 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproved learning rates in multi-unit uniform price auctions
Jan 17, 2025

Motivated by the strategic participation of electricity producers in electricity day-ahead market, we study the problem of online learning in repeated multi-unit uniform price auctions focusing on the adversarial opposing bid setting. The main contribution of this paper is the introduction of a new modeling of the bid space. Indeed, we prove that a learning algorithm leveraging the structure of this problem achieves a regret of $\tilde{O}(K^{4/3}T^{2/3})$ under bandit feedback, improving over the bound of $\tilde{O}(K^{7/4}T^{3/4})$ previously obtained in the literature. This improved regret rate is tight up to logarithmic terms. Inspired by electricity reserve markets, we further introduce a different feedback model under which all winning bids are revealed. This feedback interpolates between the full-information and bandit scenarios depending on the auctions' results. We prove that, under this feedback, the algorithm that we propose achieves regret $\tilde{O}(K^{5/2}\sqrt{T})$.
Distribution-Aware Mean Estimation under User-level Local Differential Privacy
Oct 12, 2024We consider the problem of mean estimation under user-level local differential privacy, where $n$ users are contributing through their local pool of data samples. Previous work assume that the number of data samples is the same across users. In contrast, we consider a more general and realistic scenario where each user $u \in [n]$ owns $m_u$ data samples drawn from some generative distribution $\mu$; $m_u$ being unknown to the statistician but drawn from a known distribution $M$ over $\mathbb{N}^\star$. Based on a distribution-aware mean estimation algorithm, we establish an $M$-dependent upper bounds on the worst-case risk over $\mu$ for the task of mean estimation. We then derive a lower bound. The two bounds are asymptotically matching up to logarithmic factors and reduce to known bounds when $m_u = m$ for any user $u$.
Constant or logarithmic regret in asynchronous multiplayer bandits
May 31, 2023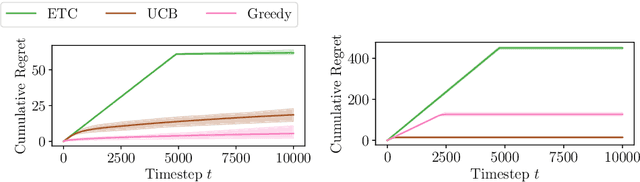
Multiplayer bandits have recently been extensively studied because of their application to cognitive radio networks. While the literature mostly considers synchronous players, radio networks (e.g. for IoT) tend to have asynchronous devices. This motivates the harder, asynchronous multiplayer bandits problem, which was first tackled with an explore-then-commit (ETC) algorithm (see Dakdouk, 2022), with a regret upper-bound in $\mathcal{O}(T^{\frac{2}{3}})$. Before even considering decentralization, understanding the centralized case was still a challenge as it was unknown whether getting a regret smaller than $\Omega(T^{\frac{2}{3}})$ was possible. We answer positively this question, as a natural extension of UCB exhibits a $\mathcal{O}(\sqrt{T\log(T)})$ minimax regret. More importantly, we introduce Cautious Greedy, a centralized algorithm that yields constant instance-dependent regret if the optimal policy assigns at least one player on each arm (a situation that is proved to occur when arm means are close enough). Otherwise, its regret increases as the sum of $\log(T)$ over some sub-optimality gaps. We provide lower bounds showing that Cautious Greedy is optimal in the data-dependent terms. Therefore, we set up a strong baseline for asynchronous multiplayer bandits and suggest that learning the optimal policy in this problem might be easier than thought, at least with centralization.
