 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Normalized Representation Learning for Generalizable Face Anti-Spoofing
Aug 05, 2021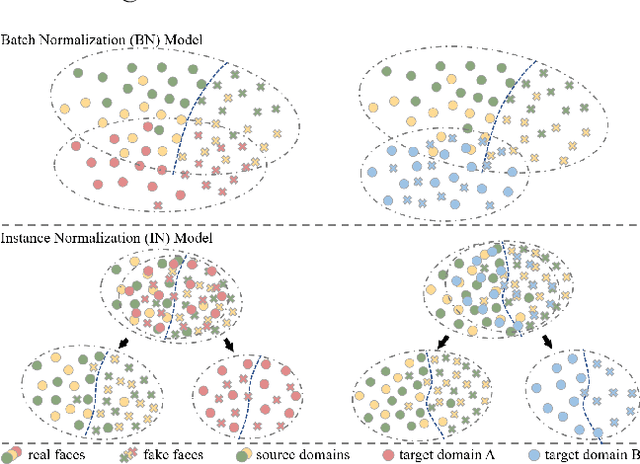
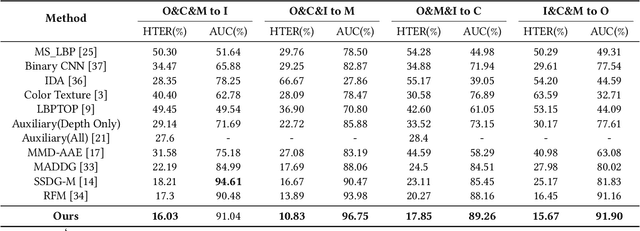
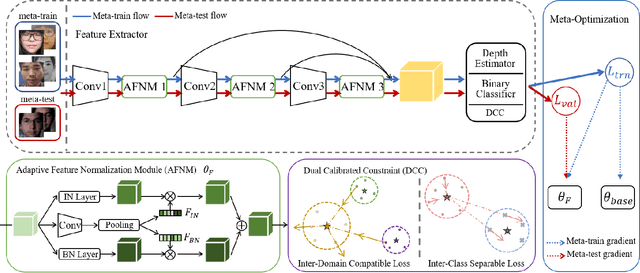
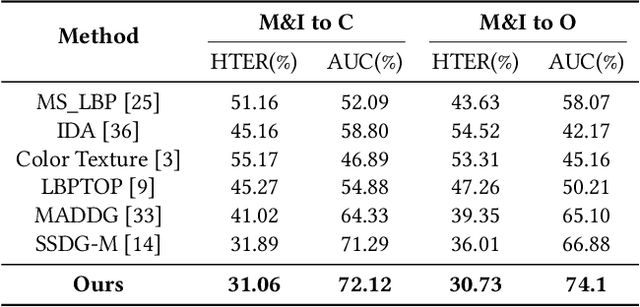
With various face presentation attacks arising under unseen scenarios, face anti-spoofing (FAS) based on domain generalization (DG) has drawn growing attention due to its robustness. Most existing methods utilize DG frameworks to align the features to seek a compact and generalized feature space. However, little attention has been paid to the feature extraction process for the FAS task, especially the influence of normalization, which also has a great impact on the generalization of the learned representation. To address this issue, we propose a novel perspective of face anti-spoofing that focuses on the normalization selection in the feature extraction process. Concretely, an Adaptive Normalized Representation Learning (ANRL) framework is devised, which adaptively selects feature normalization methods according to the inputs, aiming to learn domain-agnostic and discriminative representation. Moreover, to facilitate the representation learning, Dual Calibration Constraints are designed, including Inter-Domain Compatible loss and Inter-Class Separable loss, which provide a better optimization direction for generalizable representation. Extensive experiments and visualizations are presented to demonstrate the effectiveness of our method against the SOTA competitors.
Dual Reweighting Domain Generalization for Face Presentation Attack Detection
Jun 30, 2021
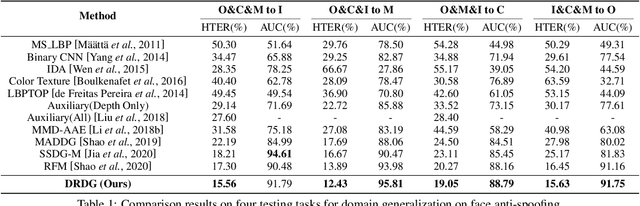
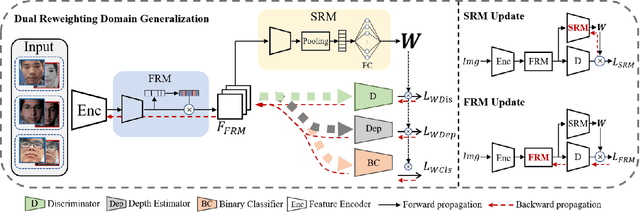
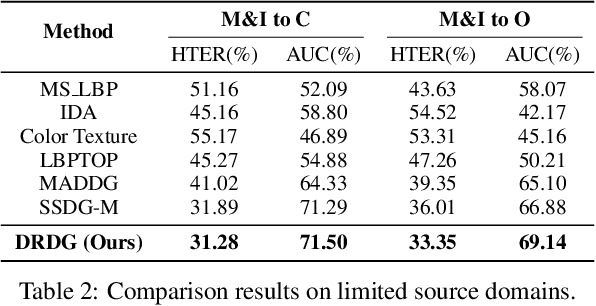
Face anti-spoofing approaches based on domain generalization (DG) have drawn growing attention due to their robustness for unseen scenarios. Previous methods treat each sample from multiple domains indiscriminately during the training process, and endeavor to extract a common feature space to improve the generalization. However, due to complex and biased data distribution, directly treating them equally will corrupt the generalization ability. To settle the issue, we propose a novel Dual Reweighting Domain Generalization (DRDG) framework which iteratively reweights the relative importance between samples to further improve the generalization. Concretely, Sample Reweighting Module is first proposed to identify samples with relatively large domain bias, and reduce their impact on the overall optimization. Afterwards, Feature Reweighting Module is introduced to focus on these samples and extract more domain-irrelevant features via a self-distilling mechanism. Combined with the domain discriminator, the iteration of the two modules promotes the extraction of generalized features. Extensive experiments and visualizations are presented to demonstrate the effectiveness and interpretability of our method against the state-of-the-art competitors.
