 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining-free Transformer Architecture Search
Mar 23, 2022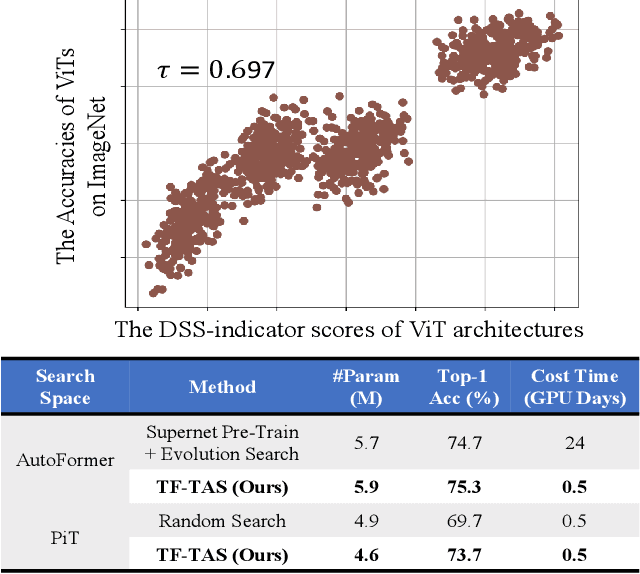
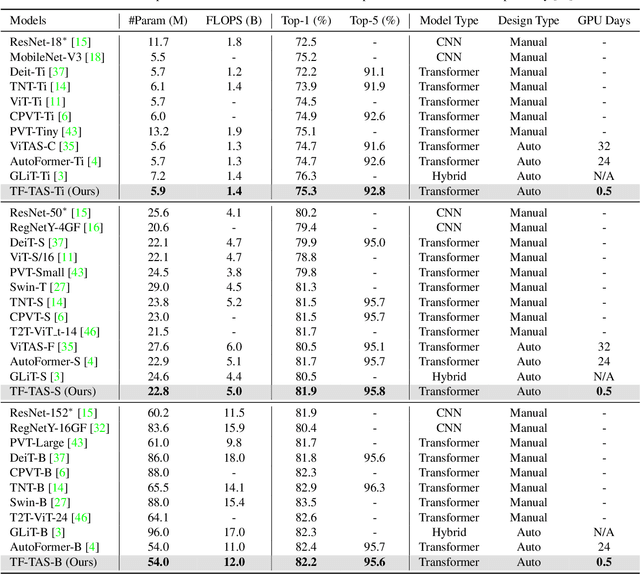
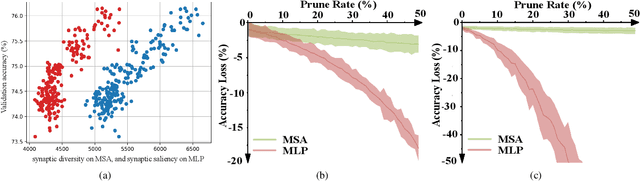
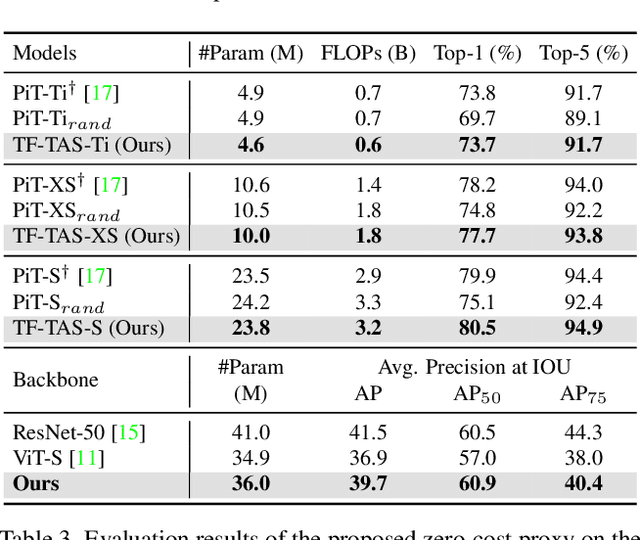
Recently, Vision Transformer (ViT) has achieved remarkable success in several computer vision tasks. The progresses are highly relevant to the architecture design, then it is worthwhile to propose Transformer Architecture Search (TAS) to search for better ViTs automatically. However, current TAS methods are time-consuming and existing zero-cost proxies in CNN do not generalize well to the ViT search space according to our experimental observations. In this paper, for the first time, we investigate how to conduct TAS in a training-free manner and devise an effective training-free TAS (TF-TAS) scheme. Firstly, we observe that the properties of multi-head self-attention (MSA) and multi-layer perceptron (MLP) in ViTs are quite different and that the synaptic diversity of MSA affects the performance notably. Secondly, based on the observation, we devise a modular strategy in TF-TAS that evaluates and ranks ViT architectures from two theoretical perspectives: synaptic diversity and synaptic saliency, termed as DSS-indicator. With DSS-indicator, evaluation results are strongly correlated with the test accuracies of ViT models. Experimental results demonstrate that our TF-TAS achieves a competitive performance against the state-of-the-art manually or automatically design ViT architectures, and it promotes the searching efficiency in ViT search space greatly: from about $24$ GPU days to less than $0.5$ GPU days. Moreover, the proposed DSS-indicator outperforms the existing cutting-edge zero-cost approaches (e.g., TE-score and NASWOT).
