 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePairwise Margin Maximization for Deep Neural Networks
Oct 09, 2021
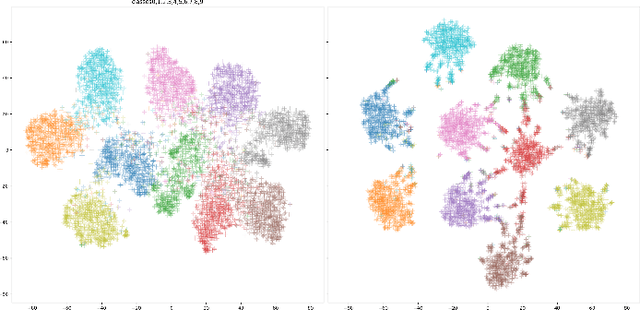
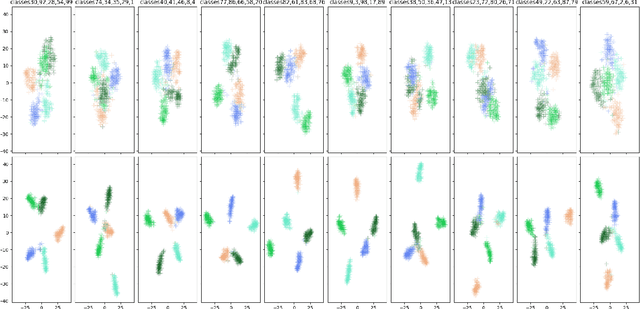
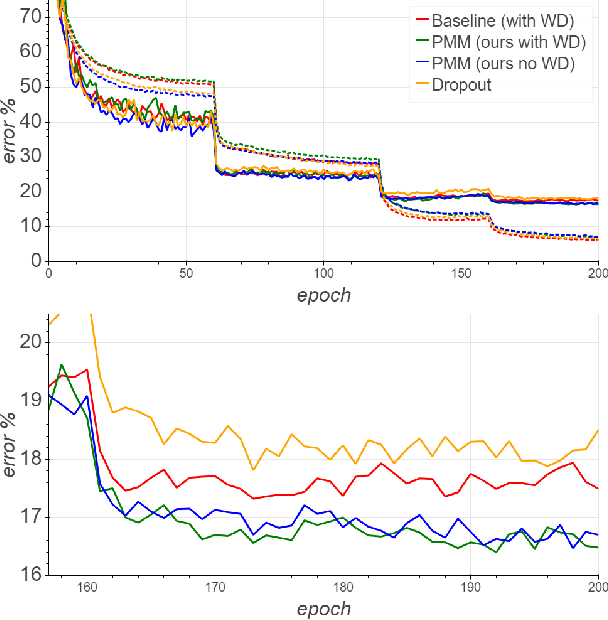
The weight decay regularization term is widely used during training to constrain expressivity, avoid overfitting, and improve generalization. Historically, this concept was borrowed from the SVM maximum margin principle and extended to multi-class deep networks. Carefully inspecting this principle reveals that it is not optimal for multi-class classification in general, and in particular when using deep neural networks. In this paper, we explain why this commonly used principle is not optimal and propose a new regularization scheme, called {\em Pairwise Margin Maximization} (PMM), which measures the minimal amount of displacement an instance should take until its predicted classification is switched. In deep neural networks, PMM can be implemented in the vector space before the network's output layer, i.e., in the deep feature space, where we add an additional normalization term to avoid convergence to a trivial solution. We demonstrate empirically a substantial improvement when training a deep neural network with PMM compared to the standard regularization terms.
