 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralizable Representation Learning for Mixture Domain Face Anti-Spoofing
May 06, 2021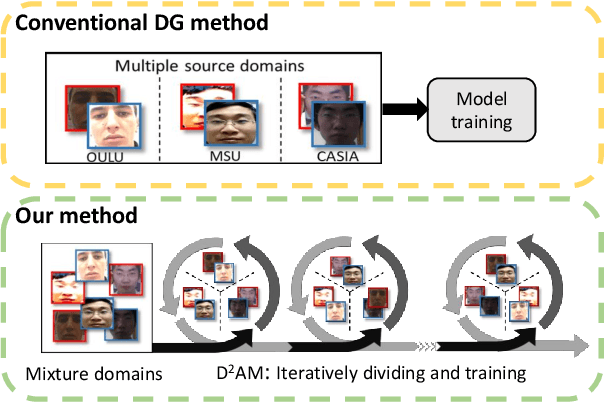
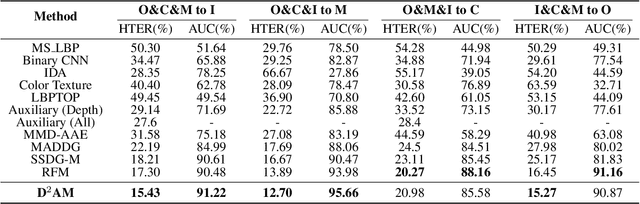
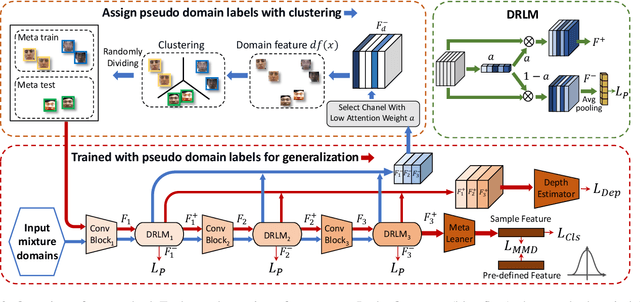
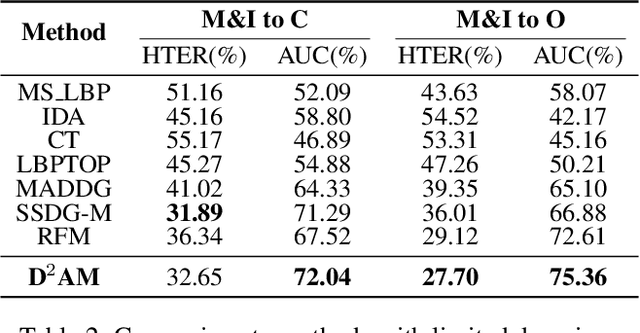
Face anti-spoofing approach based on domain generalization(DG) has drawn growing attention due to its robustness forunseen scenarios. Existing DG methods assume that the do-main label is known.However, in real-world applications, thecollected dataset always contains mixture domains, where thedomain label is unknown. In this case, most of existing meth-ods may not work. Further, even if we can obtain the domainlabel as existing methods, we think this is just a sub-optimalpartition. To overcome the limitation, we propose domain dy-namic adjustment meta-learning (D2AM) without using do-main labels, which iteratively divides mixture domains viadiscriminative domain representation and trains a generaliz-able face anti-spoofing with meta-learning. Specifically, wedesign a domain feature based on Instance Normalization(IN) and propose a domain representation learning module(DRLM) to extract discriminative domain features for cluster-ing. Moreover, to reduce the side effect of outliers on cluster-ing performance, we additionally utilize maximum mean dis-crepancy (MMD) to align the distribution of sample featuresto a prior distribution, which improves the reliability of clus tering. Extensive experiments show that the proposed methodoutperforms conventional DG-based face anti-spoofing meth-ods, including those utilizing domain labels. Furthermore, weenhance the interpretability through visualizatio
Synthesizing MR Image Contrast Enhancement Using 3D High-resolution ConvNets
