 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFeature-Suppressed Contrast for Self-Supervised Food Pre-training
Aug 21, 2023



Most previous approaches for analyzing food images have relied on extensively annotated datasets, resulting in significant human labeling expenses due to the varied and intricate nature of such images. Inspired by the effectiveness of contrastive self-supervised methods in utilizing unlabelled data, weiqing explore leveraging these techniques on unlabelled food images. In contrastive self-supervised methods, two views are randomly generated from an image by data augmentations. However, regarding food images, the two views tend to contain similar informative contents, causing large mutual information, which impedes the efficacy of contrastive self-supervised learning. To address this problem, we propose Feature Suppressed Contrast (FeaSC) to reduce mutual information between views. As the similar contents of the two views are salient or highly responsive in the feature map, the proposed FeaSC uses a response-aware scheme to localize salient features in an unsupervised manner. By suppressing some salient features in one view while leaving another contrast view unchanged, the mutual information between the two views is reduced, thereby enhancing the effectiveness of contrast learning for self-supervised food pre-training. As a plug-and-play module, the proposed method consistently improves BYOL and SimSiam by 1.70\% $\sim$ 6.69\% classification accuracy on four publicly available food recognition datasets. Superior results have also been achieved on downstream segmentation tasks, demonstrating the effectiveness of the proposed method.
Learn More for Food Recognition via Progressive Self-Distillation
Mar 09, 2023



Food recognition has a wide range of applications, such as health-aware recommendation and self-service restaurants. Most previous methods of food recognition firstly locate informative regions in some weakly-supervised manners and then aggregate their features. However, location errors of informative regions limit the effectiveness of these methods to some extent. Instead of locating multiple regions, we propose a Progressive Self-Distillation (PSD) method, which progressively enhances the ability of network to mine more details for food recognition. The training of PSD simultaneously contains multiple self-distillations, in which a teacher network and a student network share the same embedding network. Since the student network receives a modified image from its teacher network by masking some informative regions, the teacher network outputs stronger semantic representations than the student network. Guided by such teacher network with stronger semantics, the student network is encouraged to mine more useful regions from the modified image by enhancing its own ability. The ability of the teacher network is also enhanced with the shared embedding network. By using progressive training, the teacher network incrementally improves its ability to mine more discriminative regions. In inference phase, only the teacher network is used without the help of the student network. Extensive experiments on three datasets demonstrate the effectiveness of our proposed method and state-of-the-art performance.
ISIA Food-500: A Dataset for Large-Scale Food Recognition via Stacked Global-Local Attention Network
Aug 13, 2020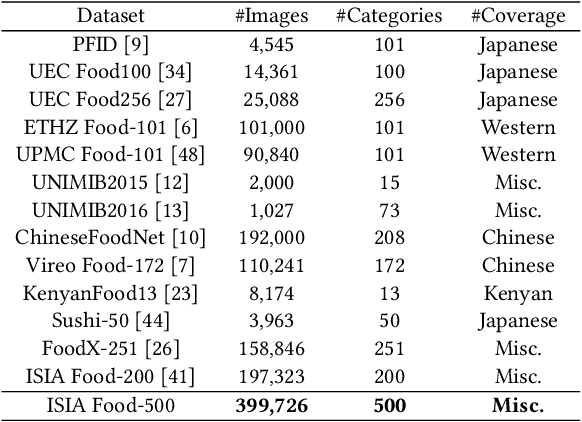

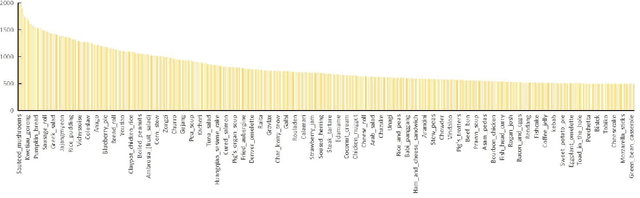
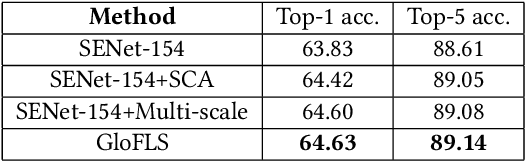
Food recognition has received more and more attention in the multimedia community for its various real-world applications, such as diet management and self-service restaurants. A large-scale ontology of food images is urgently needed for developing advanced large-scale food recognition algorithms, as well as for providing the benchmark dataset for such algorithms. To encourage further progress in food recognition, we introduce the dataset ISIA Food- 500 with 500 categories from the list in the Wikipedia and 399,726 images, a more comprehensive food dataset that surpasses existing popular benchmark datasets by category coverage and data volume. Furthermore, we propose a stacked global-local attention network, which consists of two sub-networks for food recognition. One subnetwork first utilizes hybrid spatial-channel attention to extract more discriminative features, and then aggregates these multi-scale discriminative features from multiple layers into global-level representation (e.g., texture and shape information about food). The other one generates attentional regions (e.g., ingredient relevant regions) from different regions via cascaded spatial transformers, and further aggregates these multi-scale regional features from different layers into local-level representation. These two types of features are finally fused as comprehensive representation for food recognition. Extensive experiments on ISIA Food-500 and other two popular benchmark datasets demonstrate the effectiveness of our proposed method, and thus can be considered as one strong baseline. The dataset, code and models can be found at http://123.57.42.89/FoodComputing-Dataset/ISIA-Food500.html.