Margin-Based Regularization and Selective Sampling in Deep Neural Networks
Sep 13, 2020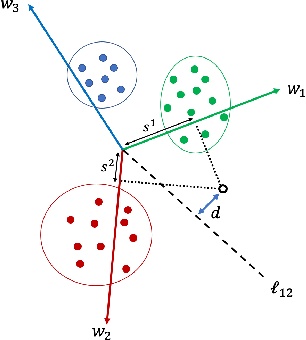
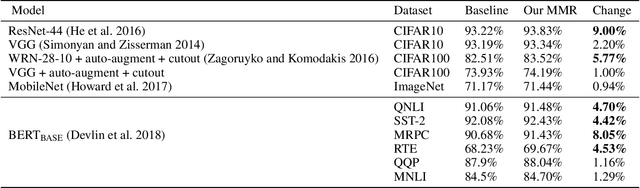
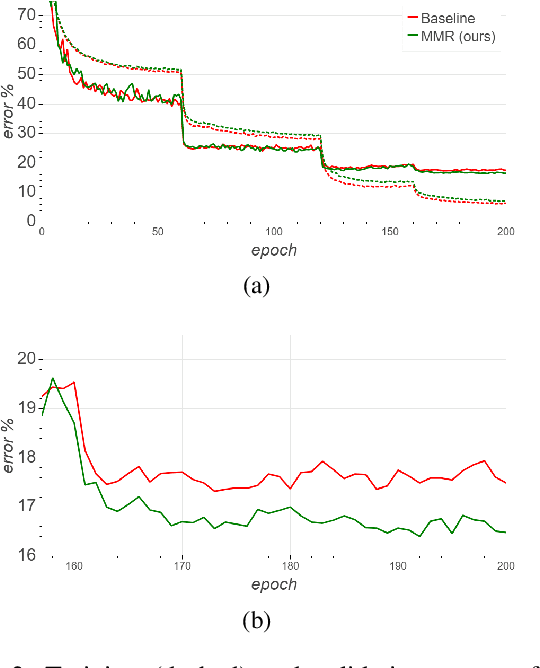
We derive a new margin-based regularization formulation, termed multi-margin regularization (MMR), for deep neural networks (DNNs). The MMR is inspired by principles that were applied in margin analysis of shallow linear classifiers, e.g., support vector machine (SVM). Unlike SVM, MMR is continuously scaled by the radius of the bounding sphere (i.e., the maximal norm of the feature vector in the data), which is constantly changing during training. We empirically demonstrate that by a simple supplement to the loss function, our method achieves better results on various classification tasks across domains. Using the same concept, we also derive a selective sampling scheme and demonstrate accelerated training of DNNs by selecting samples according to a minimal margin score (MMS). This score measures the minimal amount of displacement an input should undergo until its predicted classification is switched. We evaluate our proposed methods on three image classification tasks and six language text classification tasks. Specifically, we show improved empirical results on CIFAR10, CIFAR100 and ImageNet using state-of-the-art convolutional neural networks (CNNs) and BERT-BASE architecture for the MNLI, QQP, QNLI, MRPC, SST-2 and RTE benchmarks.
Selective sampling for accelerating training of deep neural networks
Nov 16, 2019
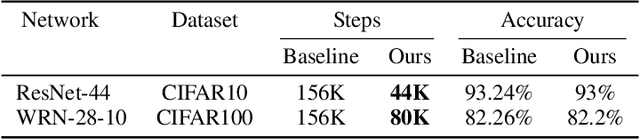
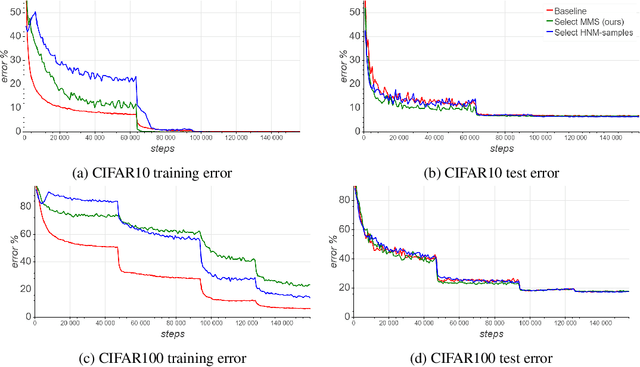
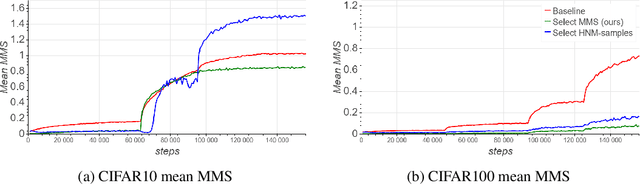
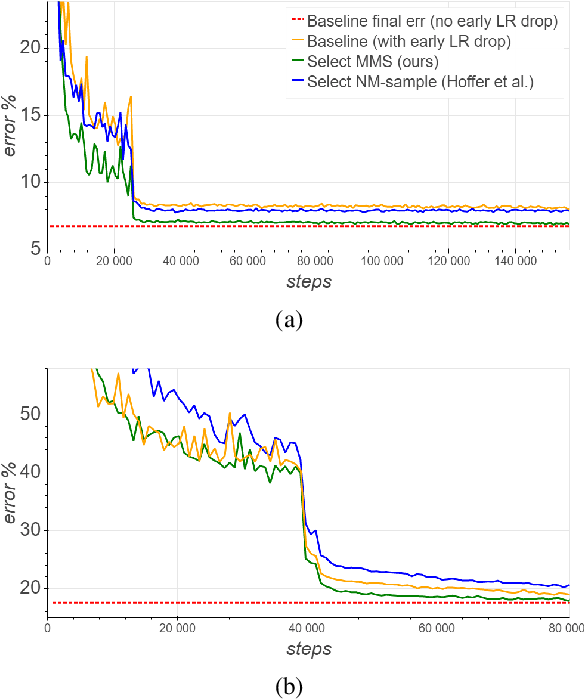
We present a selective sampling method designed to accelerate the training of deep neural networks. To this end, we introduce a novel measurement, the minimal margin score (MMS), which measures the minimal amount of displacement an input should take until its predicted classification is switched. For multi-class linear classification, the MMS measure is a natural generalization of the margin-based