Apr 13, 2021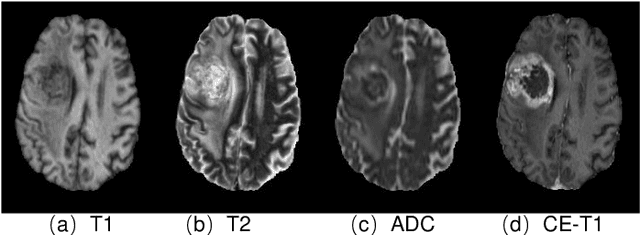
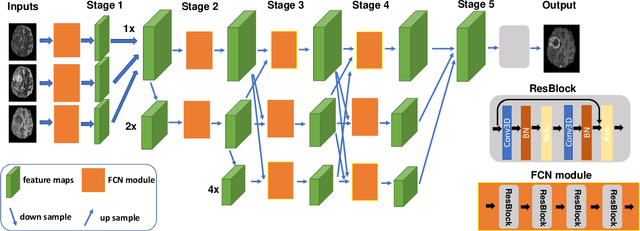
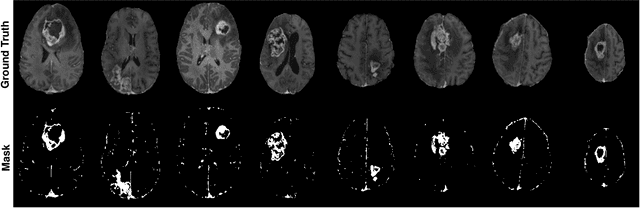
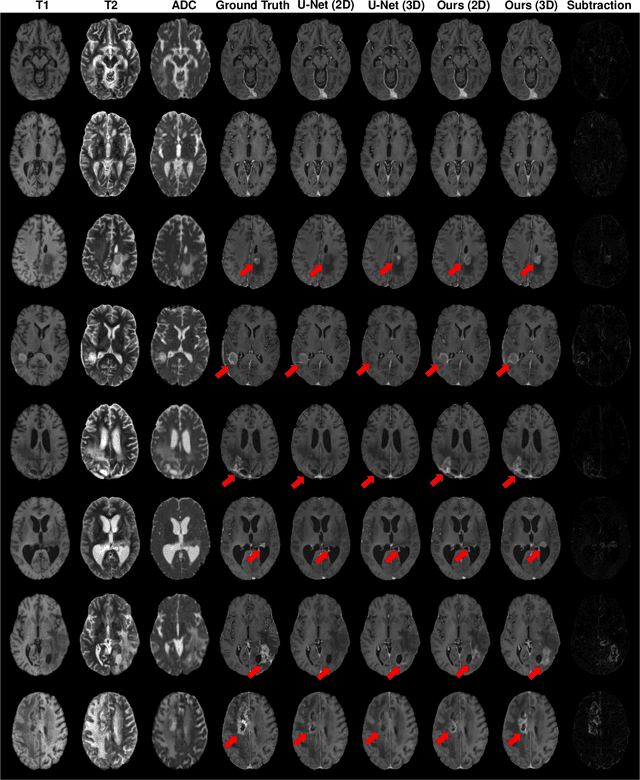
Gadolinium-based contrast agents (GBCAs) have been widely used to better visualize disease in brain magnetic resonance imaging (MRI). However, gadolinium deposition within the brain and body has raised safety concerns about the use of GBCAs. Therefore, the development of novel approaches that can decrease or even eliminate GBCA exposure while providing similar contrast information would be of significant use clinically. For brain tumor patients, standard-of-care includes repeated MRI with gadolinium-based contrast for disease monitoring, increasing the risk of gadolinium deposition. In this work, we present a deep learning based approach for contrast-enhanced T1 synthesis on brain tumor patients. A 3D high-resolution fully convolutional network (FCN), which maintains high resolution information through processing and aggregates multi-scale information in parallel, is designed to map pre-contrast MRI sequences to contrast-enhanced MRI sequences. Specifically, three pre-contrast MRI sequences, T1, T2 and apparent diffusion coefficient map (ADC), are utilized as inputs and the post-contrast T1 sequences are utilized as target output. To alleviate the data imbalance problem between normal tissues and the tumor regions, we introduce a local loss to improve the contribution of the tumor regions, which leads to better enhancement results on tumors. Extensive quantitative and visual assessments are performed, with our proposed model achieving a PSNR of 28.24dB in the brain and 21.2dB in tumor regions. Our results suggests the potential of substituting GBCAs with synthetic contrast images generated via deep learning.
