Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePatFig: Generating Short and Long Captions for Patent Figures
Paper and Code
Sep 15, 2023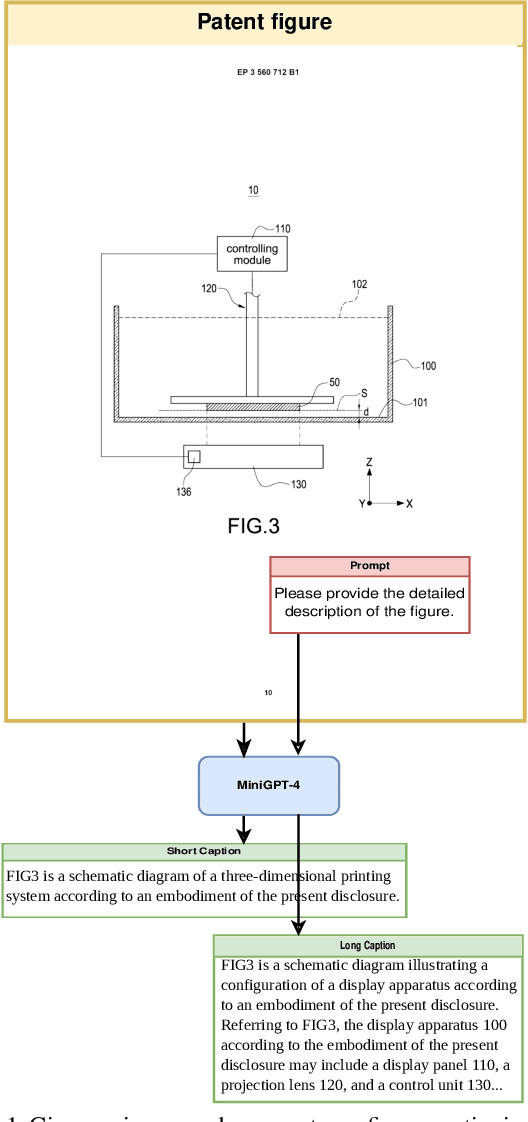


This paper introduces Qatent PatFig, a novel large-scale patent figure dataset comprising 30,000+ patent figures from over 11,000 European patent applications. For each figure, this dataset provides short and long captions, reference numerals, their corresponding terms, and the minimal claim set that describes the interactions between the components of the image. To assess the usability of the dataset, we finetune an LVLM model on Qatent PatFig to generate short and long descriptions, and we investigate the effects of incorporating various text-based cues at the prediction stage of the patent figure captioning process.
* accepted to the ICCV 2023, CLVL: 5th Workshop on Closing the Loop
Between Vision and Language
View paper on