selection criterion, which was thoroughly studied in the binary classification setting. In addition, the MMS measure provides an interesting insight into the progress of the training process and can be useful for designing and monitoring new training regimes. Empirically we demonstrate a substantial acceleration when training commonly used deep neural network architectures for popular image classification tasks. The efficiency of our method is compared against the standard training procedures, and against commonly used selective sampling alternatives: Hard negative mining selection, and Entropy-based selection. Finally, we demonstrate an additional speedup when we adopt a more aggressive learning drop regime while using the MMS selective sampling method.
Mix & Match: training convnets with mixed image sizes for improved accuracy, speed and scale resiliency
Aug 12, 2019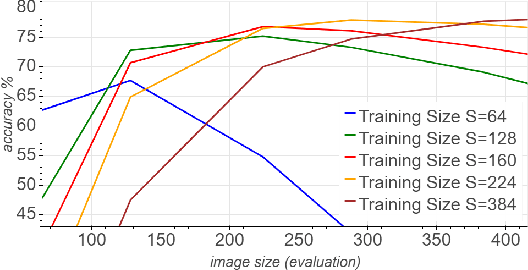
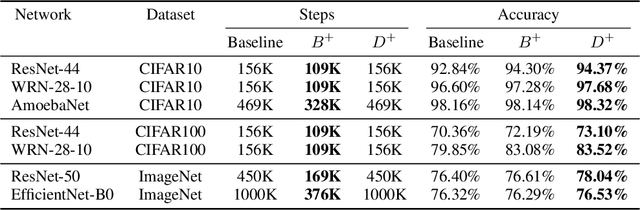
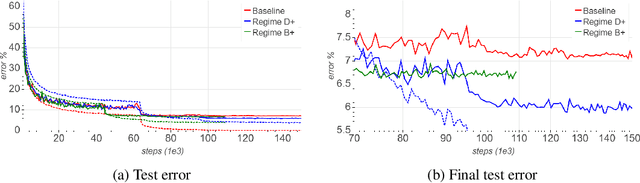
Convolutional neural networks (CNNs) are commonly trained using a fixed spatial image size predetermined for a given model. Although trained on images of aspecific size, it is well established that CNNs can be used to evaluate a wide range of image sizes at test time, by adjusting the size of intermediate feature maps. In this work, we describe and evaluate a novel mixed-size training regime that mixes several image sizes at training time. We demonstrate that models trained using our method are more resilient to image size changes and generalize well even on small images. This allows faster inference by using smaller images attest time. For instance, we receive a 76.43% top-1 accuracy using ResNet50 with an image size of 160, which matches the accuracy of the baseline model with 2x fewer computations. Furthermore, for a given image size used at test time, we show this method can be exploited either to accelerate training or the final test accuracy. For example, we are able to reach a 79.27% accuracy with a model evaluated at a 288 spatial size for a relative improvement of 14% over the baseline.