DCANet: Dense Context-Aware Network for Semantic Segmentation
Apr 06, 2021
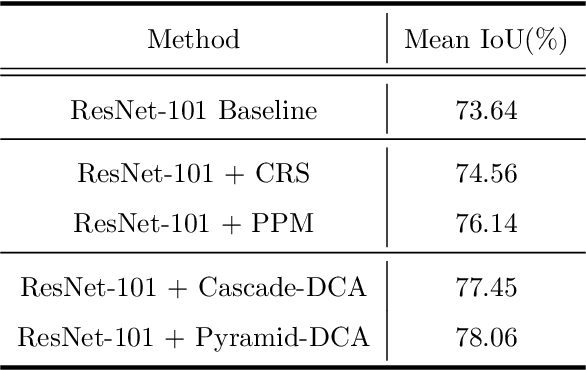
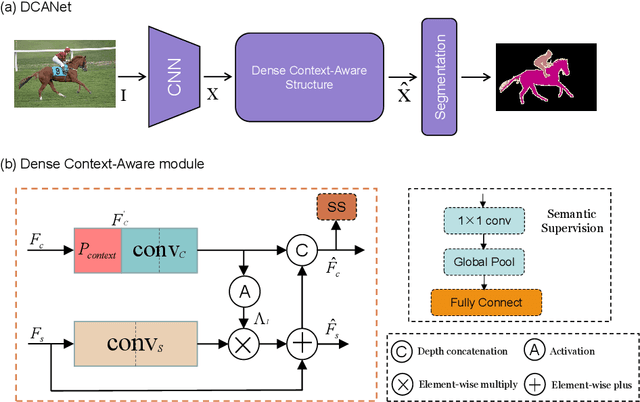
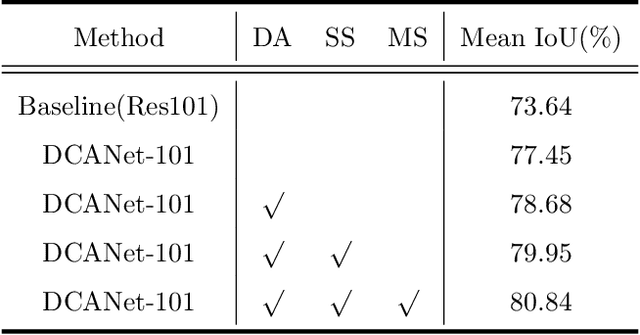
As the superiority of context information gradually manifests in advanced semantic segmentation, learning to capture the compact context relationship can help to understand the complex scenes. In contrast to some previous works utilizing the multi-scale context fusion, we propose a novel module, named Dense Context-Aware (DCA) module, to adaptively integrate local detail information with global dependencies. Driven by the contextual relationship, the DCA module can better achieve the aggregation of context information to generate more powerful features. Furthermore, we deliberately design two extended structures based on the DCA modules to further capture the long-range contextual dependency information. By combining the DCA modules in cascade or parallel, our networks use a progressive strategy to improve multi-scale feature representations for robust segmentation. We empirically demonstrate the promising performance of our approach (DCANet) with extensive experiments on three challenging datasets, including PASCAL VOC 2012, Cityscapes, and ADE20K.
Attention-Guided Discriminative Region Localization for Bone Age Assessment
May 30, 2020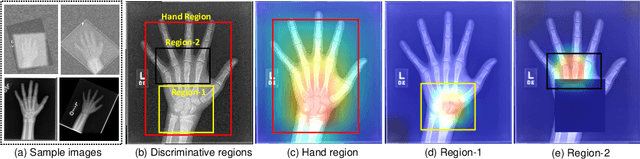

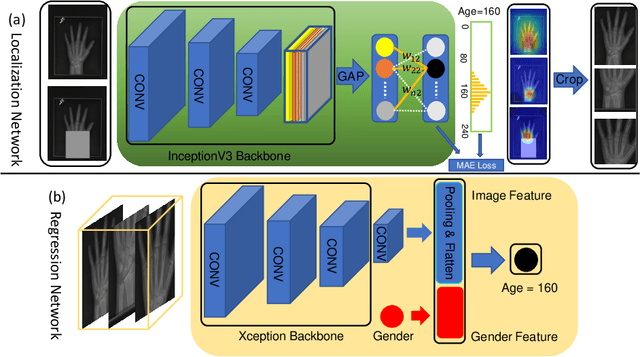

Bone age assessment (BAA) is clinically important as it can be used to diagnose endocrine and metabolic disorders during child development. Existing deep learning based methods for classifying bone age generally use the global image as input, or exploit local information by annotating extra bounding boxes or key points. Training with the global image underutilizes discriminative local information, while providing extra annotations is expensive and subjective. In this paper, we propose an attention-guided approach to automatically localize the discriminative regions for BAA without any extra annotations. Specifically, we first train a classification model to learn the attention heat maps of the discriminative regions, finding the hand region, the most discriminative region (the carpal bones), and the next most discriminative region (the metacarpal bones). We then crop these informative local regions from the original image and aggregate different regions for bone age regression. Extensive comparison experiments are conducted on the RSNA pediatric bone age data set. Using no training annotations, our method achieves competitive results compared with existing state-of-the-art semi-automatic deep learning-based methods that require manual annotation. codes are available at \url{https://github.com/chenchao666/Bone-Age-Assessment}.
