 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnline selective conformal inference: adaptive scores, convergence rate and optimality
Aug 14, 2025In a supervised online setting, quantifying uncertainty has been proposed in the seminal work of \cite{gibbs2021adaptive}. For any given point-prediction algorithm, their method (ACI) produces a conformal prediction set with an average missed coverage getting close to a pre-specified level $\alpha$ for a long time horizon. We introduce an extended version of this algorithm, called OnlineSCI, allowing the user to additionally select times where such an inference should be made. OnlineSCI encompasses several prominent online selective tasks, such as building prediction intervals for extreme outcomes, classification with abstention, and online testing. While OnlineSCI controls the average missed coverage on the selected in an adversarial setting, our theoretical results also show that it controls the instantaneous error rate (IER) at the selected times, up to a non-asymptotical remainder term. Importantly, our theory covers the case where OnlineSCI updates the point-prediction algorithm at each time step, a property which we refer to as {\it adaptive} capability. We show that the adaptive versions of OnlineSCI can convergence to an optimal solution and provide an explicit convergence rate in each of the aforementioned application cases, under specific mild conditions. Finally, the favorable behavior of OnlineSCI in practice is illustrated by numerical experiments.
Powerful batch conformal prediction for classification
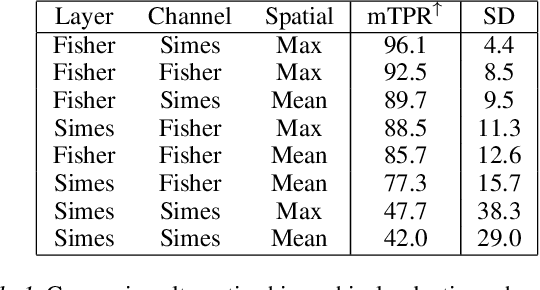
Nov 04, 2024In a supervised classification split conformal/inductive framework with $K$ classes, a calibration sample of $n$ labeled examples is observed for inference on the label of a new unlabeled example. In this work, we explore the case where a "batch" of $m$ independent such unlabeled examples is given, and a multivariate prediction set with $1-\alpha$ coverage should be provided for this batch. Hence, the batch prediction set takes the form of a collection of label vectors of size $m$, while the calibration sample only contains univariate labels. Using the Bonferroni correction consists in concatenating the individual prediction sets at level $1-\alpha/m$ (Vovk 2013). We propose a uniformly more powerful solution, based on specific combinations of conformal $p$-values that exploit the Simes inequality (Simes 1986). Intuitively, the pooled evidence of fairly "easy" examples of the batch can help provide narrower batch prediction sets. We also introduced adaptive versions of the novel procedure that are particularly effective when the batch prediction set is expected to be large. The theoretical guarantees are provided when all examples are iid, as well as more generally when iid is assumed only conditionally within each class. In particular, our results are also valid under a label distribution shift since the distribution of the labels need not be the same in the calibration sample and in the new `batch'. The usefulness of the method is illustrated on synthetic and real data examples.
Selecting informative conformal prediction sets with false coverage rate control
Mar 18, 2024In supervised learning, including regression and classification, conformal methods provide prediction sets for the outcome/label with finite sample coverage for any machine learning predictors. We consider here the case where such prediction sets come after a selection process. The selection process requires that the selected prediction sets be `informative' in a well defined sense. We consider both the classification and regression settings where the analyst may consider as informative only the sample with prediction label sets or prediction intervals small enough, excluding null values, or obeying other appropriate `monotone' constraints. While this covers many settings of possible interest in various applications, we develop a unified framework for building such informative conformal prediction sets while controlling the false coverage rate (FCR) on the selected sample. While conformal prediction sets after selection have been the focus of much recent literature in the field, the new introduced procedures, called InfoSP and InfoSCOP, are to our knowledge the first ones providing FCR control for informative prediction sets. We show the usefulness of our resulting procedures on real and simulated data.
Statistical Testing for Efficient Out of Distribution Detection in Deep Neural Networks
Feb 25, 2021


Commonly, Deep Neural Networks (DNNs) generalize well on samples drawn from a distribution similar to that of the training set. However, DNNs' predictions are brittle and unreliable when the test samples are drawn from a dissimilar distribution. This presents a major concern for deployment in real-world applications, where such behavior may come at a great cost -- as in the case of autonomous vehicles or healthcare applications. This paper frames the Out Of Distribution (OOD) detection problem in DNN as a statistical hypothesis testing problem. Unlike previous OOD detection heuristics, our framework is guaranteed to maintain the false positive rate (detecting OOD as in-distribution) for test data. We build on this framework to suggest a novel OOD procedure based on low-order statistics. Our method achieves comparable or better than state-of-the-art results on well-accepted OOD benchmarks without retraining the network parameters -- and at a fraction of the computational cost.