 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStatic Scheduling with Predictions Learned through Efficient Exploration
May 31, 2022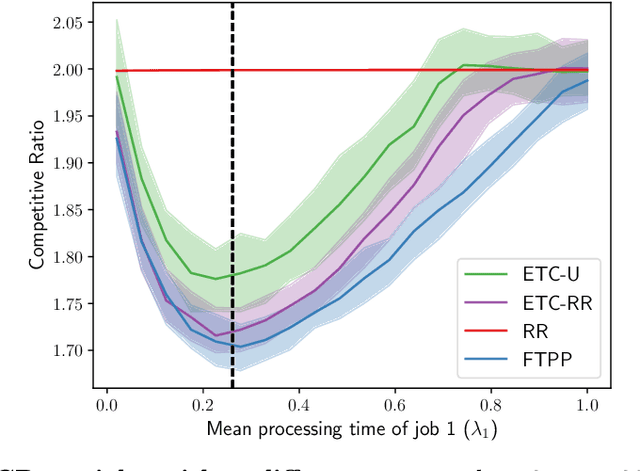
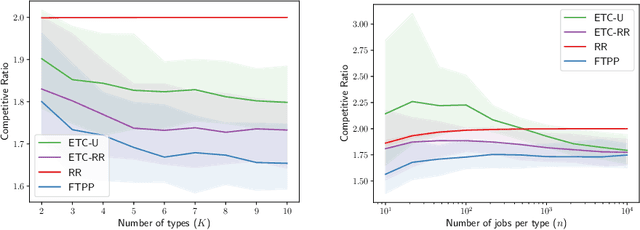
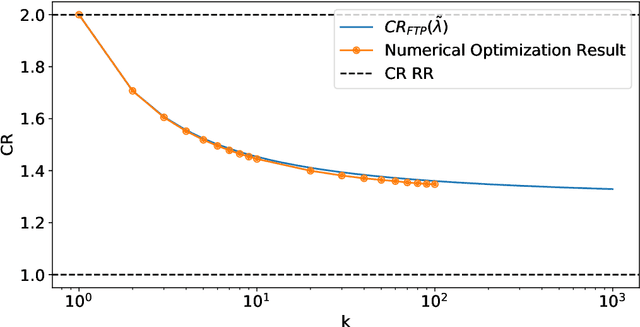
A popular approach to go beyond the worst-case analysis of online algorithms is to assume the existence of predictions that can be leveraged to improve performances. Those predictions are usually given by some external sources that cannot be fully trusted. Instead, we argue that trustful predictions can be built by algorithms, while they run. We investigate this idea in the illustrative context of static scheduling with exponential job sizes. Indeed, we prove that algorithms agnostic to this structure do not perform better than in the worst case. In contrast, when the expected job sizes are known, we show that the best algorithm using this information, called Follow-The-Perfect-Prediction (FTPP), exhibits much better performances. Then, we introduce two adaptive explore-then-commit types of algorithms: they both first (partially) learn expected job sizes and then follow FTPP once their self-predictions are confident enough. On the one hand, ETCU explores in "series", by completing jobs sequentially to acquire information. On the other hand, ETCRR, inspired by the optimal worst-case algorithm Round-Robin (RR), explores efficiently in "parallel". We prove that both of them asymptotically reach the performances of FTPP, with a faster rate for ETCRR. Those findings are empirically evaluated on synthetic data.