 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConformal novelty detection with false discovery rate control at the boundary
Jan 06, 2026Conformal novelty detection is a classical machine learning task for which uncertainty quantification is essential for providing reliable results. Recent work has shown that the BH procedure applied to conformal p-values controls the false discovery rate (FDR). Unfortunately, the BH procedure can lead to over-optimistic assessments near the rejection threshold, with an increase of false discoveries at the margin as pointed out by Soloff et al. (2024). This issue is solved therein by the support line (SL) correction, which is proven to control the boundary false discovery rate (bFDR) in the independent, non-conformal setting. The present work extends the SL method to the conformal setting: first, we show that the SL procedure can violate the bFDR control in this specific setting. Second, we propose several alternatives that provably control the bFDR in the conformal setting. Finally, numerical experiments with both synthetic and real data support our theoretical findings and show the relevance of the new proposed procedures.
Online selective conformal inference: adaptive scores, convergence rate and optimality
Aug 14, 2025In a supervised online setting, quantifying uncertainty has been proposed in the seminal work of \cite{gibbs2021adaptive}. For any given point-prediction algorithm, their method (ACI) produces a conformal prediction set with an average missed coverage getting close to a pre-specified level $\alpha$ for a long time horizon. We introduce an extended version of this algorithm, called OnlineSCI, allowing the user to additionally select times where such an inference should be made. OnlineSCI encompasses several prominent online selective tasks, such as building prediction intervals for extreme outcomes, classification with abstention, and online testing. While OnlineSCI controls the average missed coverage on the selected in an adversarial setting, our theoretical results also show that it controls the instantaneous error rate (IER) at the selected times, up to a non-asymptotical remainder term. Importantly, our theory covers the case where OnlineSCI updates the point-prediction algorithm at each time step, a property which we refer to as {\it adaptive} capability. We show that the adaptive versions of OnlineSCI can convergence to an optimal solution and provide an explicit convergence rate in each of the aforementioned application cases, under specific mild conditions. Finally, the favorable behavior of OnlineSCI in practice is illustrated by numerical experiments.
Powerful batch conformal prediction for classification
Nov 04, 2024In a supervised classification split conformal/inductive framework with $K$ classes, a calibration sample of $n$ labeled examples is observed for inference on the label of a new unlabeled example. In this work, we explore the case where a "batch" of $m$ independent such unlabeled examples is given, and a multivariate prediction set with $1-\alpha$ coverage should be provided for this batch. Hence, the batch prediction set takes the form of a collection of label vectors of size $m$, while the calibration sample only contains univariate labels. Using the Bonferroni correction consists in concatenating the individual prediction sets at level $1-\alpha/m$ (Vovk 2013). We propose a uniformly more powerful solution, based on specific combinations of conformal $p$-values that exploit the Simes inequality (Simes 1986). Intuitively, the pooled evidence of fairly "easy" examples of the batch can help provide narrower batch prediction sets. We also introduced adaptive versions of the novel procedure that are particularly effective when the batch prediction set is expected to be large. The theoretical guarantees are provided when all examples are iid, as well as more generally when iid is assumed only conditionally within each class. In particular, our results are also valid under a label distribution shift since the distribution of the labels need not be the same in the calibration sample and in the new `batch'. The usefulness of the method is illustrated on synthetic and real data examples.
Selecting informative conformal prediction sets with false coverage rate control
Mar 18, 2024In supervised learning, including regression and classification, conformal methods provide prediction sets for the outcome/label with finite sample coverage for any machine learning predictors. We consider here the case where such prediction sets come after a selection process. The selection process requires that the selected prediction sets be `informative' in a well defined sense. We consider both the classification and regression settings where the analyst may consider as informative only the sample with prediction label sets or prediction intervals small enough, excluding null values, or obeying other appropriate `monotone' constraints. While this covers many settings of possible interest in various applications, we develop a unified framework for building such informative conformal prediction sets while controlling the false coverage rate (FCR) on the selected sample. While conformal prediction sets after selection have been the focus of much recent literature in the field, the new introduced procedures, called InfoSP and InfoSCOP, are to our knowledge the first ones providing FCR control for informative prediction sets. We show the usefulness of our resulting procedures on real and simulated data.
Transductive conformal inference with adaptive scores
Oct 27, 2023Conformal inference is a fundamental and versatile tool that provides distribution-free guarantees for many machine learning tasks. We consider the transductive setting, where decisions are made on a test sample of $m$ new points, giving rise to $m$ conformal $p$-values. {While classical results only concern their marginal distribution, we show that their joint distribution follows a P\'olya urn model, and establish a concentration inequality for their empirical distribution function.} The results hold for arbitrary exchangeable scores, including {\it adaptive} ones that can use the covariates of the test+calibration samples at training stage for increased accuracy. We demonstrate the usefulness of these theoretical results through uniform, in-probability guarantees for two machine learning tasks of current interest: interval prediction for transductive transfer learning and novelty detection based on two-class classification.
