 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRange and Bird's Eye View Fused Cross-Modal Visual Place Recognition
Paper and Code
Feb 17, 2025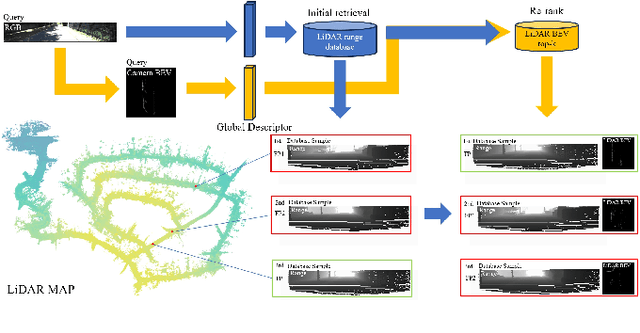
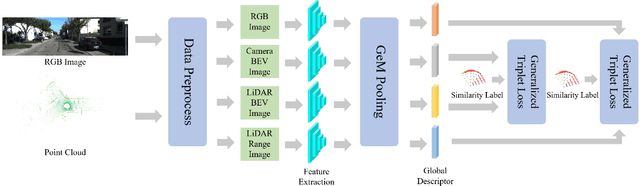
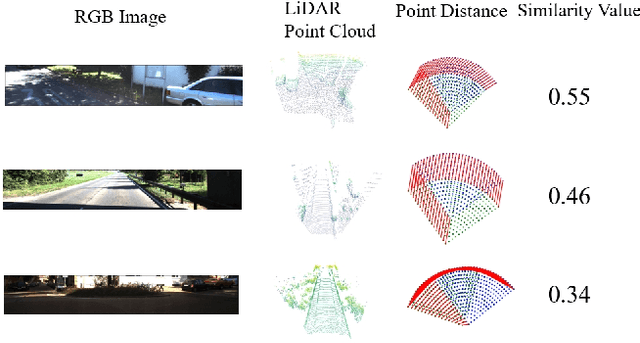
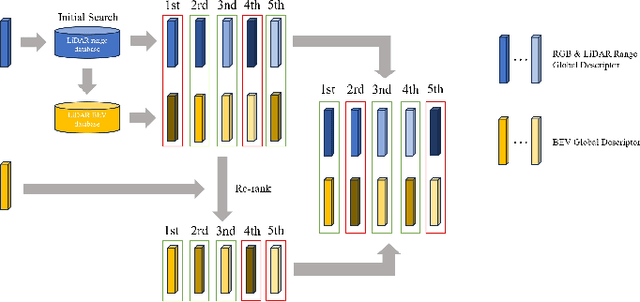
Image-to-point cloud cross-modal Visual Place Recognition (VPR) is a challenging task where the query is an RGB image, and the database samples are LiDAR point clouds. Compared to single-modal VPR, this approach benefits from the widespread availability of RGB cameras and the robustness of point clouds in providing accurate spatial geometry and distance information. However, current methods rely on intermediate modalities that capture either the vertical or horizontal field of view, limiting their ability to fully exploit the complementary information from both sensors. In this work, we propose an innovative initial retrieval + re-rank method that effectively combines information from range (or RGB) images and Bird's Eye View (BEV) images. Our approach relies solely on a computationally efficient global descriptor similarity search process to achieve re-ranking. Additionally, we introduce a novel similarity label supervision technique to maximize the utility of limited training data. Specifically, we employ points average distance to approximate appearance similarity and incorporate an adaptive margin, based on similarity differences, into the vanilla triplet loss. Experimental results on the KITTI dataset demonstrate that our method significantly outperforms state-of-the-art approaches.