Static Scheduling with Predictions Learned through Efficient Exploration
May 31, 2022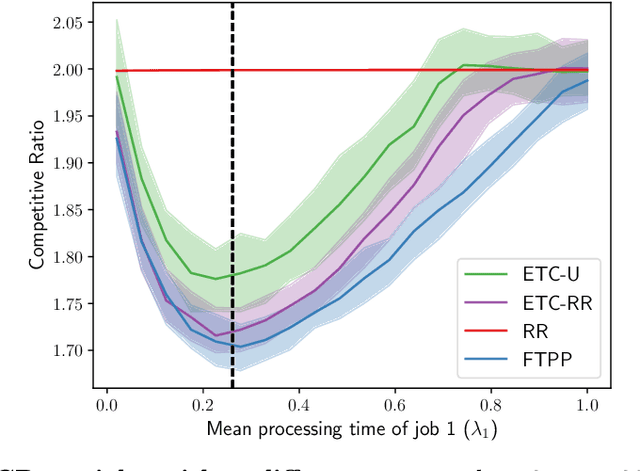
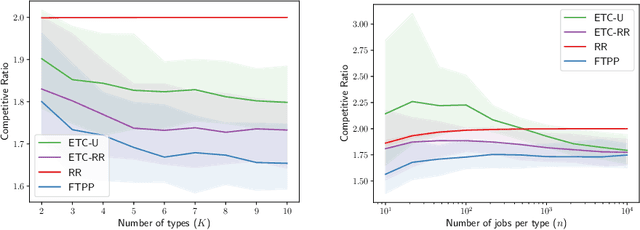
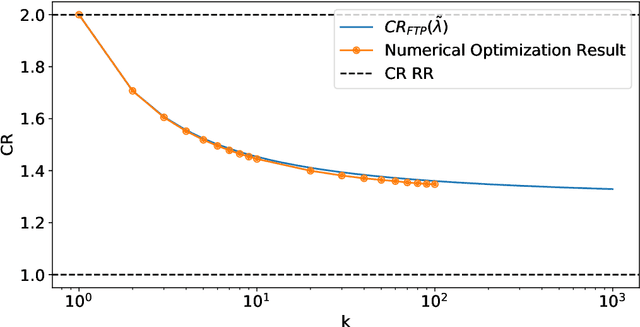
A popular approach to go beyond the worst-case analysis of online algorithms is to assume the existence of predictions that can be leveraged to improve performances. Those predictions are usually given by some external sources that cannot be fully trusted. Instead, we argue that trustful predictions can be built by algorithms, while they run. We investigate this idea in the illustrative context of static scheduling with exponential job sizes. Indeed, we prove that algorithms agnostic to this structure do not perform better than in the worst case. In contrast, when the expected job sizes are known, we show that the best algorithm using this information, called Follow-The-Perfect-Prediction (FTPP), exhibits much better performances. Then, we introduce two adaptive explore-then-commit types of algorithms: they both first (partially) learn expected job sizes and then follow FTPP once their self-predictions are confident enough. On the one hand, ETCU explores in "series", by completing jobs sequentially to acquire information. On the other hand, ETCRR, inspired by the optimal worst-case algorithm Round-Robin (RR), explores efficiently in "parallel". We prove that both of them asymptotically reach the performances of FTPP, with a faster rate for ETCRR. Those findings are empirically evaluated on synthetic data.