Deep Learning Guided Undersampling Mask Design for MR Image Reconstruction
Mar 08, 2020
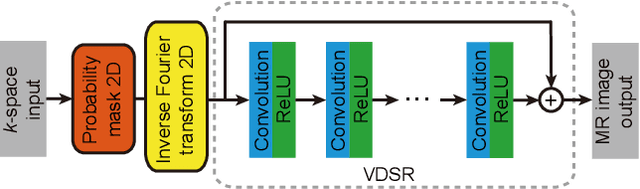
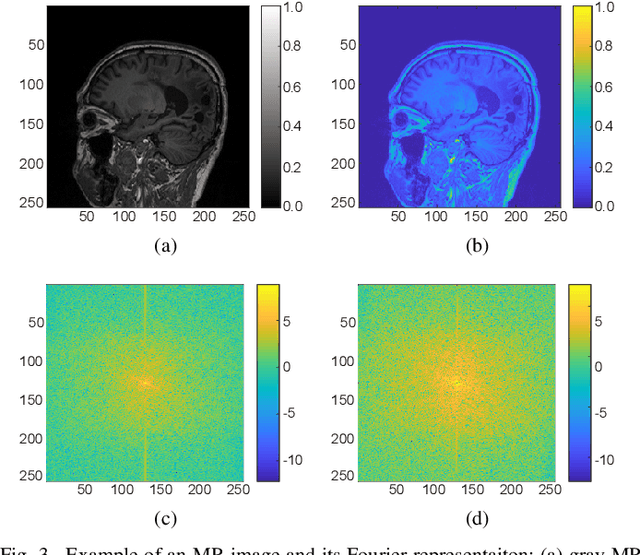
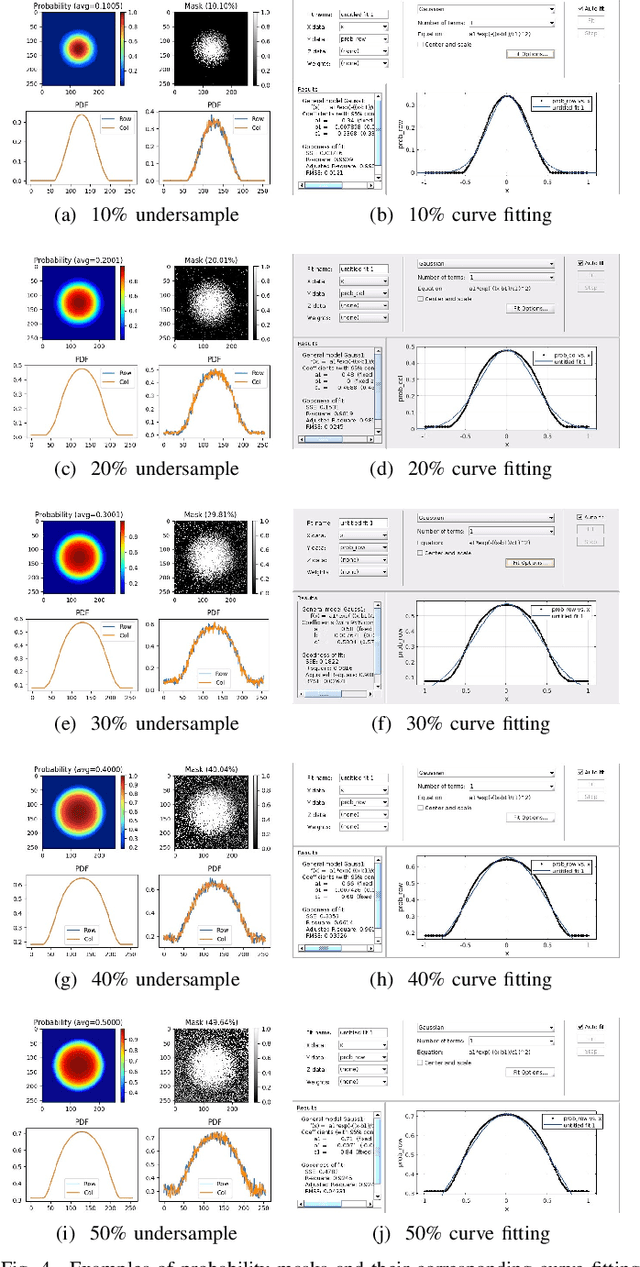
In this paper, we propose a cross-domain networks that can achieve undersampled MR image reconstruction from raw k-space space. We design a 2D probability sampling mask layer to simulate real undersampling operation. Then the 2D Inverse FFT is deployed to reconstruct MR image from frequency domain to spatial domain. By minimizing the Euclidean loss between ground-truth image and output, we train the parameters in our probability mask layer. We discover the probability appears special patterns that is quite different from universal common sense that mask should be Poisson-like, under certain undersampled rates. We analyze the probability mask is subjected to Gaussian or Quadratic distributions, and discuss this pattern will be more accurate and robust than traditional ones. Extensive experiments proves that the rules we discovered are adaptive to most cases. This can be a useful guidance to further MR reconstruction mask designs.
