 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Exit Semantic Segmentation Networks
Paper and Code
Jun 07, 2021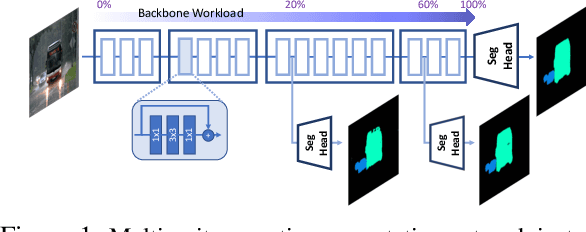


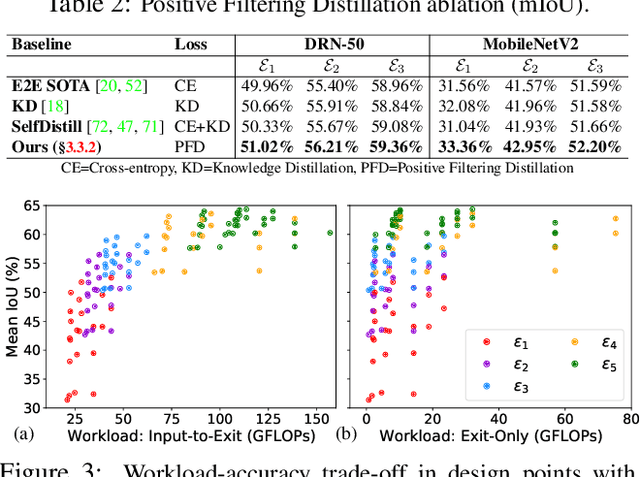
Semantic segmentation arises as the backbone of many vision systems, spanning from self-driving cars and robot navigation to augmented reality and teleconferencing. Frequently operating under stringent latency constraints within a limited resource envelope, optimising for efficient execution becomes important. To this end, we propose a framework for converting state-of-the-art segmentation models to MESS networks; specially trained CNNs that employ parametrised early exits along their depth to save computation during inference on easier samples. Designing and training such networks naively can hurt performance. Thus, we propose a two-staged training process that pushes semantically important features early in the network. We co-optimise the number, placement and architecture of the attached segmentation heads, along with the exit policy, to adapt to the device capabilities and application-specific requirements. Optimising for speed, MESS networks can achieve latency gains of up to 2.83x over state-of-the-art methods with no accuracy degradation. Accordingly, optimising for accuracy, we achieve an improvement of up to 5.33 pp, under the same computational budget.