Shared Independent Component Analysis for Multi-Subject Neuroimaging
Oct 26, 2021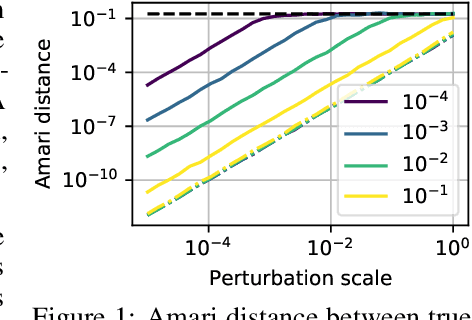
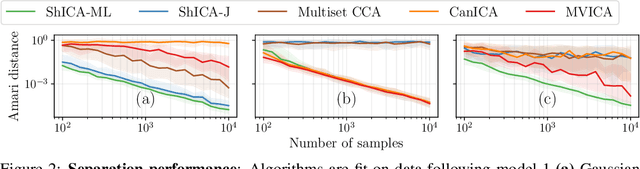
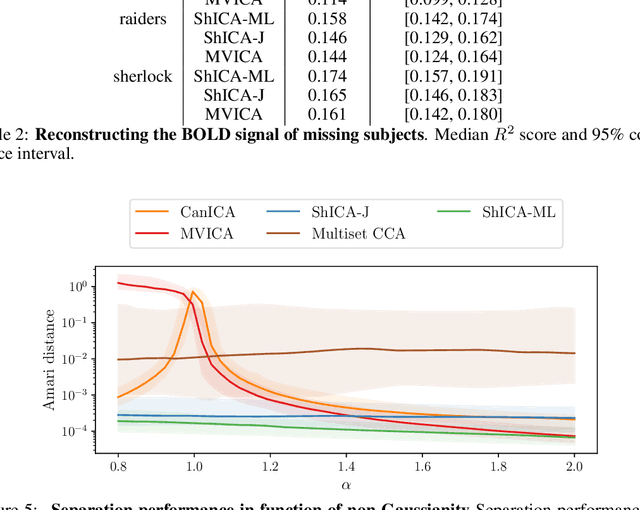
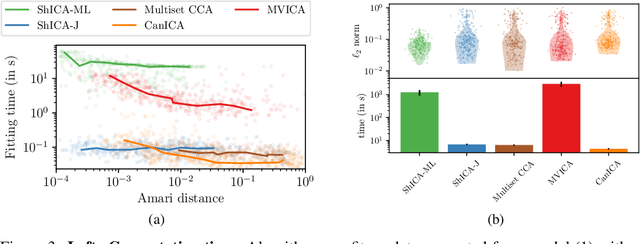
We consider shared response modeling, a multi-view learning problem where one wants to identify common components from multiple datasets or views. We introduce Shared Independent Component Analysis (ShICA) that models each view as a linear transform of shared independent components contaminated by additive Gaussian noise. We show that this model is identifiable if the components are either non-Gaussian or have enough diversity in noise variances. We then show that in some cases multi-set canonical correlation analysis can recover the correct unmixing matrices, but that even a small amount of sampling noise makes Multiset CCA fail. To solve this problem, we propose to use joint diagonalization after Multiset CCA, leading to a new approach called ShICA-J. We show via simulations that ShICA-J leads to improved results while being very fast to fit. While ShICA-J is based on second-order statistics, we further propose to leverage non-Gaussianity of the components using a maximum-likelihood method, ShICA-ML, that is both more accurate and more costly. Further, ShICA comes with a principled method for shared components estimation. Finally, we provide empirical evidence on fMRI and MEG datasets that ShICA yields more accurate estimation of the components than alternatives.
Functional Magnetic Resonance Imaging data augmentation through conditional ICA
