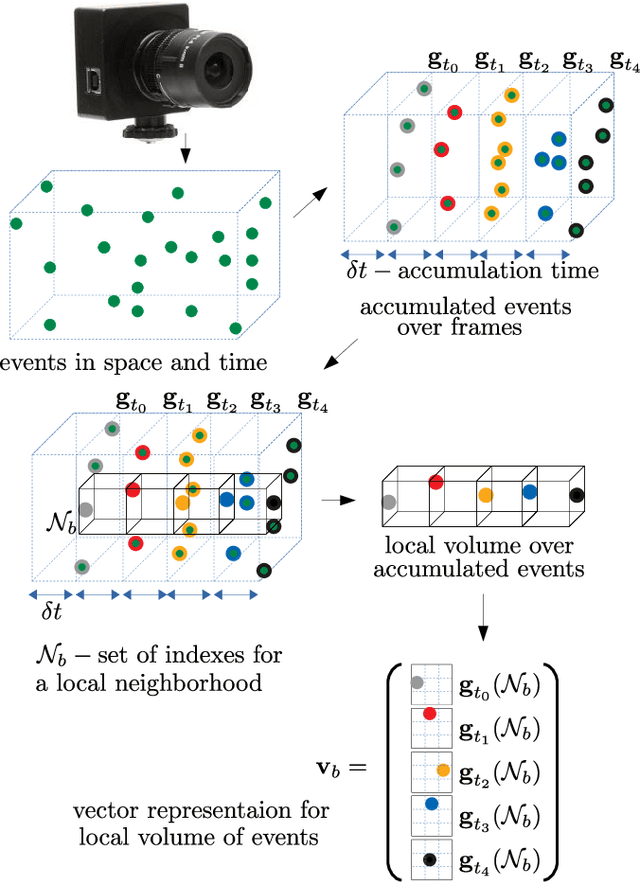
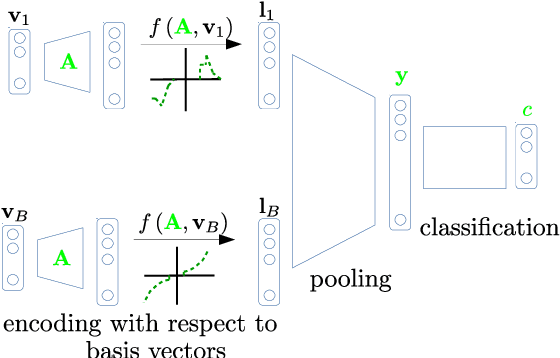
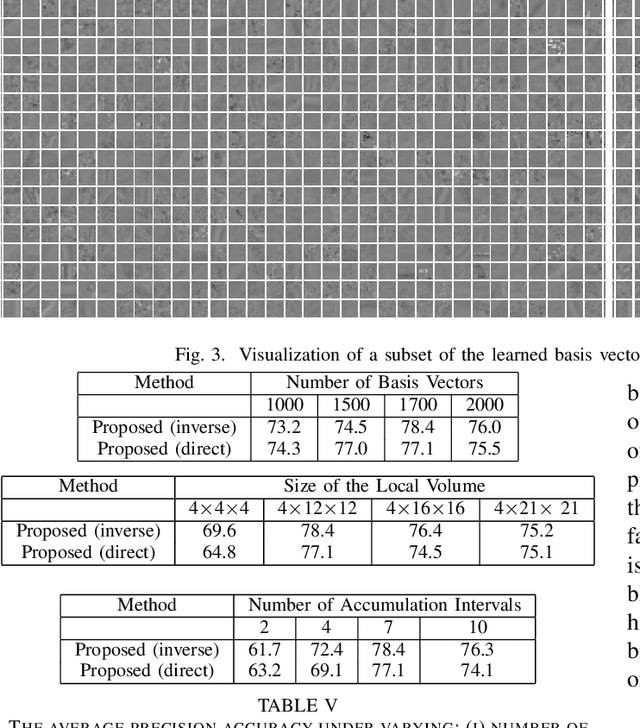
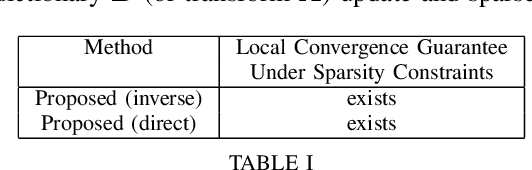
Event-based cameras record an asynchronous stream of per-pixel brightness changes. As such, they have numerous advantages over the standard frame-based cameras, including high temporal resolution, high dynamic range, and no motion blur. Due to the asynchronous nature, efficient learning of compact representation for event data is challenging. While it remains not explored the extent to which the spatial and temporal event "information" is useful for pattern recognition tasks. In this paper, we focus on single-layer architectures. We analyze the performance of two general problem formulations: the direct and the inverse, for unsupervised feature learning from local event data (local volumes of events described in space-time). We identify and show the main advantages of each approach. Theoretically, we analyze guarantees for an optimal solution, possibility for asynchronous, parallel parameter update, and the computational complexity. We present numerical experiments for object recognition. We evaluate the solution under the direct and the inverse problem and give a comparison with the state-of-the-art methods. Our empirical results highlight the advantages of both approaches for representation learning from event data. We show improvements of up to 9 % in the recognition accuracy compared to the state-of-the-art methods from the same class of methods.