 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSMOF: Streaming Modern CNNs on FPGAs with Smart Off-Chip Eviction
Mar 27, 2024



Convolutional Neural Networks (CNNs) have demonstrated their effectiveness in numerous vision tasks. However, their high processing requirements necessitate efficient hardware acceleration to meet the application's performance targets. In the space of FPGAs, streaming-based dataflow architectures are often adopted by users, as significant performance gains can be achieved through layer-wise pipelining and reduced off-chip memory access by retaining data on-chip. However, modern topologies, such as the UNet, YOLO, and X3D models, utilise long skip connections, requiring significant on-chip storage and thus limiting the performance achieved by such system architectures. The paper addresses the above limitation by introducing weight and activation eviction mechanisms to off-chip memory along the computational pipeline, taking into account the available compute and memory resources. The proposed mechanism is incorporated into an existing toolflow, expanding the design space by utilising off-chip memory as a buffer. This enables the mapping of such modern CNNs to devices with limited on-chip memory, under the streaming architecture design approach. SMOF has demonstrated the capacity to deliver competitive and, in some cases, state-of-the-art performance across a spectrum of computer vision tasks, achieving up to 10.65 X throughput improvement compared to previous works.
From Detection to Action Recognition: An Edge-Based Pipeline for Robot Human Perception
Dec 06, 2023



Mobile service robots are proving to be increasingly effective in a range of applications, such as healthcare, monitoring Activities of Daily Living (ADL), and facilitating Ambient Assisted Living (AAL). These robots heavily rely on Human Action Recognition (HAR) to interpret human actions and intentions. However, for HAR to function effectively on service robots, it requires prior knowledge of human presence (human detection) and identification of individuals to monitor (human tracking). In this work, we propose an end-to-end pipeline that encompasses the entire process, starting from human detection and tracking, leading to action recognition. The pipeline is designed to operate in near real-time while ensuring all stages of processing are performed on the edge, reducing the need for centralised computation. To identify the most suitable models for our mobile robot, we conducted a series of experiments comparing state-of-the-art solutions based on both their detection performance and efficiency. To evaluate the effectiveness of our proposed pipeline, we proposed a dataset comprising daily household activities. By presenting our findings and analysing the results, we demonstrate the efficacy of our approach in enabling mobile robots to understand and respond to human behaviour in real-world scenarios relying mainly on the data from their RGB cameras.
SATAY: A Streaming Architecture Toolflow for Accelerating YOLO Models on FPGA Devices
Sep 04, 2023



AI has led to significant advancements in computer vision and image processing tasks, enabling a wide range of applications in real-life scenarios, from autonomous vehicles to medical imaging. Many of those applications require efficient object detection algorithms and complementary real-time, low latency hardware to perform inference of these algorithms. The YOLO family of models is considered the most efficient for object detection, having only a single model pass. Despite this, the complexity and size of YOLO models can be too computationally demanding for current edge-based platforms. To address this, we present SATAY: a Streaming Architecture Toolflow for Accelerating YOLO. This work tackles the challenges of deploying stateof-the-art object detection models onto FPGA devices for ultralow latency applications, enabling real-time, edge-based object detection. We employ a streaming architecture design for our YOLO accelerators, implementing the complete model on-chip in a deeply pipelined fashion. These accelerators are generated using an automated toolflow, and can target a range of suitable FPGA devices. We introduce novel hardware components to support the operations of YOLO models in a dataflow manner, and off-chip memory buffering to address the limited on-chip memory resources. Our toolflow is able to generate accelerator designs which demonstrate competitive performance and energy characteristics to GPU devices, and which outperform current state-of-the-art FPGA accelerators.
fpgaHART: A toolflow for throughput-oriented acceleration of 3D CNNs for HAR onto FPGAs
May 31, 2023



Surveillance systems, autonomous vehicles, human monitoring systems, and video retrieval are just few of the many applications in which 3D Convolutional Neural Networks are exploited. However, their extensive use is restricted by their high computational and memory requirements, especially when integrated into systems with limited resources. This study proposes a toolflow that optimises the mapping of 3D CNN models for Human Action Recognition onto FPGA devices, taking into account FPGA resources and off-chip memory characteristics. The proposed system employs Synchronous Dataflow (SDF) graphs to model the designs and introduces transformations to expand and explore the design space, resulting in high-throughput designs. A variety of 3D CNN models were evaluated using the proposed toolflow on multiple FPGA devices, demonstrating its potential to deliver competitive performance compared to earlier hand-tuned and model-specific designs.
FMM-X3D: FPGA-based modeling and mapping of X3D for Human Action Recognition
May 29, 2023