Flow Based Self-supervised Pixel Embedding for Image Segmentation
Jan 08, 2019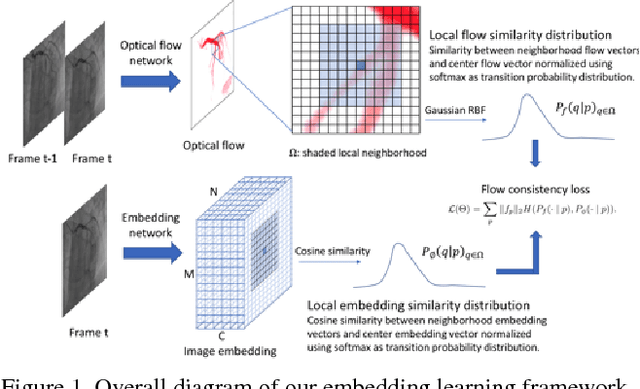
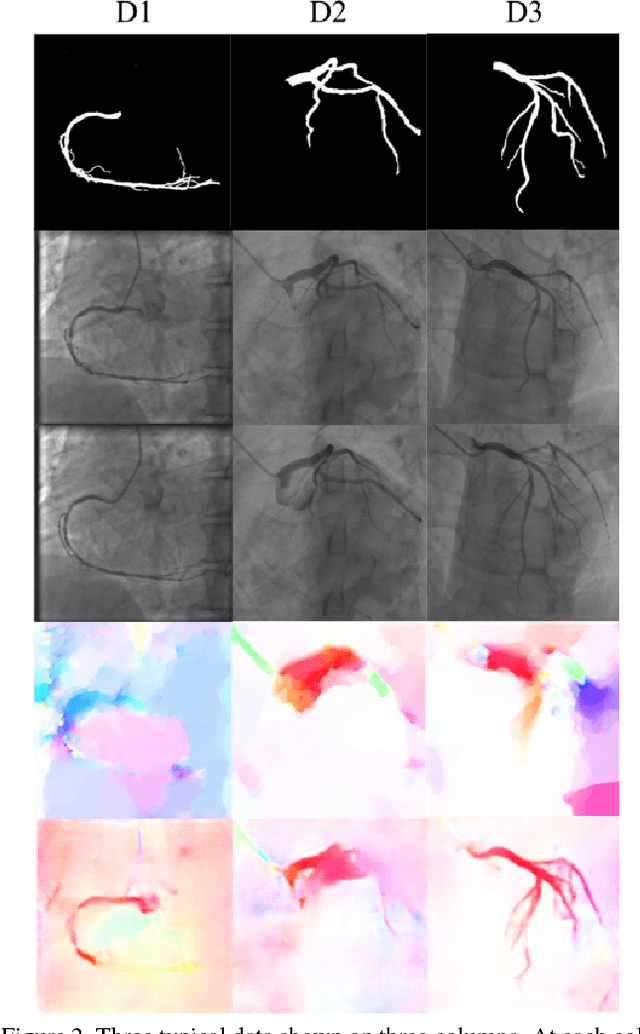

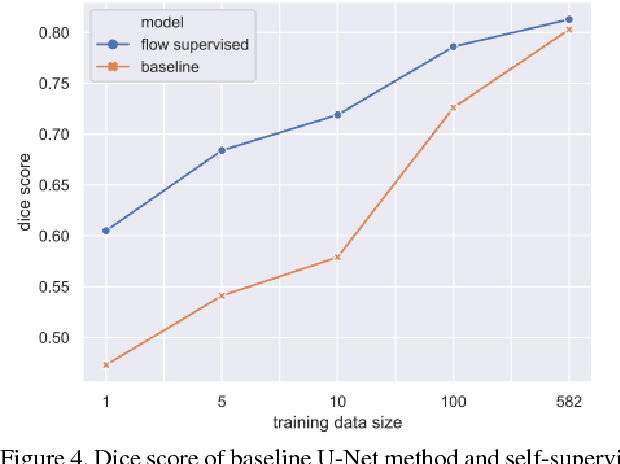
We propose a new self-supervised approach to image feature learning from motion cue. This new approach leverages recent advances in deep learning in two directions: 1) the success of training deep neural network in estimating optical flow in real data using synthetic flow data; and 2) emerging work in learning image features from motion cues, such as optical flow. Building on these, we demonstrate that image features can be learned in self-supervision by first training an optical flow estimator with synthetic flow data, and then learning image features from the estimated flows in real motion data. We demonstrate and evaluate this approach on an image segmentation task. Using the learned image feature representation, the network performs significantly better than the ones trained from scratch in few-shot segmentation tasks.