Jul 14, 2021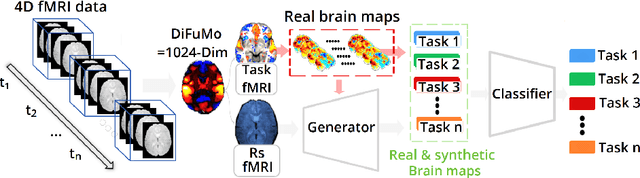
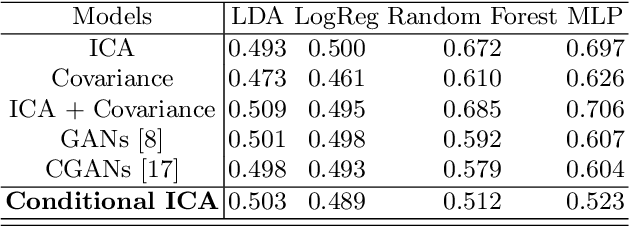
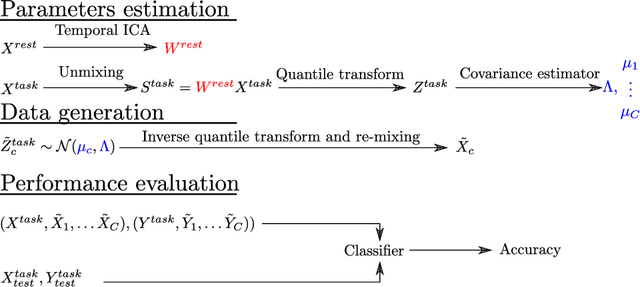
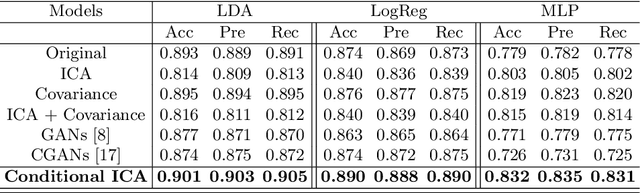
Advances in computational cognitive neuroimaging research are related to the availability of large amounts of labeled brain imaging data, but such data are scarce and expensive to generate. While powerful data generation mechanisms, such as Generative Adversarial Networks (GANs), have been designed in the last decade for computer vision, such improvements have not yet carried over to brain imaging. A likely reason is that GANs training is ill-suited to the noisy, high-dimensional and small-sample data available in functional neuroimaging. In this paper, we introduce Conditional Independent Components Analysis (Conditional ICA): a fast functional Magnetic Resonance Imaging (fMRI) data augmentation technique, that leverages abundant resting-state data to create images by sampling from an ICA decomposition. We then propose a mechanism to condition the generator on classes observed with few samples. We first show that the generative mechanism is successful at synthesizing data indistinguishable from observations, and that it yields gains in classification accuracy in brain decoding problems. In particular it outperforms GANs while being much easier to optimize and interpret. Lastly, Conditional ICA enhances classification accuracy in eight datasets without further parameters tuning.
Adaptive Multi-View ICA: Estimation of noise levels for optimal inference
