 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClassifying Referential and Non-referential It Using Gaze
Paper and Code
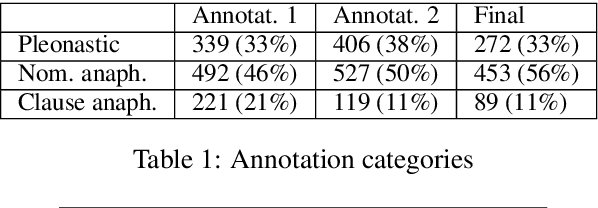
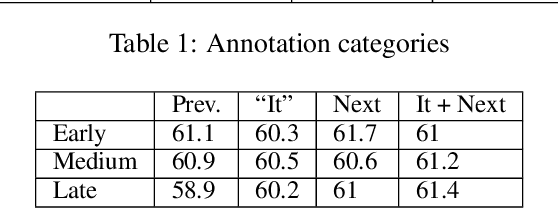
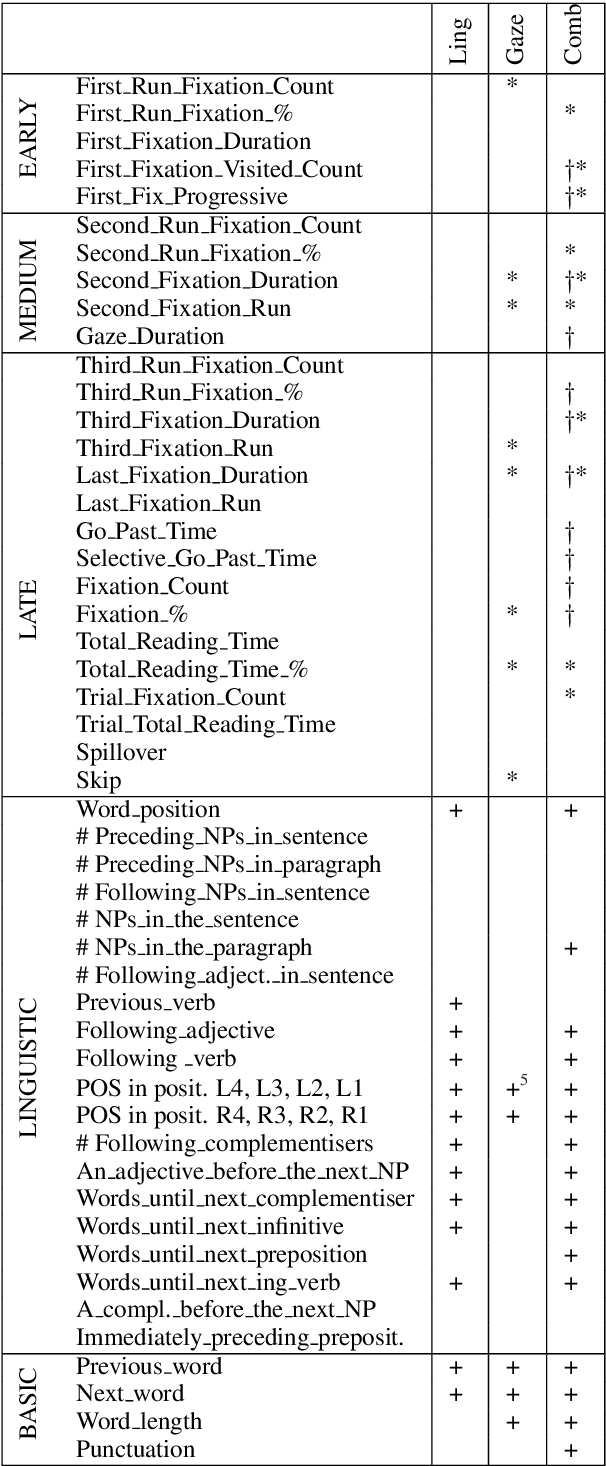
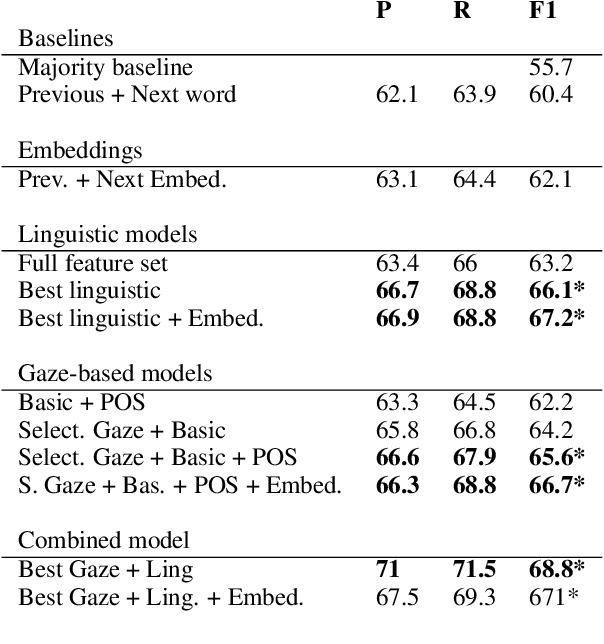
When processing a text, humans and machines must disambiguate between different uses of the pronoun it, including non-referential, nominal anaphoric or clause anaphoric ones. In this paper, we use eye-tracking data to learn how humans perform this disambiguation. We use this knowledge to improve the automatic classification of it. We show that by using gaze data and a POS-tagger we are able to significantly outperform a common baseline and classify between three categories of it with an accuracy comparable to that of linguisticbased approaches. In addition, the discriminatory power of specific gaze features informs the way humans process the pronoun, which, to the best of our knowledge, has not been explored using data from a natural reading task.