Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicting Lexical Complexity in English Texts
Paper and Code
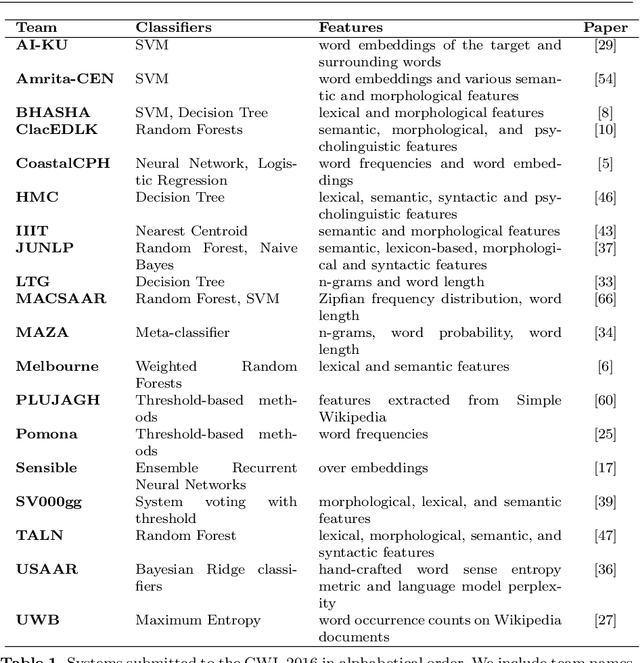
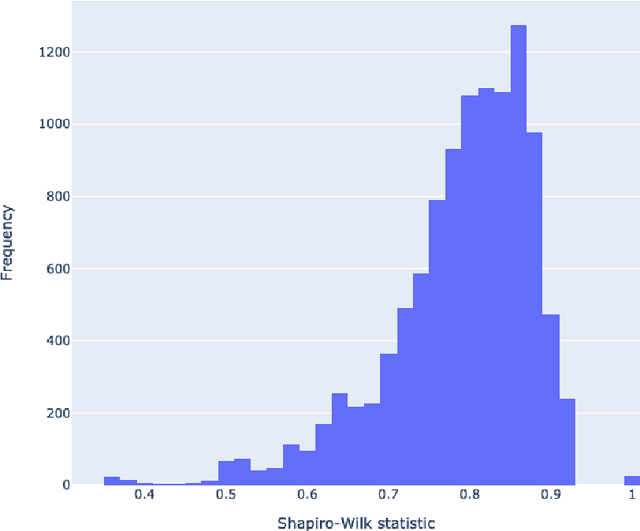
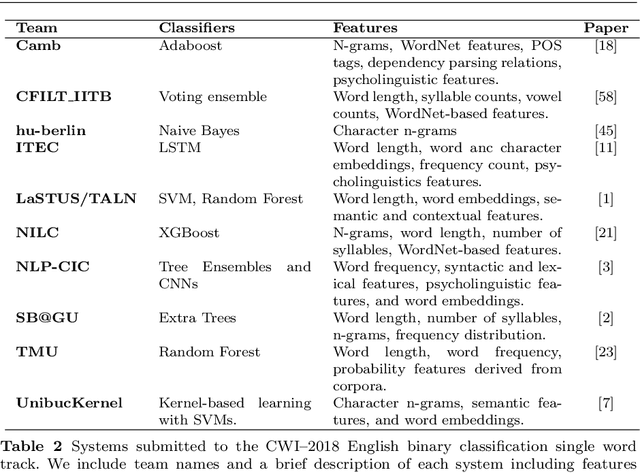
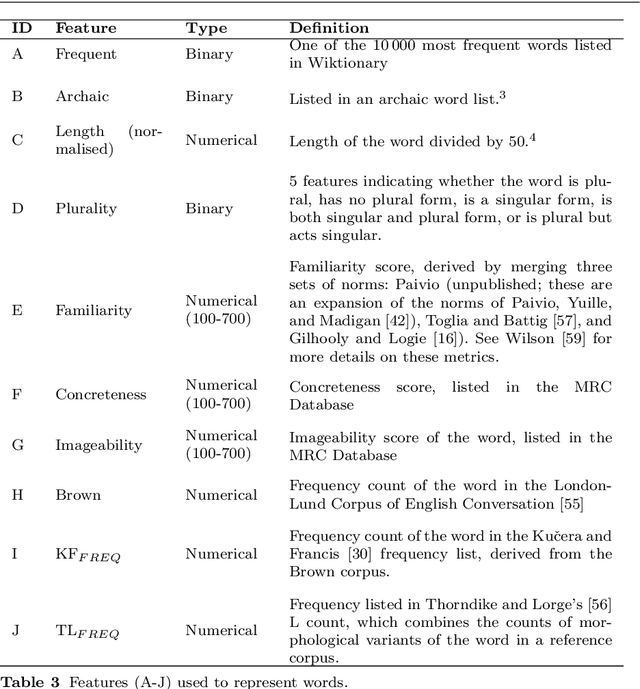
The first step in most text simplification is to predict which words are considered complex for a given target population before carrying out lexical substitution. This task is commonly referred to as Complex Word Identification (CWI) and it is often modelled as a supervised classification problem. For training such systems, annotated datasets in which words and sometimes multi-word expressions are labelled regarding complexity are required. In this paper we analyze previous work carried out in this task and investigate the properties of complex word identification datasets for English.
View paper on