 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHASS: Hardware-Aware Sparsity Search for Dataflow DNN Accelerator
Jun 05, 2024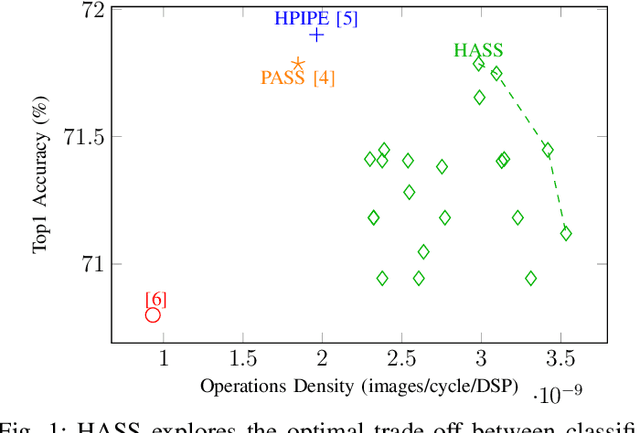
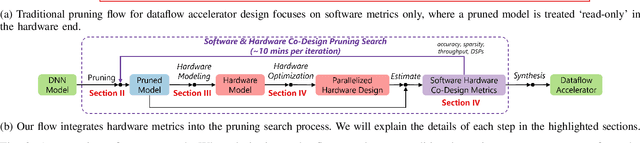
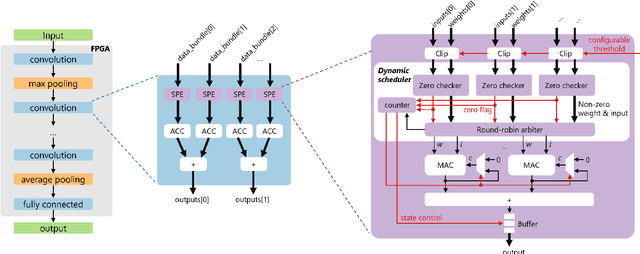
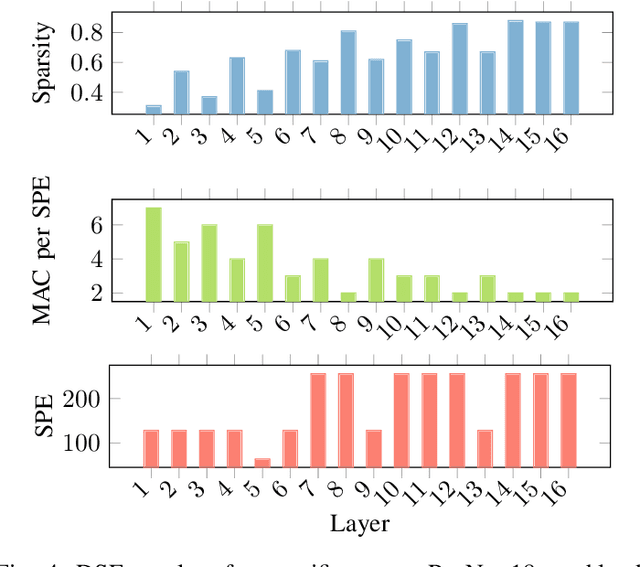
Deep Neural Networks (DNNs) excel in learning hierarchical representations from raw data, such as images, audio, and text. To compute these DNN models with high performance and energy efficiency, these models are usually deployed onto customized hardware accelerators. Among various accelerator designs, dataflow architecture has shown promising performance due to its layer-pipelined structure and its scalability in data parallelism. Exploiting weights and activations sparsity can further enhance memory storage and computation efficiency. However, existing approaches focus on exploiting sparsity in non-dataflow accelerators, which cannot be applied onto dataflow accelerators because of the large hardware design space introduced. As such, this could miss opportunities to find an optimal combination of sparsity features and hardware designs. In this paper, we propose a novel approach to exploit unstructured weights and activations sparsity for dataflow accelerators, using software and hardware co-optimization. We propose a Hardware-Aware Sparsity Search (HASS) to systematically determine an efficient sparsity solution for dataflow accelerators. Over a set of models, we achieve an efficiency improvement ranging from 1.3$\times$ to 4.2$\times$ compared to existing sparse designs, which are either non-dataflow or non-hardware-aware. Particularly, the throughput of MobileNetV3 can be optimized to 4895 images per second. HASS is open-source: \url{https://github.com/Yu-Zhewen/HASS}
SATAY: A Streaming Architecture Toolflow for Accelerating YOLO Models on FPGA Devices
Sep 04, 2023



AI has led to significant advancements in computer vision and image processing tasks, enabling a wide range of applications in real-life scenarios, from autonomous vehicles to medical imaging. Many of those applications require efficient object detection algorithms and complementary real-time, low latency hardware to perform inference of these algorithms. The YOLO family of models is considered the most efficient for object detection, having only a single model pass. Despite this, the complexity and size of YOLO models can be too computationally demanding for current edge-based platforms. To address this, we present SATAY: a Streaming Architecture Toolflow for Accelerating YOLO. This work tackles the challenges of deploying stateof-the-art object detection models onto FPGA devices for ultralow latency applications, enabling real-time, edge-based object detection. We employ a streaming architecture design for our YOLO accelerators, implementing the complete model on-chip in a deeply pipelined fashion. These accelerators are generated using an automated toolflow, and can target a range of suitable FPGA devices. We introduce novel hardware components to support the operations of YOLO models in a dataflow manner, and off-chip memory buffering to address the limited on-chip memory resources. Our toolflow is able to generate accelerator designs which demonstrate competitive performance and energy characteristics to GPU devices, and which outperform current state-of-the-art FPGA accelerators.