HoMM: Higher-order Moment Matching for Unsupervised Domain Adaptation
Dec 27, 2019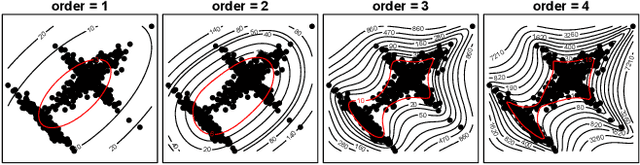
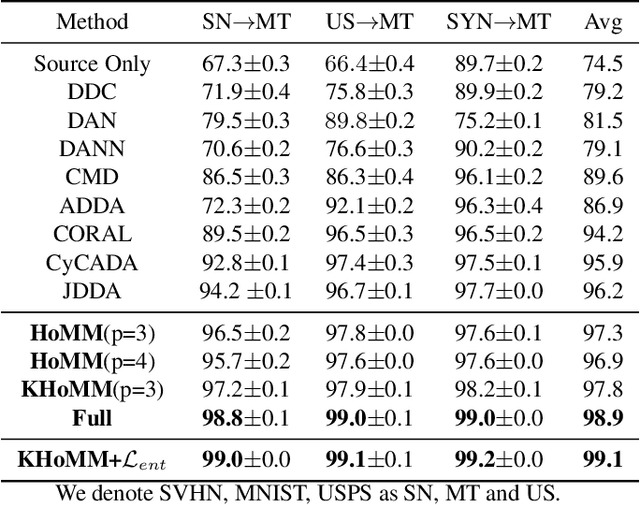
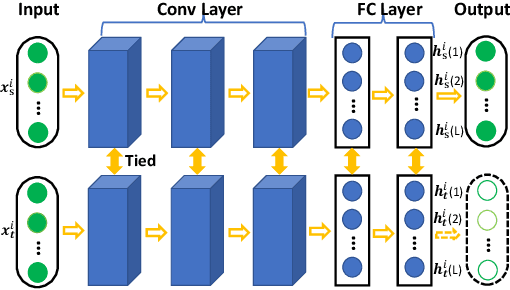
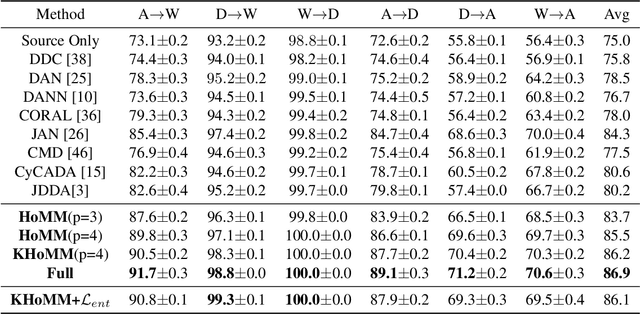
Minimizing the discrepancy of feature distributions between different domains is one of the most promising directions in unsupervised domain adaptation. From the perspective of distribution matching, most existing discrepancy-based methods are designed to match the second-order or lower statistics, which however, have limited expression of statistical characteristic for non-Gaussian distributions. In this work, we explore the benefits of using higher-order statistics (mainly refer to third-order and fourth-order statistics) for domain matching. We propose a Higher-order Moment Matching (HoMM) method, and further extend the HoMM into reproducing kernel Hilbert spaces (RKHS). In particular, our proposed HoMM can perform arbitrary-order moment tensor matching, we show that the first-order HoMM is equivalent to Maximum Mean Discrepancy (MMD) and the second-order HoMM is equivalent to Correlation Alignment (CORAL). Moreover, the third-order and the fourth-order moment tensor matching are expected to perform comprehensive domain alignment as higher-order statistics can approximate more complex, non-Gaussian distributions. Besides, we also exploit the pseudo-labeled target samples to learn discriminative representations in the target domain, which further improves the transfer performance. Extensive experiments are conducted, showing that our proposed HoMM consistently outperforms the existing moment matching methods by a large margin. Codes are available at \url{https://github.com/chenchao666/HoMM-Master}
