 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRegionGPT: Towards Region Understanding Vision Language Model
Paper and Code


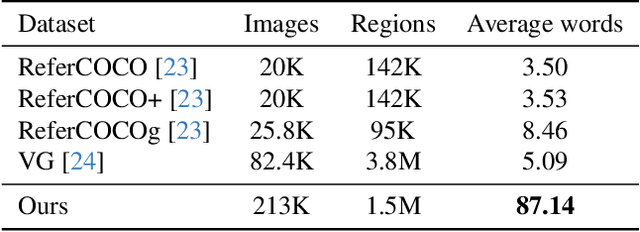

Vision language models (VLMs) have experienced rapid advancements through the integration of large language models (LLMs) with image-text pairs, yet they struggle with detailed regional visual understanding due to limited spatial awareness of the vision encoder, and the use of coarse-grained training data that lacks detailed, region-specific captions. To address this, we introduce RegionGPT (short as RGPT), a novel framework designed for complex region-level captioning and understanding. RGPT enhances the spatial awareness of regional representation with simple yet effective modifications to existing visual encoders in VLMs. We further improve performance on tasks requiring a specific output scope by integrating task-guided instruction prompts during both training and inference phases, while maintaining the model's versatility for general-purpose tasks. Additionally, we develop an automated region caption data generation pipeline, enriching the training set with detailed region-level captions. We demonstrate that a universal RGPT model can be effectively applied and significantly enhancing performance across a range of region-level tasks, including but not limited to complex region descriptions, reasoning, object classification, and referring expressions comprehension.