HARFLOW3D: A Latency-Oriented 3D-CNN Accelerator Toolflow for HAR on FPGA Devices
Apr 11, 2023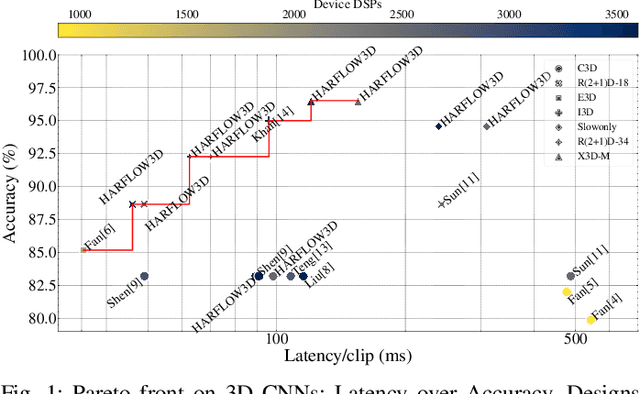
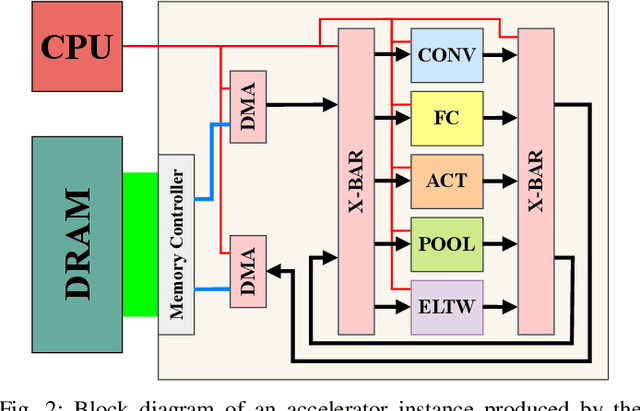
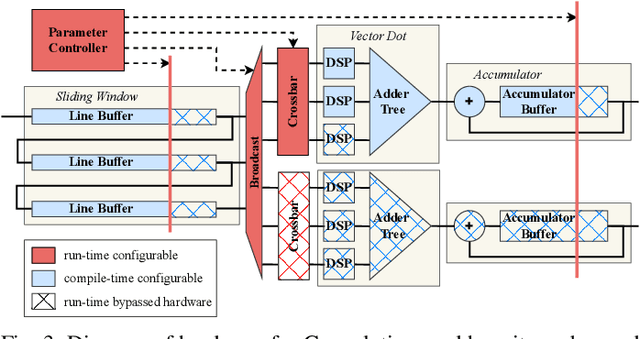
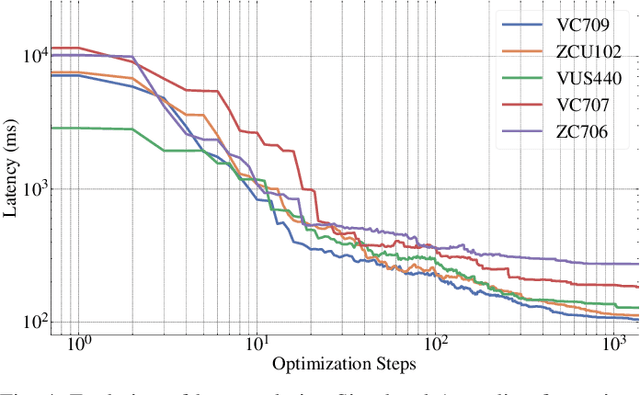
For Human Action Recognition tasks (HAR), 3D Convolutional Neural Networks have proven to be highly effective, achieving state-of-the-art results. This study introduces a novel streaming architecture based toolflow for mapping such models onto FPGAs considering the model's inherent characteristics and the features of the targeted FPGA device. The HARFLOW3D toolflow takes as input a 3D CNN in ONNX format and a description of the FPGA characteristics, generating a design that minimizes the latency of the computation. The toolflow is comprised of a number of parts, including i) a 3D CNN parser, ii) a performance and resource model, iii) a scheduling algorithm for executing 3D models on the generated hardware, iv) a resource-aware optimization engine tailored for 3D models, v) an automated mapping to synthesizable code for FPGAs. The ability of the toolflow to support a broad range of models and devices is shown through a number of experiments on various 3D CNN and FPGA system pairs. Furthermore, the toolflow has produced high-performing results for 3D CNN models that have not been mapped to FPGAs before, demonstrating the potential of FPGA-based systems in this space. Overall, HARFLOW3D has demonstrated its ability to deliver competitive latency compared to a range of state-of-the-art hand-tuned approaches being able to achieve up to 5$\times$ better performance compared to some of the existing works.