 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Perturbation Approach to Unconstrained Linear Bandits
Mar 30, 2026We revisit the standard perturbation-based approach of Abernethy et al. (2008) in the context of unconstrained Bandit Linear Optimization (uBLO). We show the surprising result that in the unconstrained setting, this approach effectively reduces Bandit Linear Optimization (BLO) to a standard Online Linear Optimization (OLO) problem. Our framework improves on prior work in several ways. First, we derive expected-regret guarantees when our perturbation scheme is combined with comparator-adaptive OLO algorithms, leading to new insights about the impact of different adversarial models on the resulting comparator-adaptive rates. We also extend our analysis to dynamic regret, obtaining the optimal $\sqrt{P_T}$ path-length dependencies without prior knowledge of $P_T$. We then develop the first high-probability guarantees for both static and dynamic regret in uBLO. Finally, we discuss lower bounds on the static regret, and prove the folklore $Ω(\sqrt{dT})$ rate for adversarial linear bandits on the unit Euclidean ball, which is of independent interest.
Improved learning rates in multi-unit uniform price auctions
Jan 17, 2025

Motivated by the strategic participation of electricity producers in electricity day-ahead market, we study the problem of online learning in repeated multi-unit uniform price auctions focusing on the adversarial opposing bid setting. The main contribution of this paper is the introduction of a new modeling of the bid space. Indeed, we prove that a learning algorithm leveraging the structure of this problem achieves a regret of $\tilde{O}(K^{4/3}T^{2/3})$ under bandit feedback, improving over the bound of $\tilde{O}(K^{7/4}T^{3/4})$ previously obtained in the literature. This improved regret rate is tight up to logarithmic terms. Inspired by electricity reserve markets, we further introduce a different feedback model under which all winning bids are revealed. This feedback interpolates between the full-information and bandit scenarios depending on the auctions' results. We prove that, under this feedback, the algorithm that we propose achieves regret $\tilde{O}(K^{5/2}\sqrt{T})$.
The Value of Reward Lookahead in Reinforcement Learning
Mar 18, 2024In reinforcement learning (RL), agents sequentially interact with changing environments while aiming to maximize the obtained rewards. Usually, rewards are observed only after acting, and so the goal is to maximize the expected cumulative reward. Yet, in many practical settings, reward information is observed in advance -- prices are observed before performing transactions; nearby traffic information is partially known; and goals are oftentimes given to agents prior to the interaction. In this work, we aim to quantifiably analyze the value of such future reward information through the lens of competitive analysis. In particular, we measure the ratio between the value of standard RL agents and that of agents with partial future-reward lookahead. We characterize the worst-case reward distribution and derive exact ratios for the worst-case reward expectations. Surprisingly, the resulting ratios relate to known quantities in offline RL and reward-free exploration. We further provide tight bounds for the ratio given the worst-case dynamics. Our results cover the full spectrum between observing the immediate rewards before acting to observing all the rewards before the interaction starts.
A General Recipe for the Analysis of Randomized Multi-Armed Bandit Algorithms
Mar 10, 2023In this paper we propose a general methodology to derive regret bounds for randomized multi-armed bandit algorithms. It consists in checking a set of sufficient conditions on the sampling probability of each arm and on the family of distributions to prove a logarithmic regret. As a direct application we revisit two famous bandit algorithms, Minimum Empirical Divergence (MED) and Thompson Sampling (TS), under various models for the distributions including single parameter exponential families, Gaussian distributions, bounded distributions, or distributions satisfying some conditions on their moments. In particular, we prove that MED is asymptotically optimal for all these models, but also provide a simple regret analysis of some TS algorithms for which the optimality is already known. We then further illustrate the interest of our approach, by analyzing a new Non-Parametric TS algorithm (h-NPTS), adapted to some families of unbounded reward distributions with a bounded h-moment. This model can for instance capture some non-parametric families of distributions whose variance is upper bounded by a known constant.
Towards an efficient and risk aware strategy for guiding farmers in identifying best crop management
Oct 10, 2022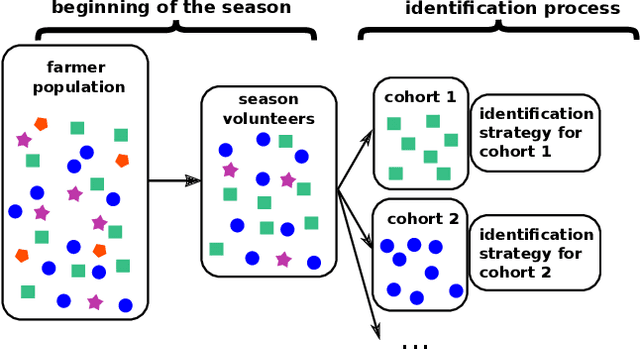

