 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemEval-2021 Task 1: Lexical Complexity Prediction
Jun 01, 2021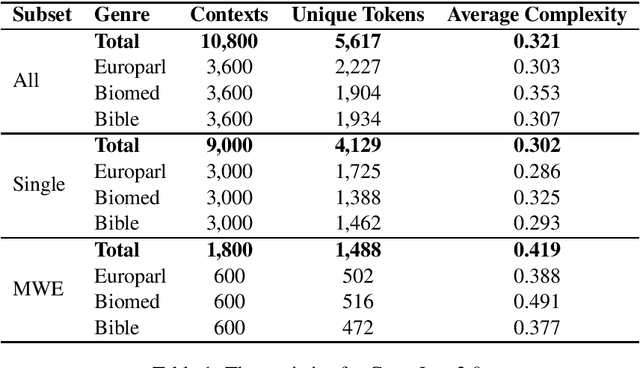
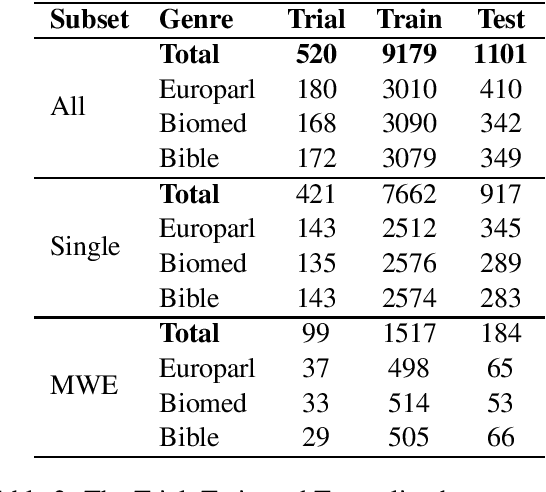
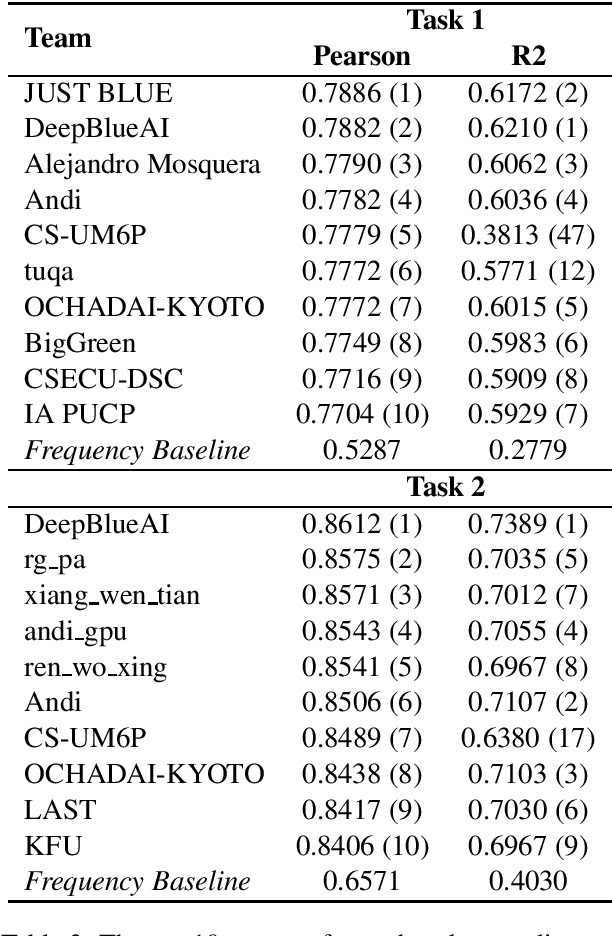
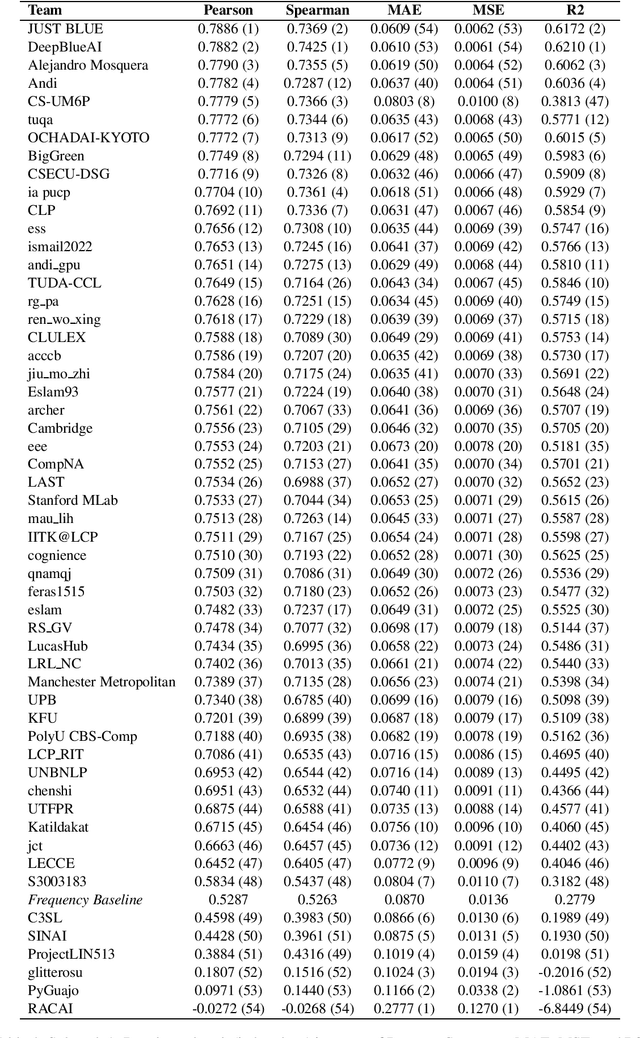
This paper presents the results and main findings of SemEval-2021 Task 1 - Lexical Complexity Prediction. We provided participants with an augmented version of the CompLex Corpus (Shardlow et al 2020). CompLex is an English multi-domain corpus in which words and multi-word expressions (MWEs) were annotated with respect to their complexity using a five point Likert scale. SemEval-2021 Task 1 featured two Sub-tasks: Sub-task 1 focused on single words and Sub-task 2 focused on MWEs. The competition attracted 198 teams in total, of which 54 teams submitted official runs on the test data to Sub-task 1 and 37 to Sub-task 2.
Experiments in Cuneiform Language Identification
Apr 27, 2019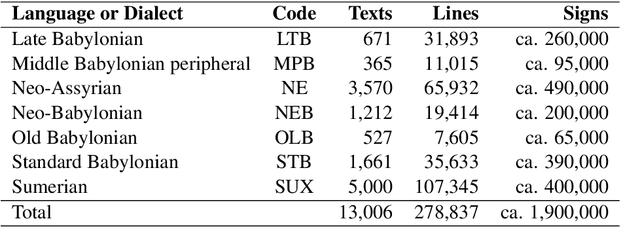
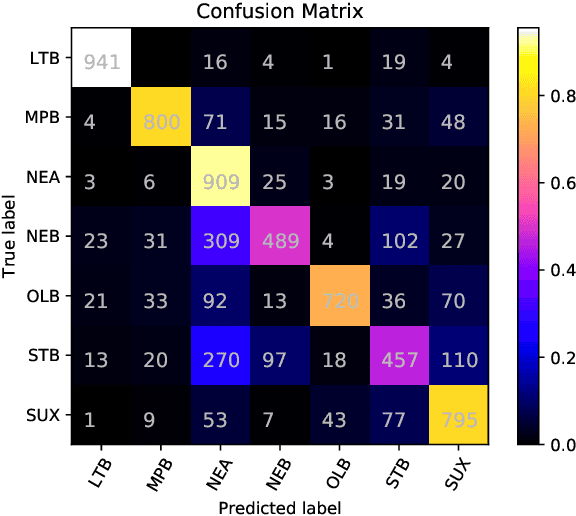
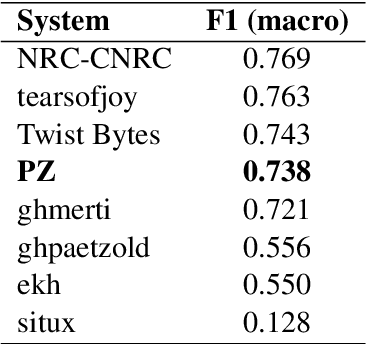
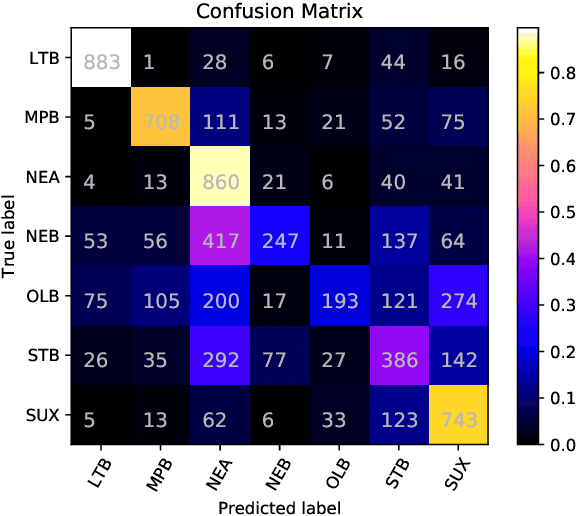