Feb 22, 2021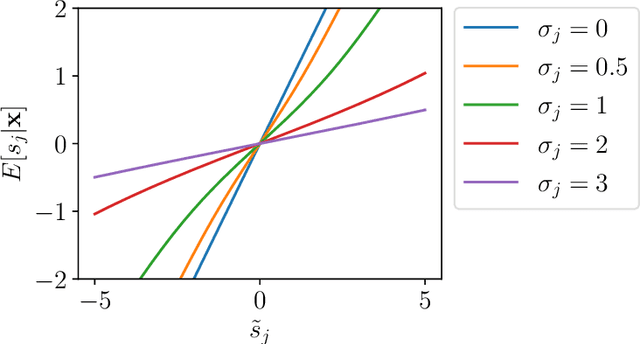
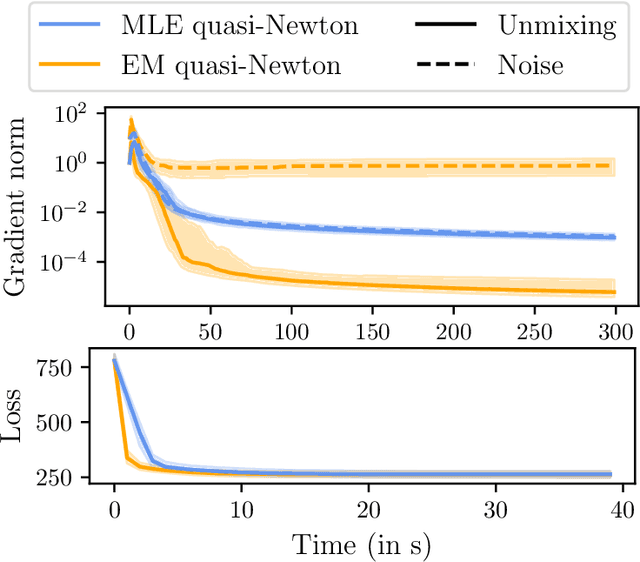
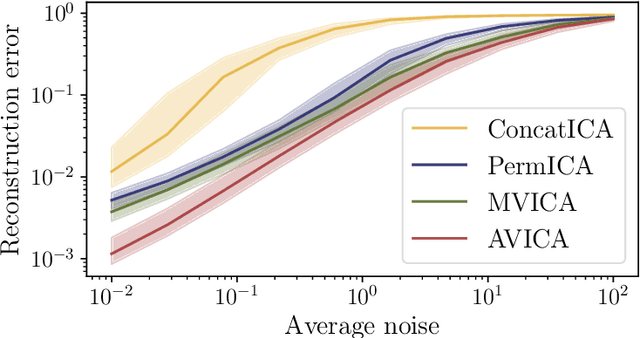
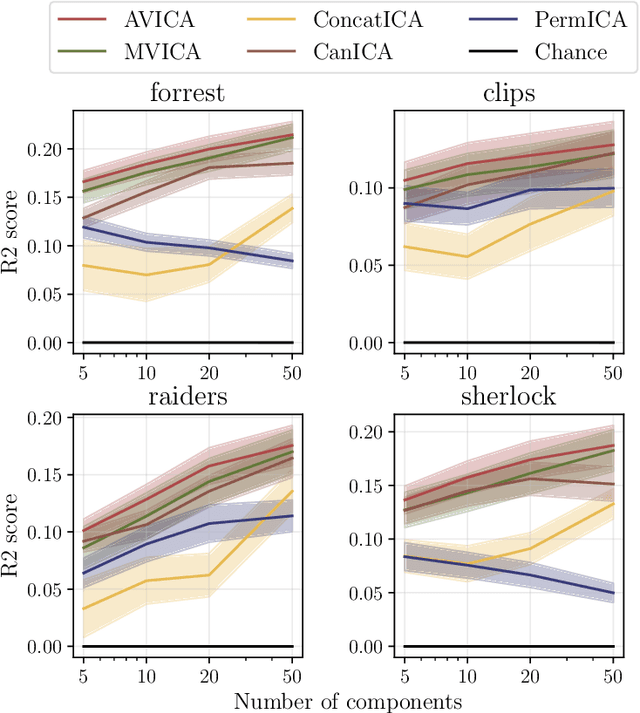
We consider a multi-view learning problem known as group independent component analysis (group ICA), where the goal is to recover shared independent sources from many views. The statistical modeling of this problem requires to take noise into account. When the model includes additive noise on the observations, the likelihood is intractable. By contrast, we propose Adaptive multiView ICA (AVICA), a noisy ICA model where each view is a linear mixture of shared independent sources with additive noise on the sources. In this setting, the likelihood has a tractable expression, which enables either direct optimization of the log-likelihood using a quasi-Newton method, or generalized EM. Importantly, we consider that the noise levels are also parameters that are learned from the data. This enables sources estimation with a closed-form Minimum Mean Squared Error (MMSE) estimator which weights each view according to its relative noise level. On synthetic data, AVICA yields better sources estimates than other group ICA methods thanks to its explicit MMSE estimator. On real magnetoencephalograpy (MEG) data, we provide evidence that the decomposition is less sensitive to sampling noise and that the noise variance estimates are biologically plausible. Lastly, on functional magnetic resonance imaging (fMRI) data, AVICA exhibits best performance in transferring information across views.