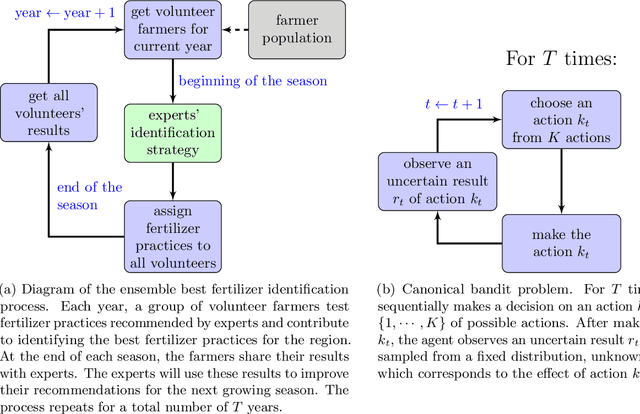

Identification of best performing fertilizer practices among a set of contrasting practices with field trials is challenging as crop losses are costly for farmers. To identify best management practices, an ''intuitive strategy'' would be to set multi-year field trials with equal proportion of each practice to test. Our objective was to provide an identification strategy using a bandit algorithm that was better at minimizing farmers' losses occurring during the identification, compared with the ''intuitive strategy''. We used a modification of the Decision Support Systems for Agro-Technological Transfer (DSSAT) crop model to mimic field trial responses, with a case-study in Southern Mali. We compared fertilizer practices using a risk-aware measure, the Conditional Value-at-Risk (CVaR), and a novel agronomic metric, the Yield Excess (YE). YE accounts for both grain yield and agronomic nitrogen use efficiency. The bandit-algorithm performed better than the intuitive strategy: it increased, in most cases, farmers' protection against worst outcomes. This study is a methodological step which opens up new horizons for risk-aware ensemble identification of the performance of contrasting crop management practices in real conditions.
Top Two Algorithms Revisited
Jun 13, 2022

