 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero-shot Voice Conversion via Self-supervised Prosody Representation Learning
Paper and Code
Oct 27, 2021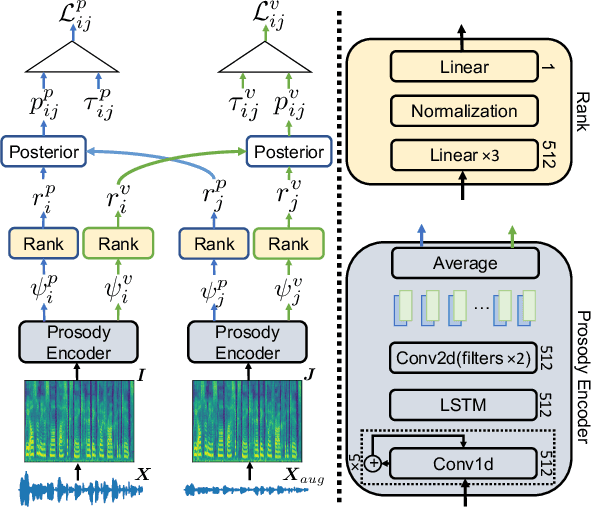
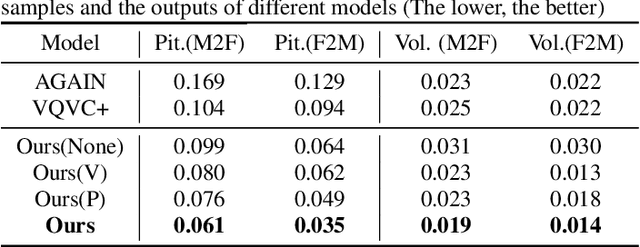
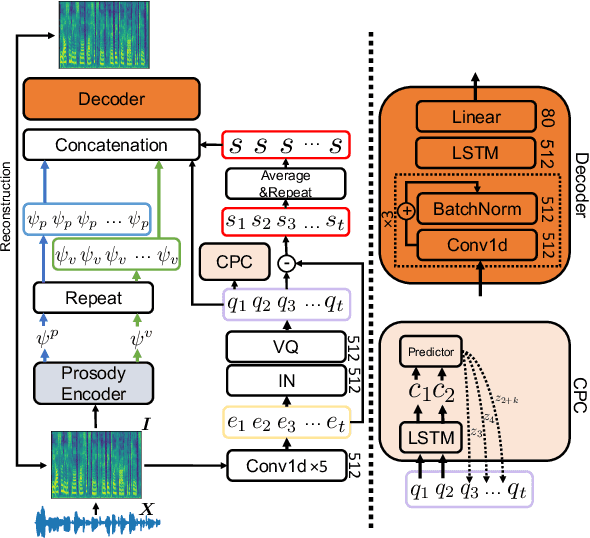
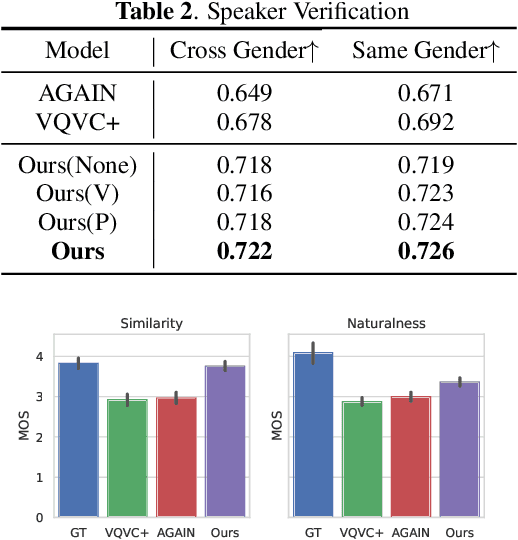
Voice Conversion (VC) for unseen speakers, also known as zero-shot VC, is an attractive topic due to its usefulness in real use-case scenarios. Recent work in this area made progress with disentanglement methods that separate utterance content and speaker characteristics. Although crucial, extracting disentangled prosody characteristics for unseen speakers remains an open issue. In this paper, we propose a novel self-supervised approach to effectively learn the prosody characteristics. Then, we use the learned prosodic representations to train our VC model for zero-shot conversion. Our evaluation demonstrates that we can efficiently extract disentangled prosody representation. Moreover, we show improved performance compared to the state-of-the-art zero-shot VC models.