Small Object Detection Based on Modified FSSD and Model Compression
Aug 24, 2021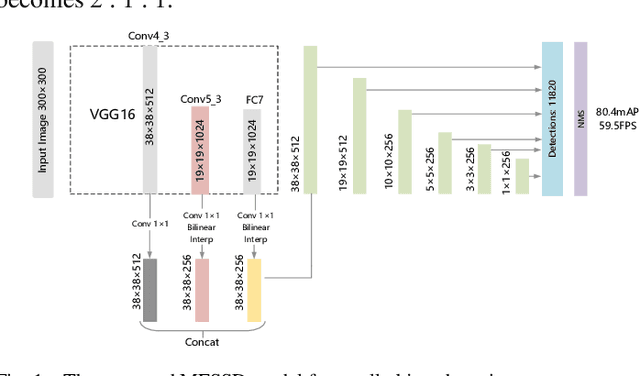
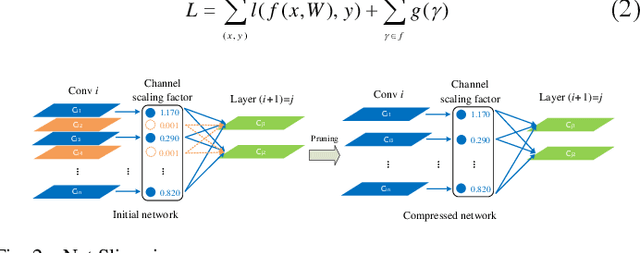
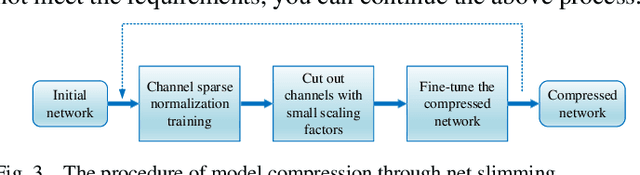

Small objects have relatively low resolution, the unobvious visual features which are difficult to be extracted, so the existing object detection methods cannot effectively detect small objects, and the detection speed and stability are poor. Thus, this paper proposes a small object detection algorithm based on FSSD, meanwhile, in order to reduce the computational cost and storage space, pruning is carried out to achieve model compression. Firstly, the semantic information contained in the features of different layers can be used to detect different scale objects, and the feature fusion method is improved to obtain more information beneficial to small objects; secondly, batch normalization layer is introduced to accelerate the training of neural network and make the model sparse; finally, the model is pruned by scaling factor to get the corresponding compressed model. The experimental results show that the average accuracy (mAP) of the algorithm can reach 80.4% on PASCAL VOC and the speed is 59.5 FPS on GTX1080ti. After pruning, the compressed model can reach 79.9% mAP, and 79.5 FPS in detection speed. On MS COCO, the best detection accuracy (APs) is 12.1%, and the overall detection accuracy is 49.8% AP when IoU is 0.5. The algorithm can not only improve the detection accuracy of small objects, but also greatly improves the detection speed, which reaches a balance between speed and accuracy.