 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncertaintyRAG: Span-Level Uncertainty Enhanced Long-Context Modeling for Retrieval-Augmented Generation
Paper and Code
Oct 03, 2024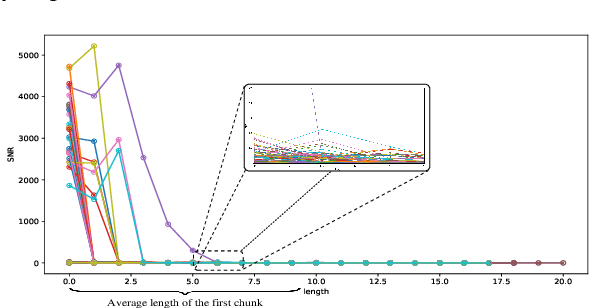
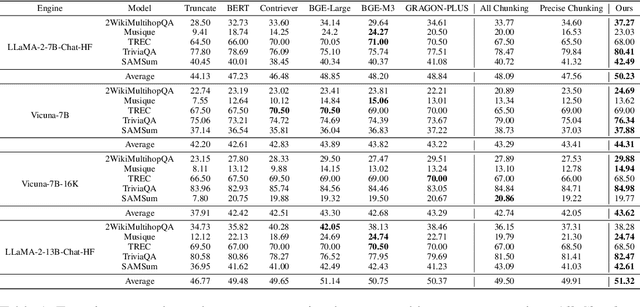


We present UncertaintyRAG, a novel approach for long-context Retrieval-Augmented Generation (RAG) that utilizes Signal-to-Noise Ratio (SNR)-based span uncertainty to estimate similarity between text chunks. This span uncertainty enhances model calibration, improving robustness and mitigating semantic inconsistencies introduced by random chunking. Leveraging this insight, we propose an efficient unsupervised learning technique to train the retrieval model, alongside an effective data sampling and scaling strategy. UncertaintyRAG outperforms baselines by 2.03% on LLaMA-2-7B, achieving state-of-the-art results while using only 4% of the training data compared to other advanced open-source retrieval models under distribution shift settings. Our method demonstrates strong calibration through span uncertainty, leading to improved generalization and robustness in long-context RAG tasks. Additionally, UncertaintyRAG provides a lightweight retrieval model that can be integrated into any large language model with varying context window lengths, without the need for fine-tuning, showcasing the flexibility of our approach.