 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Security and Strengthening Defenses in Automated Short-Answer Grading Systems
Apr 30, 2025This study examines vulnerabilities in transformer-based automated short-answer grading systems used in medical education, with a focus on how these systems can be manipulated through adversarial gaming strategies. Our research identifies three main types of gaming strategies that exploit the system's weaknesses, potentially leading to false positives. To counteract these vulnerabilities, we implement several adversarial training methods designed to enhance the systems' robustness. Our results indicate that these methods significantly reduce the susceptibility of grading systems to such manipulations, especially when combined with ensemble techniques like majority voting and ridge regression, which further improve the system's defense against sophisticated adversarial inputs. Additionally, employing large language models such as GPT-4 with varied prompting techniques has shown promise in recognizing and scoring gaming strategies effectively. The findings underscore the importance of continuous improvements in AI-driven educational tools to ensure their reliability and fairness in high-stakes settings.
Classifying Referential and Non-referential It Using Gaze
Jun 23, 2020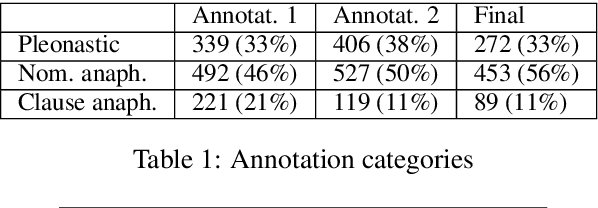
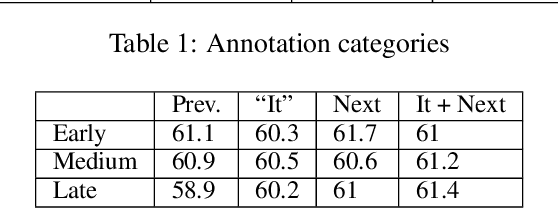
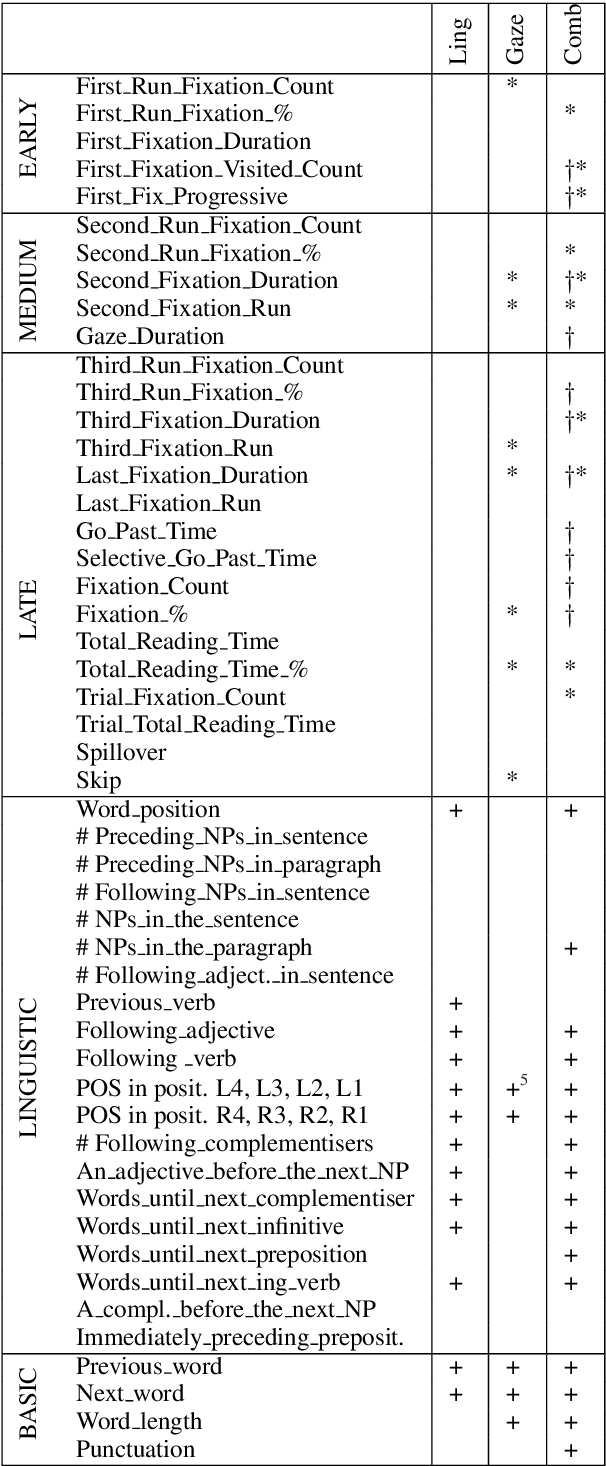
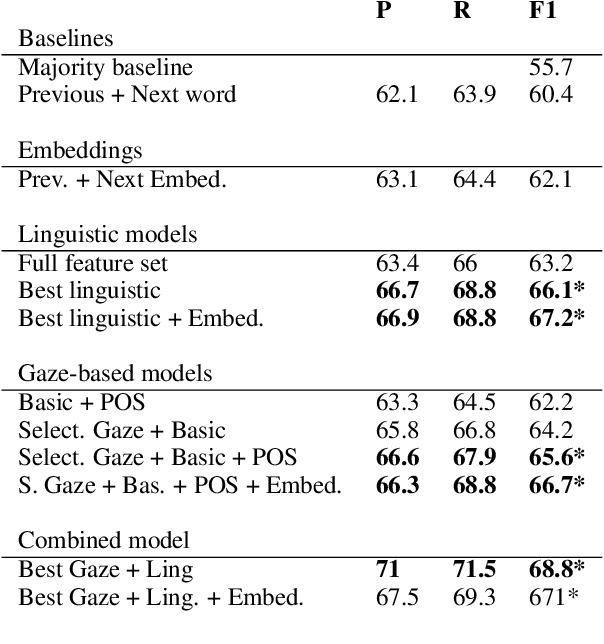
When processing a text, humans and machines must disambiguate between different uses of the pronoun it, including non-referential, nominal anaphoric or clause anaphoric ones. In this paper, we use eye-tracking data to learn how humans perform this disambiguation. We use this knowledge to improve the automatic classification of it. We show that by using gaze data and a POS-tagger we are able to significantly outperform a common baseline and classify between three categories of it with an accuracy comparable to that of linguisticbased approaches. In addition, the discriminatory power of specific gaze features informs the way humans process the pronoun, which, to the best of our knowledge, has not been explored using data from a natural reading task.