Modeling Shared Responses in Neuroimaging Studies through MultiView ICA
Jun 12, 2020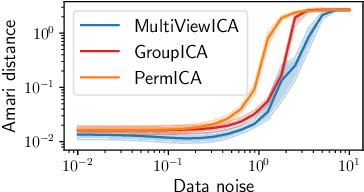
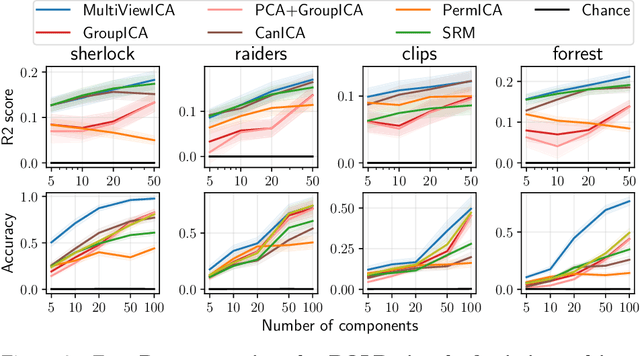
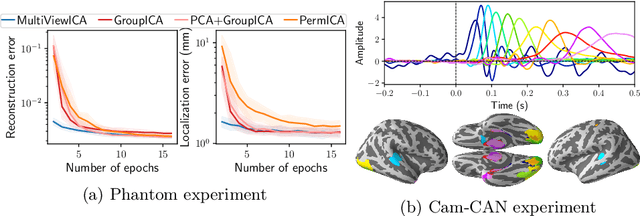
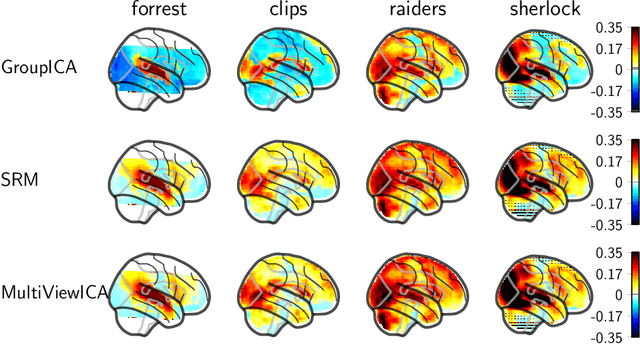
Group studies involving large cohorts of subjects are important to draw general conclusions about brain functional organization. However, the aggregation of data coming from multiple subjects is challenging, since it requires accounting for large variability in anatomy, functional topography and stimulus response across individuals. Data modeling is especially hard for ecologically relevant conditions such as movie watching, where the experimental setup does not imply well-defined cognitive operations. We propose a novel MultiView Independent Component Analysis (ICA) model for group studies, where data from each subject are modeled as a linear combination of shared independent sources plus noise. Contrary to most group-ICA procedures, the likelihood of the model is available in closed form. We develop an alternate quasi-Newton method for maximizing the likelihood, which is robust and converges quickly. We demonstrate the usefulness of our approach first on fMRI data, where our model demonstrates improved sensitivity in identifying common sources among subjects. Moreover, the sources recovered by our model exhibit lower between-session variability than other methods.On magnetoencephalography (MEG) data, our method yields more accurate source localization on phantom data. Applied on 200 subjects from the Cam-CAN dataset it reveals a clear sequence of evoked activity in sensor and source space. The code is freely available at https://github.com/hugorichard/multiviewica.