Selective Transfer with Reinforced Transfer Network for Partial Domain Adaptation
May 26, 2019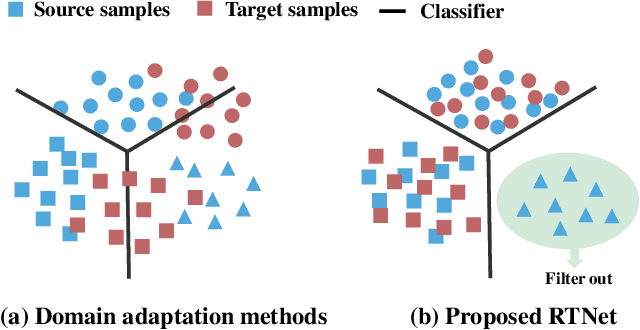

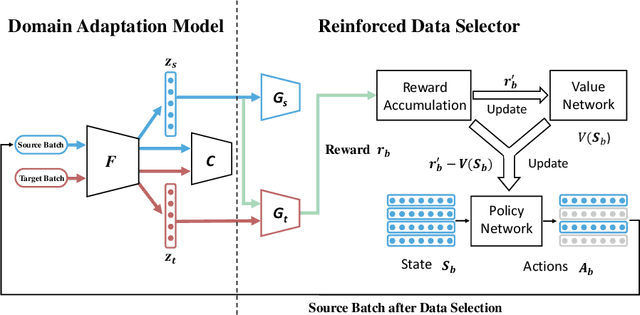
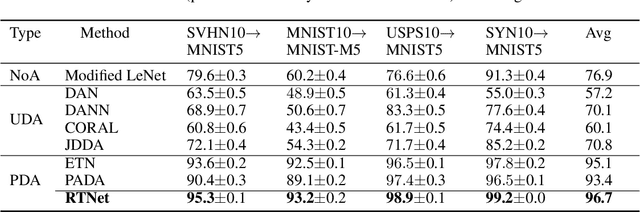
Partial domain adaptation (PDA) extends standard domain adaptation to a more realistic scenario where the target domain only has a subset of classes from the source domain. The key challenge of PDA is how to select the relevant samples in the shared classes for knowledge transfer. Previous PDA methods tackle this problem by re-weighting the source samples based on the prediction of classifier or discriminator, thus discarding the pixel-level information. In this paper, to utilize both high-level and pixel-level information, we propose a reinforced transfer network (RTNet), which is the first work to apply reinforcement learning to address the PDA problem. The RTNet simultaneously mitigates the negative transfer by adopting a reinforced data selector to filter out outlier source classes, and promotes the positive transfer by employing a domain adaptation model to minimize the distribution discrepancy in the shared label space. Extensive experiments indicate that RTNet can achieve state-of-the-art performance for partial domain adaptation tasks on several benchmark datasets. Codes and datasets will be available online.
