 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA design of human-like robust AI machines in object identification
Jan 07, 2021
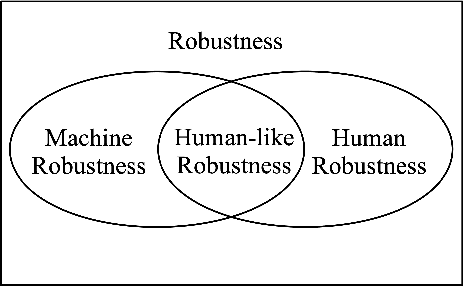
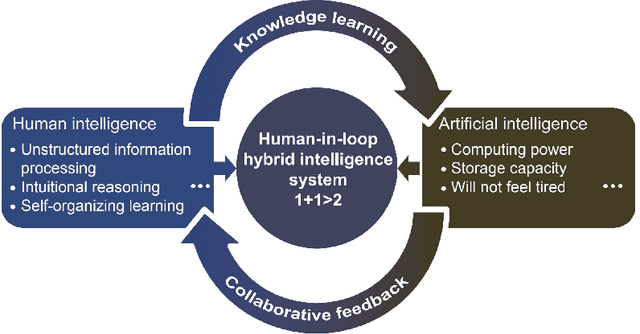
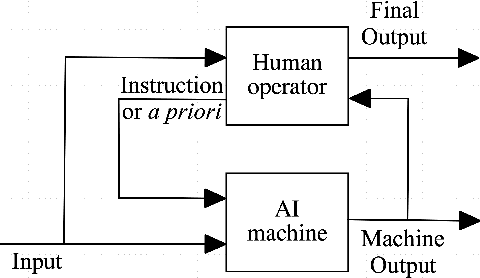
This is a perspective paper inspired from the study of Turing Test proposed by A.M. Turing (23 June 1912 - 7 June 1954) in 1950. Following one important implication of Turing Test for enabling a machine with a human-like behavior or performance, we define human-like robustness (HLR) for AI machines. The objective of the new definition aims to enforce AI machines with HLR, including to evaluate them in terms of HLR. A specific task is discussed only on object identification, because it is the most common task for every person in daily life. Similar to the perspective, or design, position by Turing, we provide a solution of how to achieve HLR AI machines without constructing them and conducting real experiments. The solution should consists of three important features in the machines. The first feature of HLR machines is to utilize common sense from humans for realizing a causal inference. The second feature is to make a decision from a semantic space for having interpretations to the decision. The third feature is to include a "human-in-the-loop" setting for advancing HLR machines. We show an "identification game" using proposed design of HLR machines. The present paper shows an attempt to learn and explore further from Turing Test towards the design of human-like AI machines.
A study on cost behaviors of binary classification measures in class-imbalanced problems
Mar 26, 2014



This work investigates into cost behaviors of binary classification measures in a background of class-imbalanced problems. Twelve performance measures are studied, such as F measure, G-means in terms of accuracy rates, and of recall and precision, balance error rate (BER), Matthews correlation coefficient (MCC), Kappa coefficient, etc. A new perspective is presented for those measures by revealing their cost functions with respect to the class imbalance ratio. Basically, they are described by four types of cost functions. The functions provides a theoretical understanding why some measures are suitable for dealing with class-imbalanced problems. Based on their cost functions, we are able to conclude that G-means of accuracy rates and BER are suitable measures because they show "proper" cost behaviors in terms of "a misclassification from a small class will cause a greater cost than that from a large class". On the contrary, F1 measure, G-means of recall and precision, MCC and Kappa coefficient measures do not produce such behaviors so that they are unsuitable to serve our goal in dealing with the problems properly.