3D Convolutional Neural Networks are gaining increasing attention from researchers and practitioners and have found applications in many domains, such as surveillance systems, autonomous vehicles, human monitoring systems, and video retrieval. However, their widespread adoption is hindered by their high computational and memory requirements, especially when resource-constrained systems are targeted. This paper addresses the problem of mapping X3D, a state-of-the-art model in Human Action Recognition that achieves accuracy of 95.5\% in the UCF101 benchmark, onto any FPGA device. The proposed toolflow generates an optimised stream-based hardware system, taking into account the available resources and off-chip memory characteristics of the FPGA device. The generated designs push further the current performance-accuracy pareto front, and enable for the first time the targeting of such complex model architectures for the Human Action Recognition task.
HARFLOW3D: A Latency-Oriented 3D-CNN Accelerator Toolflow for HAR on FPGA Devices
Apr 11, 2023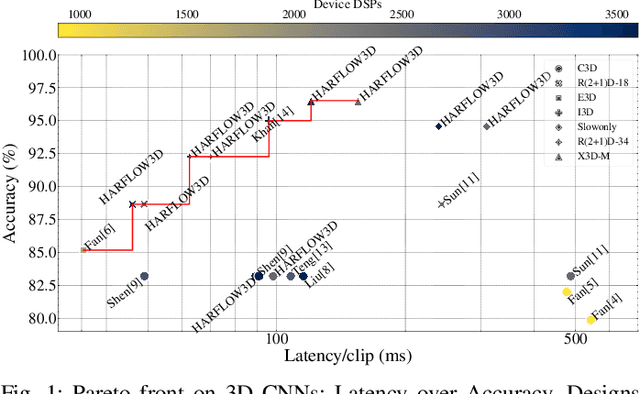
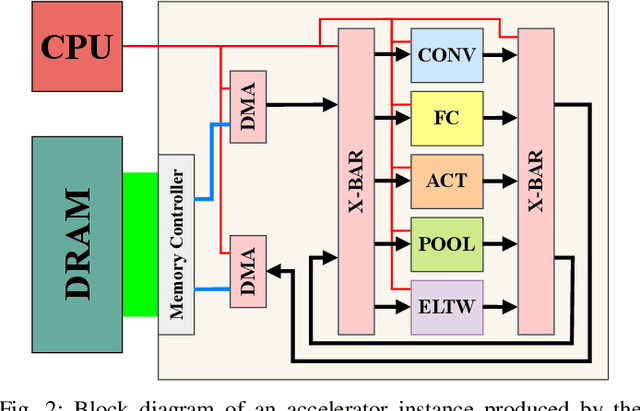
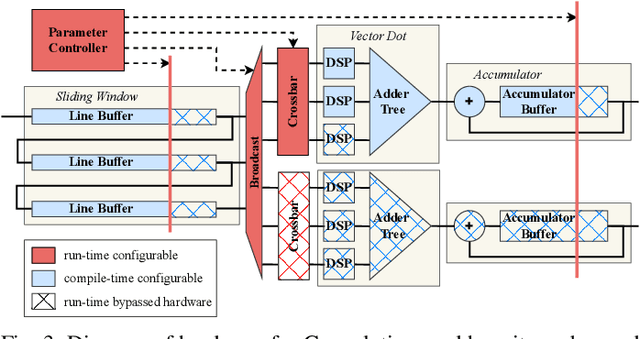
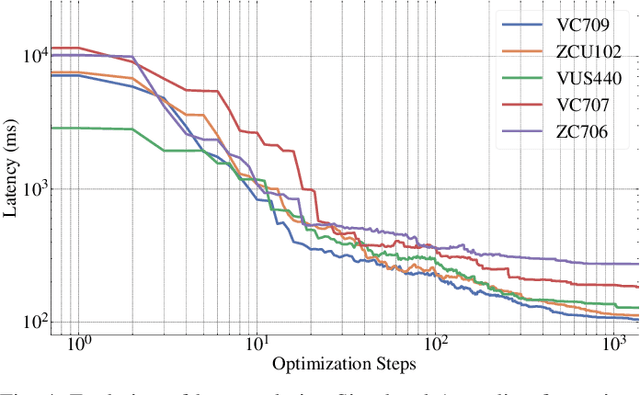
For Human Action Recognition tasks (HAR), 3D Convolutional Neural Networks have proven to be highly effective, achieving state-of-the-art results. This study introduces a novel streaming architecture based toolflow for mapping such models onto FPGAs considering the model's inherent characteristics and the features of the targeted FPGA device. The HARFLOW3D toolflow takes as input a 3D CNN in ONNX format and a description of the FPGA characteristics, generating a design that minimizes the latency of the computation. The toolflow is comprised of a number of parts, including i) a 3D CNN parser, ii) a performance and resource model, iii) a scheduling algorithm for executing 3D models on the generated hardware, iv) a resource-aware optimization engine tailored for 3D models, v) an automated mapping to synthesizable code for FPGAs. The ability of the toolflow to support a broad range of models and devices is shown through a number of experiments on various 3D CNN and FPGA system pairs. Furthermore, the toolflow has produced high-performing results for 3D CNN models that have not been mapped to FPGAs before, demonstrating the potential of FPGA-based systems in this space. Overall, HARFLOW3D has demonstrated its ability to deliver competitive latency compared to a range of state-of-the-art hand-tuned approaches being able to achieve up to 5$\times$ better performance compared to some of the existing works.