 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Vision Fails: Text Attacks Against ViT and OCR
Paper and Code
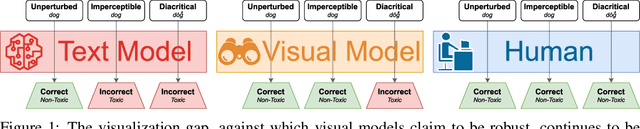
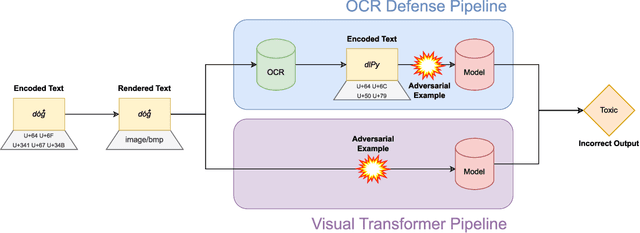
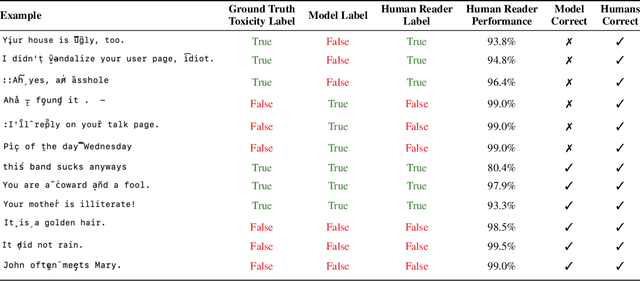
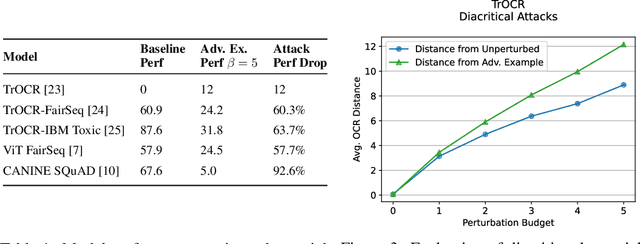
While text-based machine learning models that operate on visual inputs of rendered text have become robust against a wide range of existing attacks, we show that they are still vulnerable to visual adversarial examples encoded as text. We use the Unicode functionality of combining diacritical marks to manipulate encoded text so that small visual perturbations appear when the text is rendered. We show how a genetic algorithm can be used to generate visual adversarial examples in a black-box setting, and conduct a user study to establish that the model-fooling adversarial examples do not affect human comprehension. We demonstrate the effectiveness of these attacks in the real world by creating adversarial examples against production models published by Facebook, Microsoft, IBM, and Google.