 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThompson Sampling for CVaR Bandits
Paper and Code


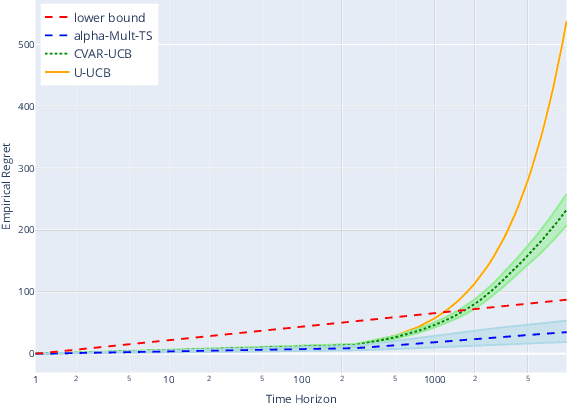
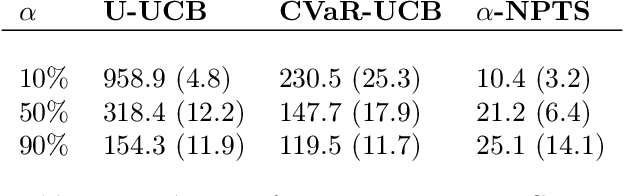
Risk awareness is an important feature to formulate a variety of real world problems. In this paper we study a multi-arm bandit problem in which the quality of each arm is measured by the Conditional Value at Risk (CVaR) at some level {\alpha} of the reward distribution. While existing works in this setting mainly focus on Upper Confidence Bound algorithms, we introduce the first Thompson Sampling approaches for CVaR bandits. Building on a recent work by Riou and Honda (2020), we propose {\alpha}-NPTS for bounded rewards and {\alpha}-Multinomial-TS for multinomial distributions. We provide a novel lower bound on the CVaR regret which extends the concept of asymptotic optimality to CVaR bandits and prove that {\alpha}-Multinomial-TS is the first algorithm to achieve this lower bound. Finally, we demonstrate empirically the benefit of Thompson Sampling approaches over their UCB counterparts.