Towards Self-similarity Consistency and Feature Discrimination for Unsupervised Domain Adaptation
Apr 13, 2019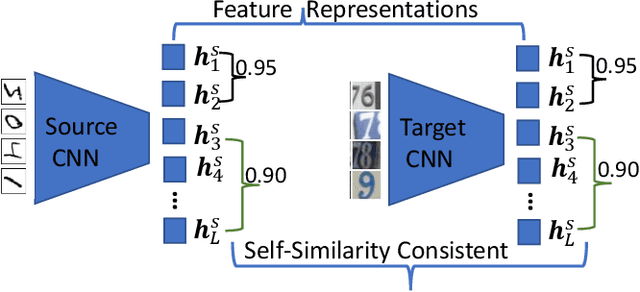
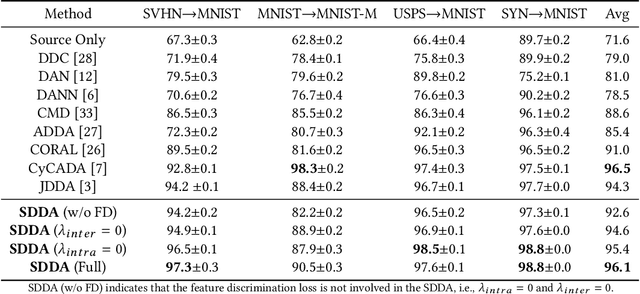
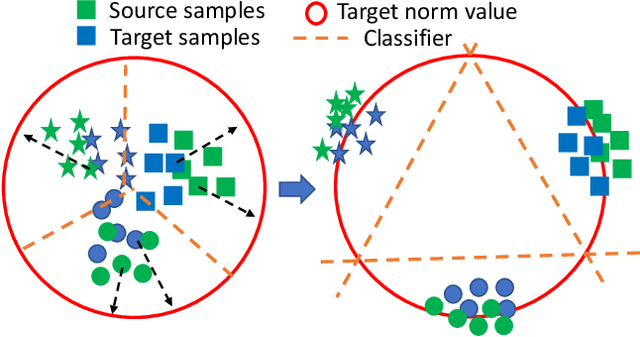
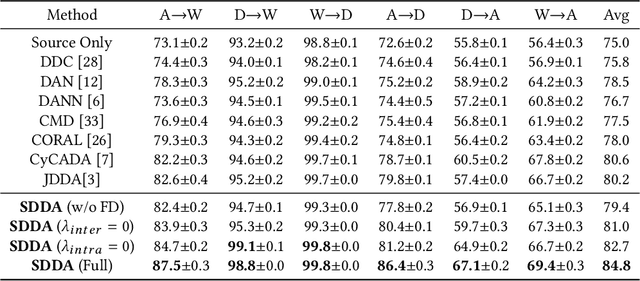
Recent advances in unsupervised domain adaptation mainly focus on learning shared representations by global distribution alignment without considering class information across domains. The neglect of class information, however, may lead to partial alignment (or even misalignment) and poor generalization performance. For comprehensive alignment, we argue that the similarities across different features in the source domain should be consistent with that of in the target domain. Based on this assumption, we propose a new domain discrepancy metric, i.e., Self-similarity Consistency (SSC), to enforce the feature structure being consistent across domains. The renowned correlation alignment (CORAL) is proven to be a special case, and a sub-optimal measure of our proposed SSC. Furthermore, we also propose to mitigate the side effect of the partial alignment and misalignment by incorporating the discriminative information of the deep representations. Specifically, an embarrassingly simple and effective feature norm constraint is exploited to enlarge the discrepancy of inter-class samples. It relieves the requirements of strict alignment when performing adaptation, therefore improving the adaptation performance significantly. Extensive experiments on visual domain adaptation tasks demonstrate the effectiveness of our proposed SSC metric and feature discrimination approach.
Double Weighted Truncated Nuclear Norm Regularization for Low-Rank Matrix Completion
Jan 07, 2019
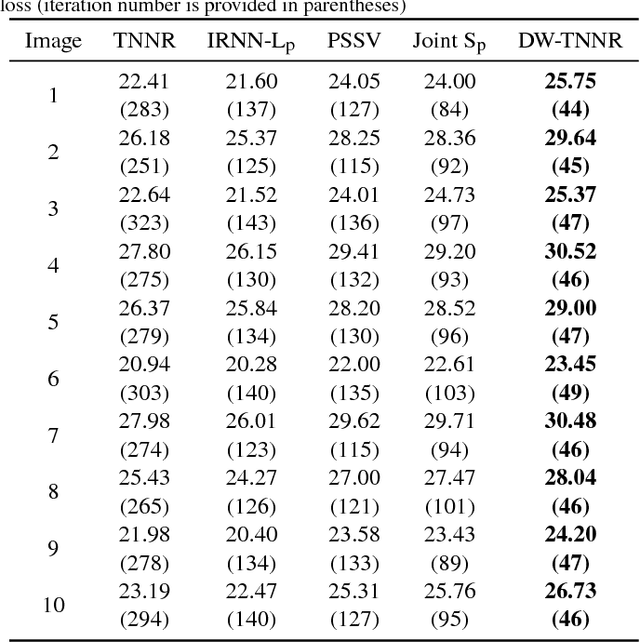
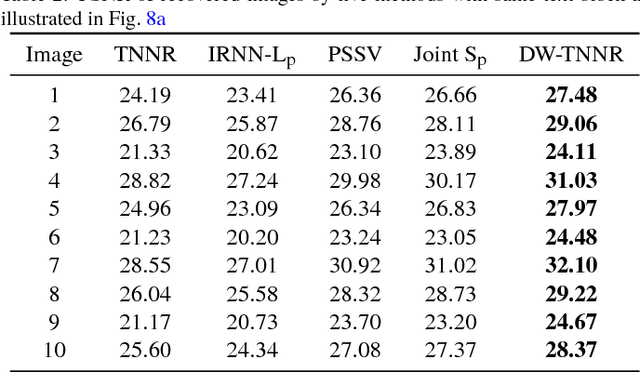
Matrix completion focuses on recovering a matrix from a small subset of its observed elements, and has already gained cumulative attention in computer vision. Many previous approaches formulate this issue as a low-rank matrix approximation problem. Recently, a truncated nuclear norm has been presented as a surrogate of traditional nuclear norm, for better estimation to the rank of a matrix. The truncated nuclear norm regularization (TNNR) method is applicable in