 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLook More Than Once: An Accurate Detector for Text of Arbitrary Shapes
Paper and Code
Apr 13, 2019
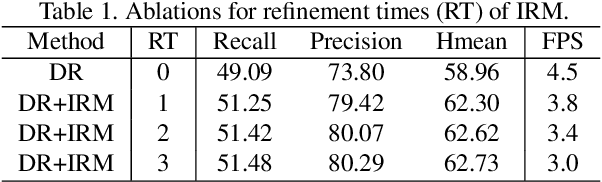
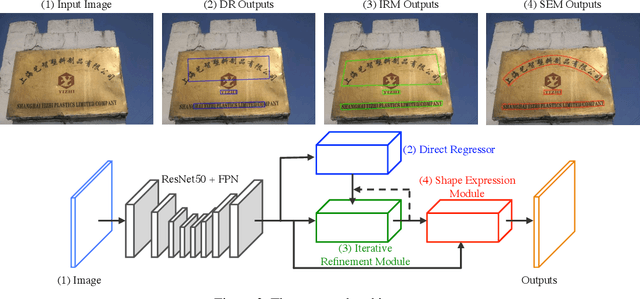

Previous scene text detection methods have progressed substantially over the past years. However, limited by the receptive field of CNNs and the simple representations like rectangle bounding box or quadrangle adopted to describe text, previous methods may fall short when dealing with more challenging text instances, such as extremely long text and arbitrarily shaped text. To address these two problems, we present a novel text detector namely LOMO, which localizes the text progressively for multiple times (or in other word, LOok More than Once). LOMO consists of a direct regressor (DR), an iterative refinement module (IRM) and a shape expression module (SEM). At first, text proposals in the form of quadrangle are generated by DR branch. Next, IRM progressively perceives the entire long text by iterative refinement based on the extracted feature blocks of preliminary proposals. Finally, a SEM is introduced to reconstruct more precise representation of irregular text by considering the geometry properties of text instance, including text region, text center line and border offsets. The state-of-the-art results on several public benchmarks including ICDAR2017-RCTW, SCUT-CTW1500, Total-Text, ICDAR2015 and ICDAR17-MLT confirm the striking robustness and effectiveness of LOMO.