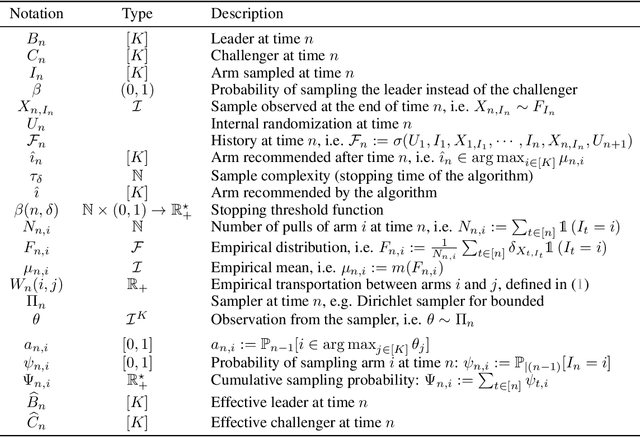
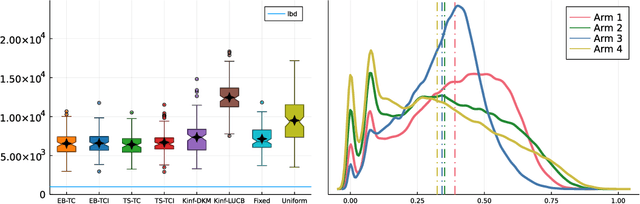
Top Two algorithms arose as an adaptation of Thompson sampling to best arm identification in multi-armed bandit models (Russo, 2016), for parametric families of arms. They select the next arm to sample from by randomizing among two candidate arms, a leader and a challenger. Despite their good empirical performance, theoretical guarantees for fixed-confidence best arm identification have only been obtained when the arms are Gaussian with known variances. In this paper, we provide a general analysis of Top Two methods, which identifies desirable properties of the leader, the challenger, and the (possibly non-parametric) distributions of the arms. As a result, we obtain theoretically supported Top Two algorithms for best arm identification with bounded distributions. Our proof method demonstrates in particular that the sampling step used to select the leader inherited from Thompson sampling can be replaced by other choices, like selecting the empirical best arm.
Efficient Algorithms for Extreme Bandits
Mar 21, 2022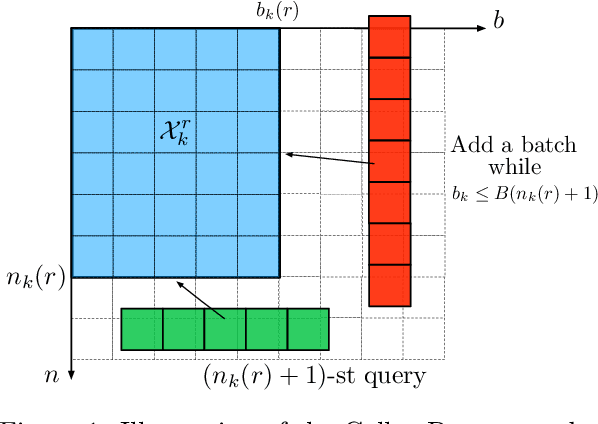
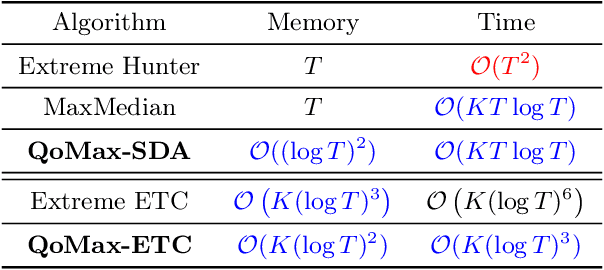
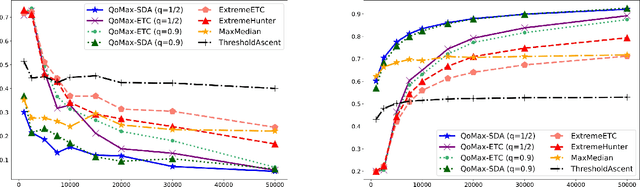
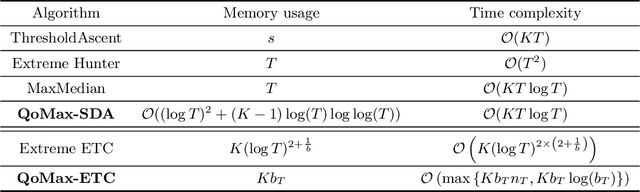
In this paper, we contribute to the Extreme Bandit problem, a variant of Multi-Armed Bandits in which the learner seeks to collect the largest possible reward. We first study the concentration of the maximum of i.i.d random variables under mild assumptions on the tail of the rewards distributions. This analysis motivates the introduction of Quantile of Maxima (QoMax). The properties of QoMax are sufficient to build an Explore-Then-Commit (ETC) strategy, QoMax-ETC, achieving strong asymptotic guarantees despite its simplicity. We then propose and analyze a more adaptive, anytime algorithm, QoMax-SDA, which combines QoMax with a subsampling method recently introduced by Baudry et al. (2021). Both algorithms are more efficient than existing approaches in two aspects (1) they lead to better empirical performance (2) they enjoy a significant reduction of the memory and time complexities.
From Optimality to Robustness: Dirichlet Sampling Strategies in Stochastic Bandits
Nov 18, 2021