Fast shared response model for fMRI data
Sep 27, 2019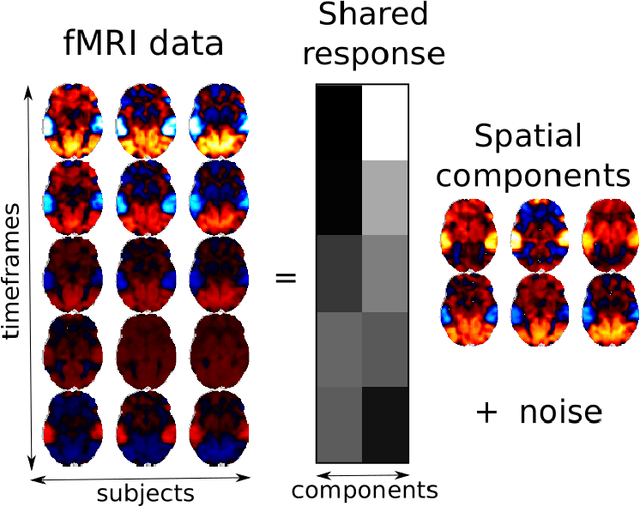
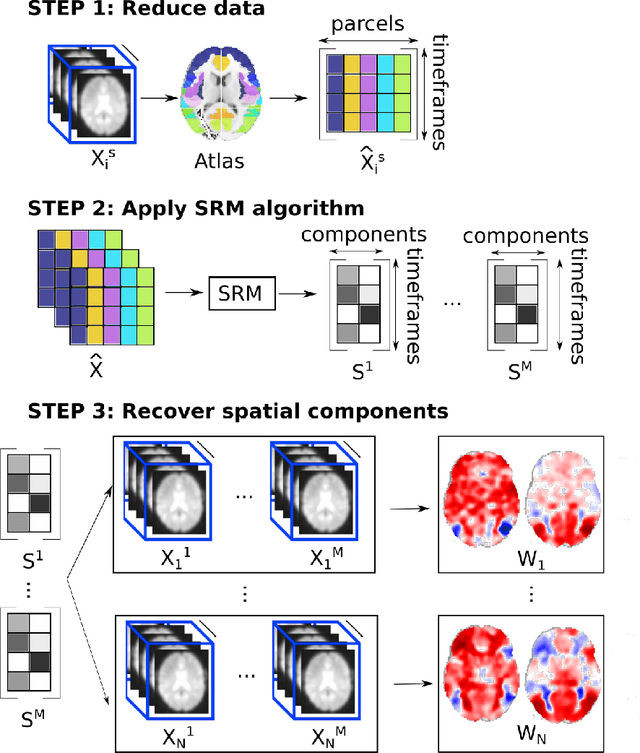
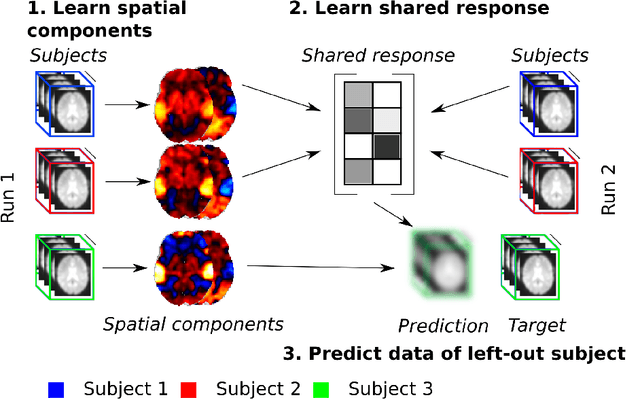
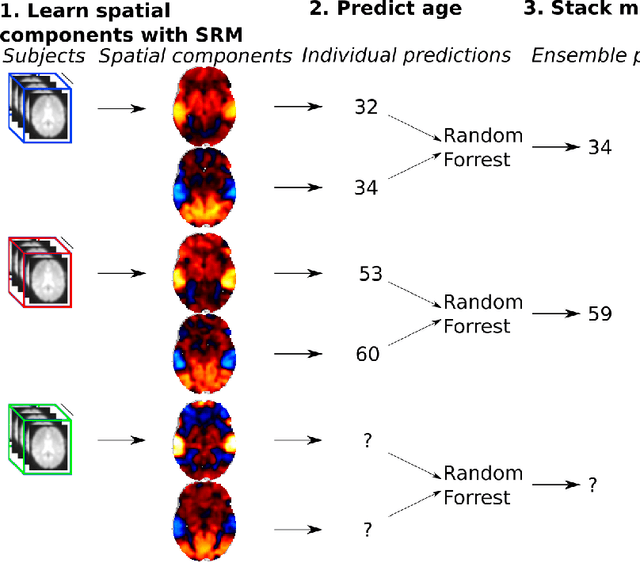
The shared response model provides a simple but effective framework toanalyse fMRI data of subjects exposed to naturalistic stimuli. However whenthe number of subjects or runs is large, fitting the model requires a large amountof memory and computational power, which limits its use in practice. In thiswork, we introduce the FastSRM algorithm that relies on an intermediate atlas-based representation. It provides considerable speed-up in time and memoryusage, hence it allows easy and fast large-scale analysis of naturalistic-stimulusfMRI data. Using four different datasets, we show that our method outperformsthe original SRM algorithm while being about 5x faster and 20x to 40x morememory efficient. Based on this contribution, we use FastSRM to predict agefrom movie watching data on the CamCAN sample. Besides delivering accuratepredictions (mean absolute error of 7.5 years), FastSRM extracts topographicpatterns that are predictive of age, demonstrating that brain activity duringfree perception reflects age.
