 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptiVocab: Enhancing LLM Efficiency in Focused Domains through Lightweight Vocabulary Adaptation
Mar 25, 2025
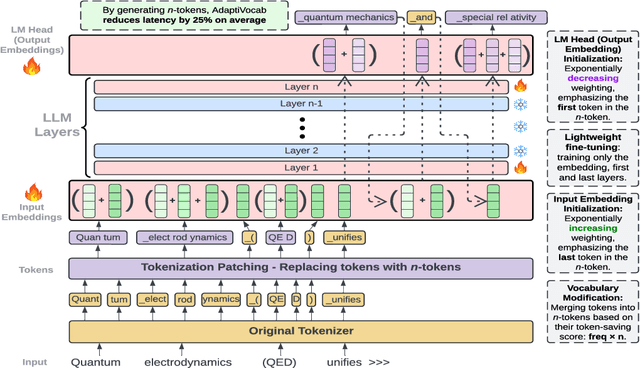
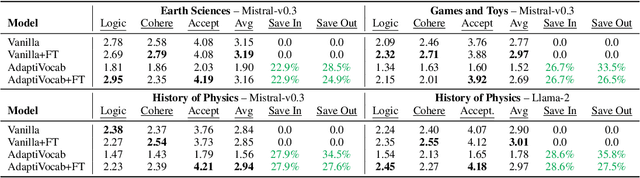
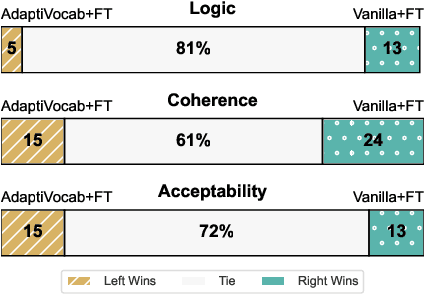
Large Language Models (LLMs) have shown impressive versatility as general purpose models. However, their broad applicability comes at a high-cost computational overhead, particularly in auto-regressive decoding where each step requires a forward pass. In domain-specific settings, general-purpose capabilities are unnecessary and can be exchanged for efficiency. In this work, we take a novel perspective on domain adaptation, reducing latency and computational costs by adapting the vocabulary to focused domains of interest. We introduce AdaptiVocab, an end-to-end approach for vocabulary adaptation, designed to enhance LLM efficiency in low-resource domains. AdaptiVocab can be applied to any tokenizer and architecture, modifying the vocabulary by replacing tokens with domain-specific n-gram-based tokens, thereby reducing the number of tokens required for both input processing and output generation. AdaptiVocab initializes new n-token embeddings using an exponentially weighted combination of existing embeddings and employs a lightweight fine-tuning phase that can be efficiently performed on a single GPU. We evaluate two 7B LLMs across three niche domains, assessing efficiency, generation quality, and end-task performance. Our results show that AdaptiVocab reduces token usage by over 25% without compromising performance
Inside-Out: Hidden Factual Knowledge in LLMs
Mar 19, 2025This work presents a framework for assessing whether large language models (LLMs) encode more factual knowledge in their parameters than what they express in their outputs. While a few studies hint at this possibility, none has clearly defined or demonstrated this phenomenon. We first propose a formal definition of knowledge, quantifying it for a given question as the fraction of correct-incorrect answer pairs where the correct one is ranked higher. This gives rise to external and internal knowledge, depending on the information used to score individual answer candidates: either the model's observable token-level probabilities or its intermediate computations. Hidden knowledge arises when internal knowledge exceeds external knowledge. We then present a case study, applying this framework to three popular open-weights LLMs in a closed-book QA setup. Our results indicate that: (1) LLMs consistently encode more factual knowledge internally than what they express externally, with an average gap of 40%. (2) Surprisingly, some knowledge is so deeply hidden that a model can internally know an answer perfectly, yet fail to generate it even once, despite large-scale repeated sampling of 1,000 answers. This reveals fundamental limitations in the generation capabilities of LLMs, which (3) puts a practical constraint on scaling test-time compute via repeated answer sampling in closed-book QA: significant performance improvements remain inaccessible because some answers are practically never sampled, yet if they were, we would be guaranteed to rank them first.