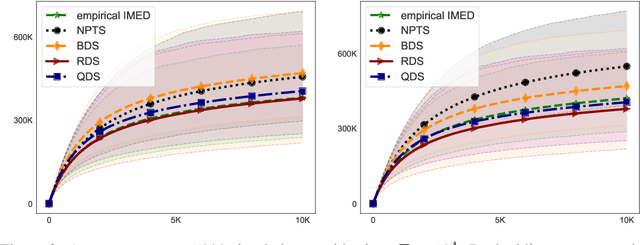

The stochastic multi-arm bandit problem has been extensively studied under standard assumptions on the arm's distribution (e.g bounded with known support, exponential family, etc). These assumptions are suitable for many real-world problems but sometimes they require knowledge (on tails for instance) that may not be precisely accessible to the practitioner, raising the question of the robustness of bandit algorithms to model misspecification. In this paper we study a generic Dirichlet Sampling (DS) algorithm, based on pairwise comparisons of empirical indices computed with re-sampling of the arms' observations and a data-dependent exploration bonus. We show that different variants of this strategy achieve provably optimal regret guarantees when the distributions are bounded and logarithmic regret for semi-bounded distributions with a mild quantile condition. We also show that a simple tuning achieve robustness with respect to a large class of unbounded distributions, at the cost of slightly worse than logarithmic asymptotic regret. We finally provide numerical experiments showing the merits of DS in a decision-making problem on synthetic agriculture data.
On Limited-Memory Subsampling Strategies for Bandits
Jun 21, 2021
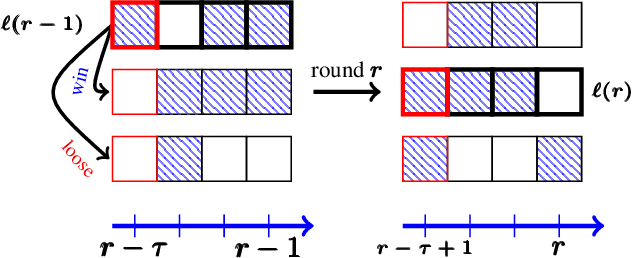
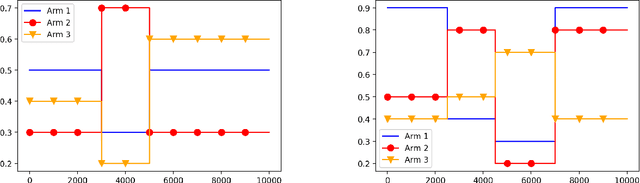

There has been a recent surge of interest in nonparametric bandit algorithms based on subsampling. One drawback however of these approaches is the additional complexity required by random subsampling and the storage of the full history of rewards. Our first contribution is to show that a simple deterministic subsampling rule, proposed in the recent work of Baudry et al. (2020) under the name of ''last-block subsampling'', is asymptotically optimal in one-parameter exponential families. In addition, we prove that these guarantees also hold when limiting the algorithm memory to a polylogarithmic function of the time horizon. These findings open up new perspectives, in particular for non-stationary scenarios in which the arm distributions evolve over time. We propose a variant of the algorithm in which only the most recent observations are used for subsampling, achieving optimal regret guarantees under the assumption of a known number of abrupt changes. Extensive numerical simulations highlight the merits of this approach, particularly when the changes are not only affecting the means of the rewards.
Thompson Sampling for CVaR Bandits
Dec 10, 2020

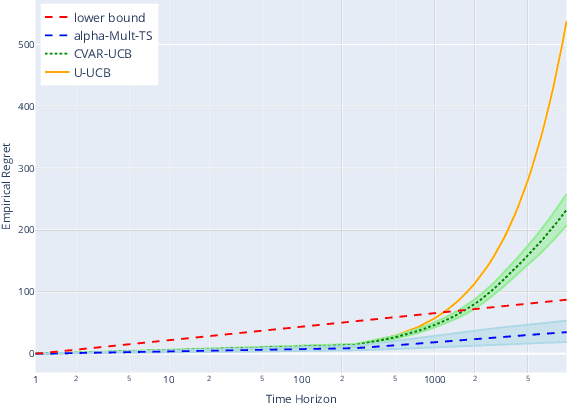
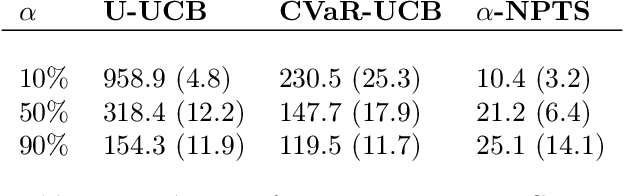
Risk awareness is an important feature to formulate a variety of real world problems. In this paper we study a multi-arm bandit problem in which the quality of each arm is measured by the Conditional Value at Risk (CVaR) at some level {\alpha} of the reward distribution. While existing works in this setting mainly focus on Upper Confidence Bound algorithms, we introduce the first Thompson Sampling approaches for CVaR bandits. Building on a recent work by Riou and Honda (2020), we propose {\alpha}-NPTS for bounded rewards and {\alpha}-Multinomial-TS for multinomial distributions. We provide a novel lower bound on the CVaR regret which extends the concept of asymptotic optimality to CVaR bandits and prove that {\alpha}-Multinomial-TS is the first algorithm to achieve this lower bound. Finally, we demonstrate empirically the benefit of Thompson Sampling approaches over their UCB counterparts.