Optimizing deep video representation to match brain activity
Sep 07, 2018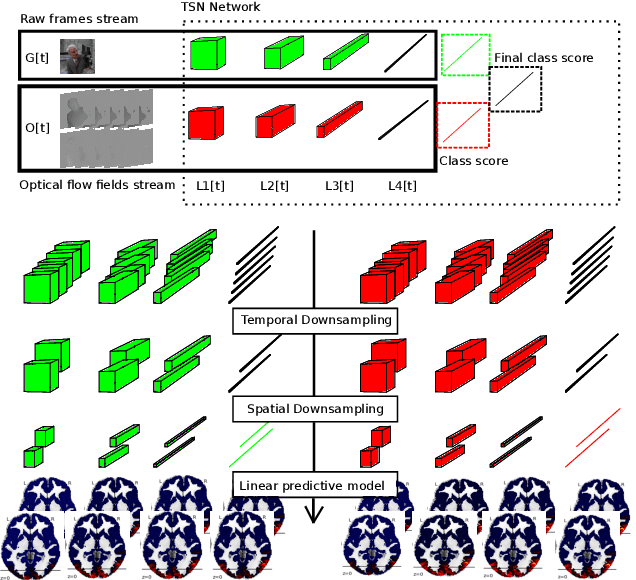
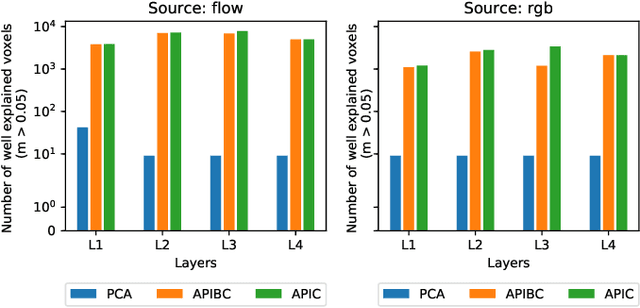
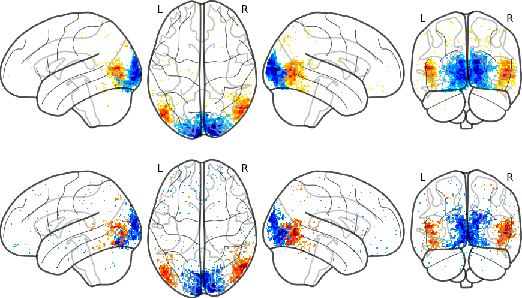
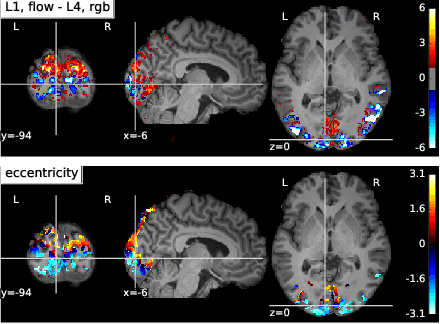
The comparison of observed brain activity with the statistics generated by artificial intelligence systems is useful to probe brain functional organization under ecological conditions. Here we study fMRI activity in ten subjects watching color natural movies and compute deep representations of these movies with an architecture that relies on optical flow and image content. The association of activity in visual areas with the different layers of the deep architecture displays complexity-related contrasts across visual areas and reveals a striking foveal/peripheral dichotomy.