real-world scenarios. However, it is sensitive to the selection of the number of truncated singular values and requires numerous iterations to converge. Hereby, this paper proposes a revised approach called the double weighted truncated nuclear norm regularization (DW-TNNR), which assigns different weights to the rows and columns of a matrix separately, to accelerate the convergence with acceptable performance. The DW-TNNR is more robust to the number of truncated singular values than the TNNR. Instead of the iterative updating scheme in the second step of TNNR, this paper devises an efficient strategy that uses a gradient descent manner in a concise form, with a theoretical guarantee in optimization. Sufficient experiments conducted on real visual data prove that DW-TNNR has promising performance and holds the superiority in both speed and accuracy for matrix completion.
Truncated nuclear norm regularization for low-rank tensor completion
Jan 07, 2019
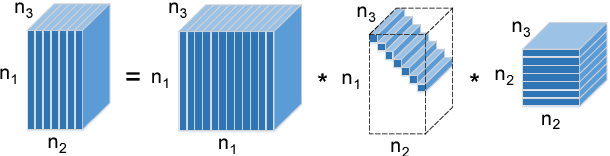

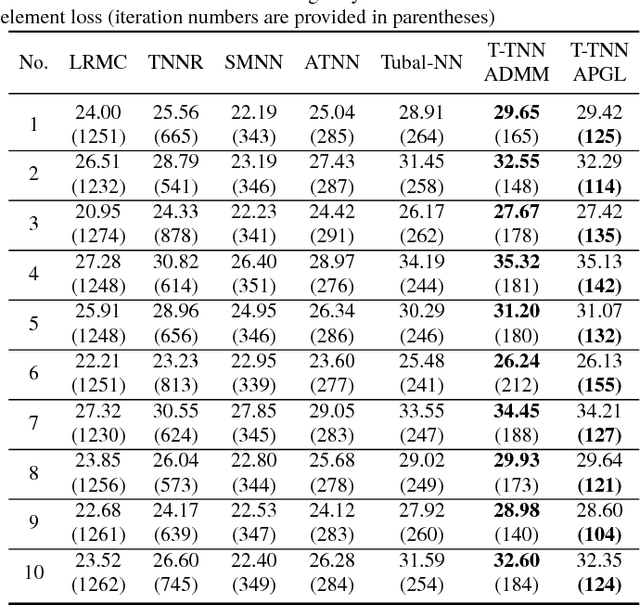
Recently, low-rank tensor completion has become increasingly attractive in recovering incomplete visual data. Considering a color image or video as a three-dimensional (3D) tensor, existing studies have put forward several definitions of tensor nuclear norm. However, they are limited and may not accurately approximate the real rank of a tensor, and they do not explicitly use the low-rank property in optimization. It is proved that the recently proposed truncated nuclear norm (TNN) can replace the traditional nuclear norm, as an improved approximation to the rank of a matrix. In this paper, we propose a new method called the tensor truncated nuclear norm (T-TNN), which suggests a new definition of tensor nuclear norm. The truncated nuclear norm is generalized from the matrix case to the tensor case. With the help of the low rankness of TNN, our approach improves the efficacy of tensor completion. We adopt the definition of the previously proposed tensor singular value decomposition, the alternating direction method of multipliers, and the accelerated proximal gradient line search method in our algorithm. Substantial experiments on real-world videos and images illustrate that the performance of our approach is better than those of previous methods.