 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExperiments in Cuneiform Language Identification
Paper and Code
Apr 27, 2019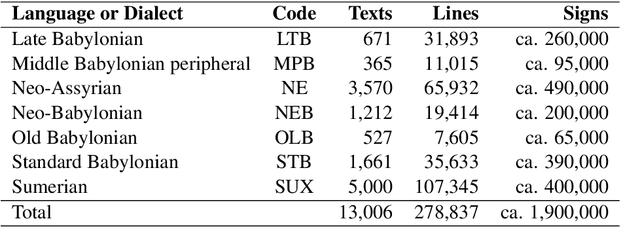
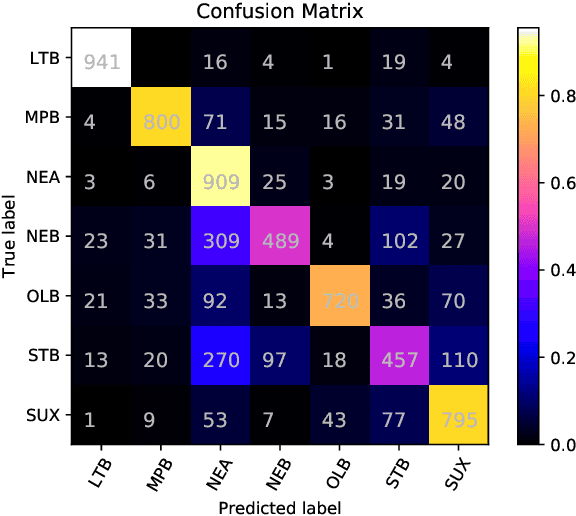
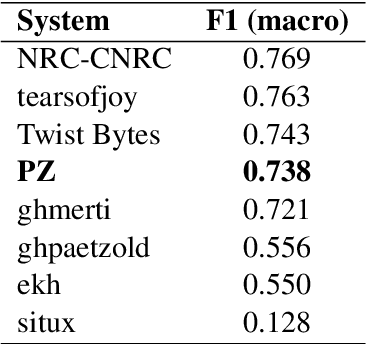
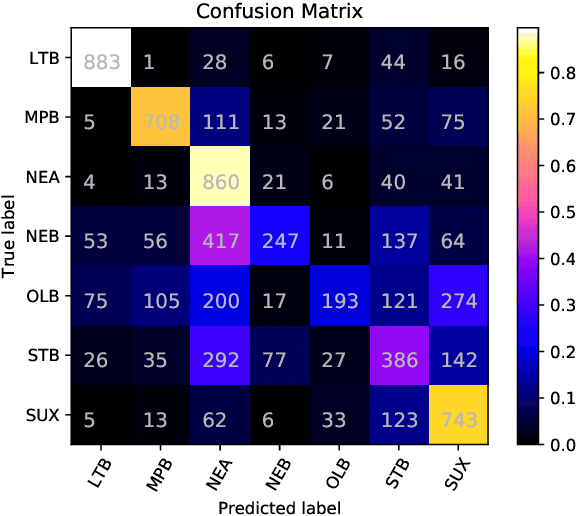
This paper presents methods to discriminate between languages and dialects written in Cuneiform script, one of the first writing systems in the world. We report the results obtained by the PZ team in the Cuneiform Language Identification (CLI) shared task organized within the scope of the VarDial Evaluation Campaign 2019. The task included two languages, Sumerian and Akkadian. The latter is divided into six dialects: Old Babylonian, Middle Babylonian peripheral, Standard Babylonian, Neo Babylonian, Late Babylonian, and Neo Assyrian. We approach the task using a meta-classifier trained on various SVM models and we show the effectiveness of the system for this task. Our submission achieved 0.738 F1 score in discriminating between the seven languages and dialects and it was ranked fourth in the competition among eight teams.