Machine learning meets false discovery rate
Aug 13, 2022
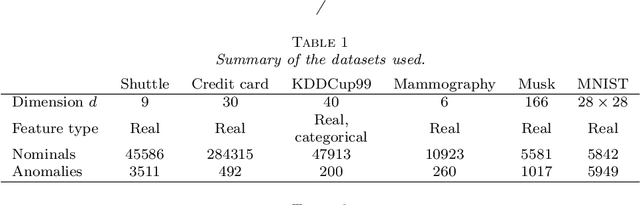
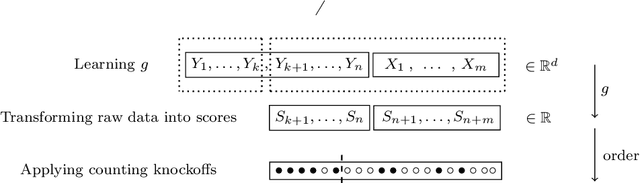

Classical false discovery rate (FDR) controlling procedures offer strong and interpretable guarantees, while they often lack of flexibility. On the other hand, recent machine learning classification algorithms, as those based on random forests (RF) or neural networks (NN), have great practical performances but lack of interpretation and of theoretical guarantees. In this paper, we make these two meet by introducing a new adaptive novelty detection procedure with FDR control, called AdaDetect. It extends the scope of recent works of multiple testing literature to the high dimensional setting, notably the one in Yang et al. (2021). AdaDetect is shown to both control strongly the FDR and to have a power that mimics the one of the oracle in a specific sense. The interest and validity of our approach is demonstrated with theoretical results, numerical experiments on several benchmark datasets and with an application to astrophysical data. In particular, while AdaDetect can be used in combination with any classifier, it is particularly efficient on real-world datasets with RF, and on images with NN.
False clustering rate control in mixture models
Mar 08, 2022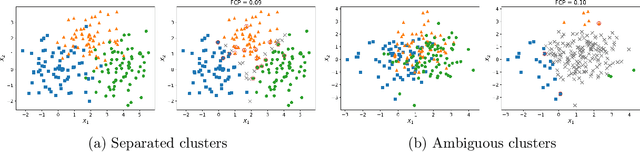
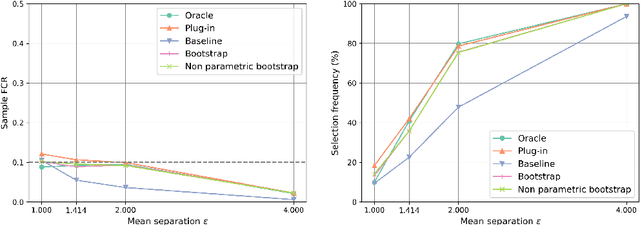
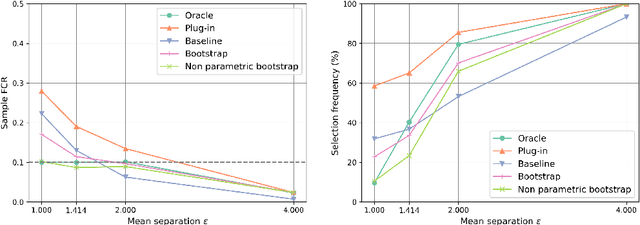
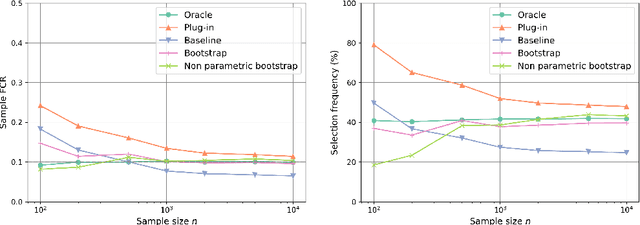
The clustering task consists in delivering labels to the members of a sample. For most data sets, some individuals are ambiguous and intrinsically difficult to attribute to one or another cluster. However, in practical applications, misclassifying individuals is potentially disastrous. To overcome this difficulty, the idea followed here is to classify only a part of the sample in order to obtain a small misclassification rate. This approach is well known in the supervised setting, and referred to as classification with an abstention option. The purpose of this paper is to revisit this approach in an unsupervised mixture-model framework. The problem is formalized in terms of controlling the false clustering rate (FCR) below a prescribed level {\alpha}, while maximizing the number of classified items. New procedures are introduced and their behavior is shown to be close to the optimal one by establishing theoretical results and conducting numerical experiments. An application to breast cancer data illustrates the benefits of the new approach from a practical viewpoint.