This paper presents methods to discriminate between languages and dialects written in Cuneiform script, one of the first writing systems in the world. We report the results obtained by the PZ team in the Cuneiform Language Identification (CLI) shared task organized within the scope of the VarDial Evaluation Campaign 2019. The task included two languages, Sumerian and Akkadian. The latter is divided into six dialects: Old Babylonian, Middle Babylonian peripheral, Standard Babylonian, Neo Babylonian, Late Babylonian, and Neo Assyrian. We approach the task using a meta-classifier trained on various SVM models and we show the effectiveness of the system for this task. Our submission achieved 0.738 F1 score in discriminating between the seven languages and dialects and it was ranked fourth in the competition among eight teams.
UTFPR at SemEval-2019 Task 5: Hate Speech Identification with Recurrent Neural Networks
Apr 16, 2019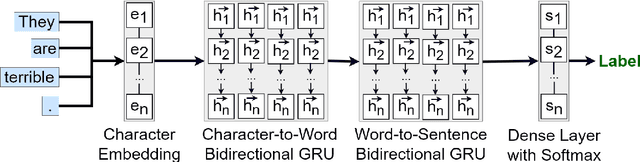
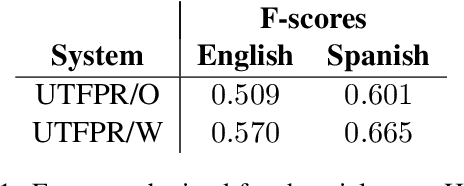
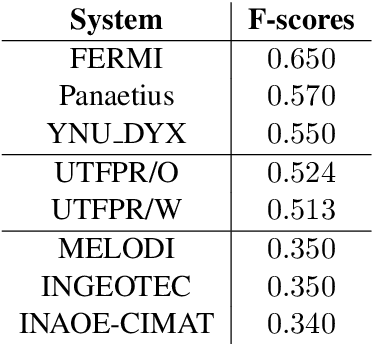

In this paper we revisit the problem of automatically identifying hate speech in posts from social media. We approach the task using a system based on minimalistic compositional Recurrent Neural Networks (RNN). We tested our approach on the SemEval-2019 Task 5: Multilingual Detection of Hate Speech Against Immigrants and Women in Twitter (HatEval) shared task dataset. The dataset made available by the HatEval organizers contained English and Spanish posts retrieved from Twitter annotated with respect to the presence of hateful content and its target. In this paper we present the results obtained by our system in comparison to the other entries in the shared task. Our system achieved competitive performance ranking 7th in sub-task A out of 62 systems in the English track.
Vicinity-Driven Paragraph and Sentence Alignment for Comparable Corpora
Dec 13, 2016Parallel corpora have driven great progress in the field of Text Simplification. However, most sentence alignment algorithms either offer a limited range of alignment types supported, or simply ignore valuable clues present in comparable documents. We address this problem by introducing a new set of flexible vicinity-driven paragraph and sentence alignment algorithms that 1-N, N-1, N-N and long distance null alignments without the need for hard-to-replicate supervised models.