 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFeature-Suppressed Contrast for Self-Supervised Food Pre-training
Aug 21, 2023



Most previous approaches for analyzing food images have relied on extensively annotated datasets, resulting in significant human labeling expenses due to the varied and intricate nature of such images. Inspired by the effectiveness of contrastive self-supervised methods in utilizing unlabelled data, weiqing explore leveraging these techniques on unlabelled food images. In contrastive self-supervised methods, two views are randomly generated from an image by data augmentations. However, regarding food images, the two views tend to contain similar informative contents, causing large mutual information, which impedes the efficacy of contrastive self-supervised learning. To address this problem, we propose Feature Suppressed Contrast (FeaSC) to reduce mutual information between views. As the similar contents of the two views are salient or highly responsive in the feature map, the proposed FeaSC uses a response-aware scheme to localize salient features in an unsupervised manner. By suppressing some salient features in one view while leaving another contrast view unchanged, the mutual information between the two views is reduced, thereby enhancing the effectiveness of contrast learning for self-supervised food pre-training. As a plug-and-play module, the proposed method consistently improves BYOL and SimSiam by 1.70\% $\sim$ 6.69\% classification accuracy on four publicly available food recognition datasets. Superior results have also been achieved on downstream segmentation tasks, demonstrating the effectiveness of the proposed method.
Transformer with Peak Suppression and Knowledge Guidance for Fine-grained Image Recognition
Jul 14, 2021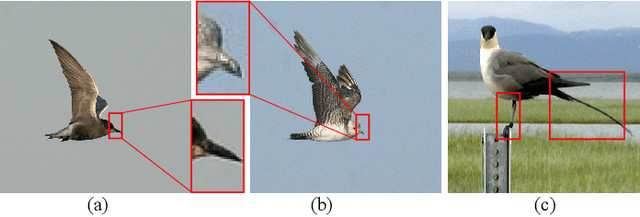



Fine-grained image recognition is challenging because discriminative clues are usually fragmented, whether from a single image or multiple images. Despite their significant improvements, most existing methods still focus on the most discriminative parts from a single image, ignoring informative details in other regions and lacking consideration of clues from other associated images. In this paper, we analyze the difficulties of fine-grained image recognition from a new perspective and propose a transformer architecture with the peak suppression module and knowledge guidance module, which respects the diversification of discriminative features in a single image and the aggregation of discriminative clues among multiple images. Specifically, the peak suppression module first utilizes a linear projection to convert the input image into sequential tokens. It then blocks the token based on the attention response generated by the transformer encoder. This module penalizes the attention to the most discriminative parts in the feature learning process, therefore, enhancing the information exploitation of the neglected regions. The knowledge guidance module compares the image-based representation generated from the peak suppression module with the learnable knowledge embedding set to obtain the knowledge response coefficients. Afterwards, it formalizes the knowledge learning as a classification problem using response coefficients as the classification scores. Knowledge embeddings and image-based representations are updated during training so that the knowledge embedding includes discriminative clues for different images. Finally, we incorporate the acquired knowledge embeddings into the image-based representations as comprehensive representations, leading to significantly higher performance. Extensive evaluations on the six popular datasets demonstrate the advantage of the proposed method.